Have you ever faced the challenge of needing to recreate a Kafka Connector while preserving its offset position? If so, we have fantastic news for you!
Picture this: your Kafka Connect cluster is perfectly set up, your connectors are finely tuned, and everything is running smoothly. Suddenly, you need to recreate one of your connectors. The thought of losing all the offset information is daunting—nobody wants to risk data duplication or loss.
But worry no more, because Red Hat AMQ Streams 2.6 on Red Hat OpenShift (based on Apache Kafka 3.6.0 and Strimzi 0.38.x) has introduced a revolutionary feature: first-class offsets support with KIP-875. This new feature includes REST API endpoints specifically designed for managing connector offsets, making it seamless to preserve your offset positions when recreating connectors.
The following table summarizes the key REST API actions you can use to manage connector offsets effectively:
| Action | Description |
|---|---|
GET /connectors/{connector}/offsets | Retrieve the offsets for a connector; the connector must exist |
PATCH /connectors/{connector}/offsets | Alter the offsets for a connector; the connector must exist, and must be in the STOPPED state |
DELETE /connectors/{connector}/offsets | Reset the offsets for a connector; the connector must exist, and must be in the STOPPED state |
To illustrate, imagine you need to create a new Kafka Connector with a different name but want it to start from the same offset position as the old one. With the new feature in Kafka 3.6, you can effortlessly transfer offsets from the old connector to the new one, ensuring continuity and data integrity (Figure 1).
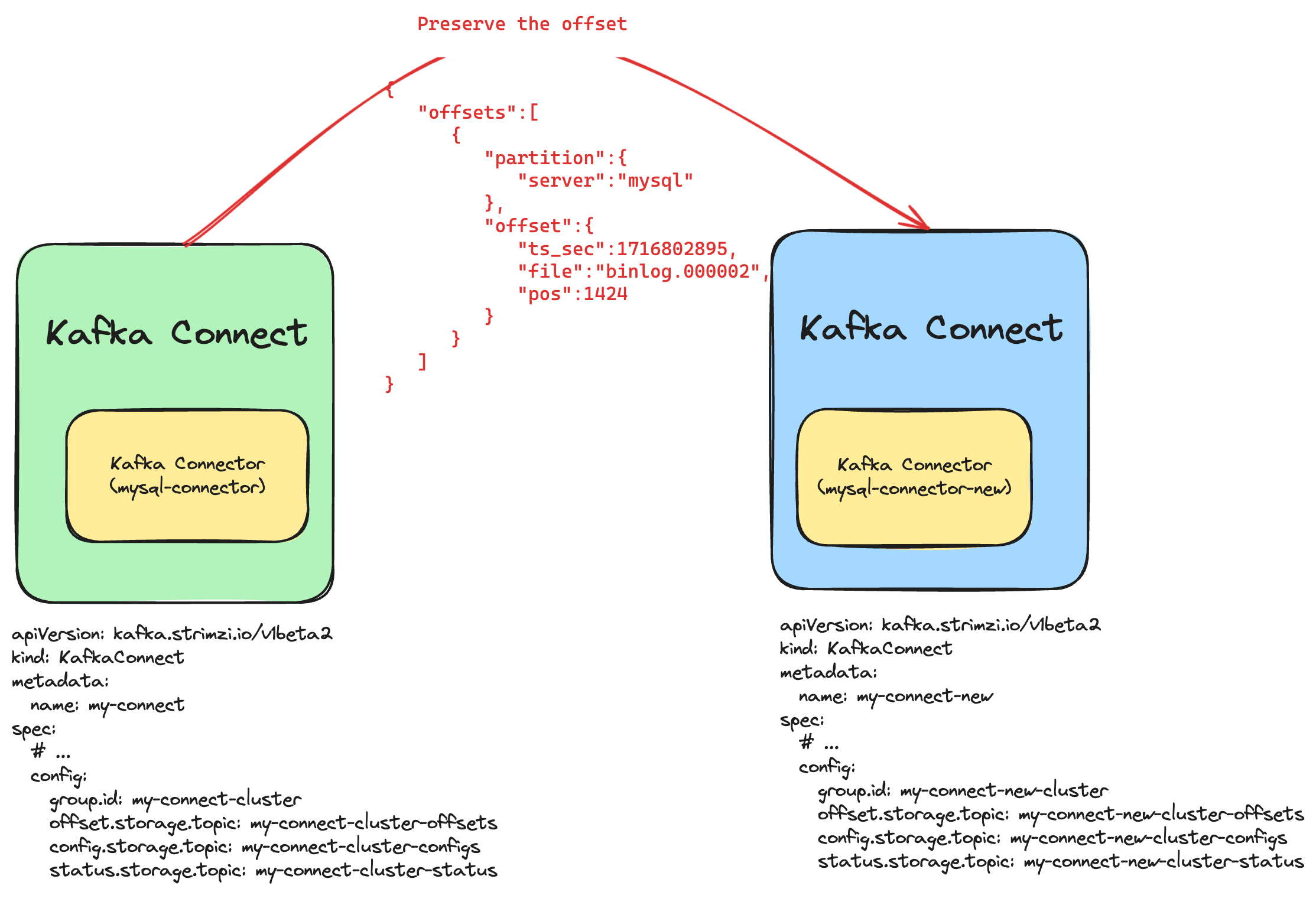
So, how does it work?
Let's break it down:
Stop the connector: First, stop the connector in your original cluster using the
/connectors/{name}/stopendpoint.a. Endpoint:
PUT /connectors/{name}/stopb. Action: Stop the connector in the original Kafka Connect cluster. In AMQ Streams 2.6 you can simply add
spec.state:stoppedto Kafka Connector CR.Retrieve offsets: Next, fetch the offsets for the connector using the
/connectors/{name}/offsetsendpoint.a. Endpoint:
GET /connectors/{name}/offsetsb. Action: Retrieve offsets for the connector in the original cluster.
For instance:
oc rsh debezium-connect-connect-0 curl localhost:8083/connectors/mysql-connector/offsets {"offsets":[{"partition":{"server":"mysql"},"offset":{"ts_sec":1716802895,"file":"binlog.000002","pos":1424}}]}Delete the connector: Once you have the offsets, delete the connector using the
/connectors/{name}endpoint.a. Endpoint:
DELETE /connectors/{name}b. Action: Delete the connector from the original Kafka Connect cluster. In AMQ Streams, you can just delete the Kafka Connector CR.
For instance:
oc delete kafkaConnector mysql-connector kafkaconnector.kafka.strimzi.io "mysql-connector" deleted- Recreate the connector: Set up your new cluster and recreate the connector.
Stop the new connector: Stop the newly created connector using the
/connectors/{name}/stopendpoint.a. Endpoint:
PUT /connectors/{name}/stopb. Action: Create and stop the connector in the new Kafka Connect cluster. Both steps 4 and 5 can be performed by applying the Kafka Connector CR with
spec.state:stopped.Check the status:
oc rsh debezium-connect-new-connect-0 curl localhost:8083/connectors/mysql-connector-new/status {"name":"mysql-connector-new","connector":{"state":"STOPPED","worker_id":"debezium-connect-new-connect-0.debezium-connect-new-connect.dbz-mysql.svc:8083"},"tasks":[],"type":"source"}%Set offsets: Now comes the magic. Use the
/connectors/{name}/offsetsendpoint to set the offsets in the new cluster, using the information you retrieved earlier.a. Endpoint:
PATCH /connectors/{name}/offsetsb. Action: Set the connector's offset in the new Kafka Connect cluster, reusing the output obtained from the original cluster.
For instance:
oc exec -i debezium-connect-new-connect-0 -- curl -X PATCH \ -H "Accept:application/json" \ -H "Content-Type:application/json" \ http://localhost:8083/connectors/mysql-connector-new/offsets -d @- <<'EOF' { "offsets":[ { "partition":{ "server":"mysql" }, "offset":{ "ts_sec":1716802895, "file":"binlog.000002", "pos":1424 } } ] } EOFOutput:
{"message":"The Connect framework-managed offsets for this connector have been altered successfully. However, if this connector manages offsets externally, they will need to be manually altered in the system that the connector uses."}%Restart the connector: Finally, restart the connector using the
/connectors/{name}/resumeendpoint, and voila! Your connector is up and running in its new home, with all the offset goodness preserved.a. Endpoint:
PUT /connectors/{name}/resumeb. Action: Restart the connector in the new Kafka Connect cluster. In AMQ Streams you have just to change the
statein kafka Connector CR tostate: running
If you're eager to try this out yourself, we've prepared an end-to-end tutorial for you. It's complete with instructions and examples, so you can have fun exploring this new feature: Check it out here.
Conclusion
This new feature opens up a world of possibilities for Kafka Connect users, from easier development workflows to improved fault tolerance and more reliable data processing. So go ahead, give it a spin, and let us know what you think.
Note
Managing the offsets is only possible via the REST API; there's currently no support in the Kafka Connect/Connector CRs. There's a Strimzi proposal to add support in the CR: Strimzi Proposal. For more details about each endpoint, see the Kafka Connect REST API documentation.
For additional context and details on the 3.5.0 release, you can refer to the original post on the Apache Kafka blog here.
Enjoy!