This is the fourth episode of our series that dives into training and deploying computer vision models at the edge. And I have some good news: we're already past the halfway point. Have a look at the series outline and the remainder of the fascicles:
- How to install single node OpenShift on AWS
- How to install single node OpenShift on bare metal
- Red Hat OpenShift AI installation and set up
- Model training in Red Hat OpenShift AI
- Prepare and label custom datasets with Label Studio
- Deploy computer vision applications at the edge with MicroShift
Introduction
Training artificial intelligence (AI) models is a pivotal process in the development of AI systems, demanding significant time and resources. The importance of this training phase cannot be overstated, as it is during this stage that the model learns to recognize patterns, make predictions, and perform tasks based on the provided data.
Red Hat OpenShift AI provides a robust platform for conducting AI model training. This platform empowers us to efficiently perform model development iterations, fine-tune parameters, and validate performance, ultimately facilitating the creation of high-quality AI solutions. We will use this platform to train our YOLO algorithm based on previously processed data.
Info alert: Note
Red Hat OpenShift AI deployment on single node OpenShift is currently not officially supported. Refer to the OpenShift AI official documentation to get more information about supported platforms and configurations.
For this demo, we have decided to develop a real-time detection system that will provide efficient and accurate animal locations and some statistics within video sequences. In this article, we are going to show you the complete process for training the model based on a dataset of animal images previously labeled. It is worth mentioning that the original set of images and labels has been prepared in advance and converted to YOLO format to simplify the explanation.
However, if you want to build a demo to detect a custom set of objects, don't worry. We show you how to label your own image dataset in the article Prepare and label custom datasets with Label Studio. Then you will only have to replace the animals dataset with your custom one.
Project set up
Once you are logged in the OpenShift AI dashboard, the first step is to create the project where all of the resources related to our project will live. It is considered a good practice to create separate projects each time to ensure component isolation and better access control. Here you have the steps to create the new project:
- On the left menu in the dashboard, navigate to the Data Science Projects tab.
- Click the Create data science project button.
- There you can type your preferred project name. In my case, it will be
safari. - Finally, click Create.
That’s how easy it is to create the project namespace. This is where all the resources tailored to this demo will be deployed.
Create workbench
Now that we have our newly created safari project, we can configure our workbench:
- Click Create workbench.
- Once on the workbench configuration page, complete the fields to match the following specifications:
- Name:
safari(insert any preferred name). - Image selection:
PyTorch. - Version selection:
2023.2(recommended). - Container size:
Medium(this will depend on your node resources; the more, the better). - Accelerator:
NVIDIA GPU. - Number of accelerators:
2. (In this case, our node has 2 NVIDIA GPU cards, but you will need to select the number that applies to your environment.) - Check the Create new persistent storage box.
- Name:
safari(insert any preferred name). - Persistent storage size:
80 GiB(we can always extend it later if needed).
- Name:
- Once you have completed the form, click Create workbench. You will be redirected to the project dashboard, where the workbench is starting. It could take a couple of minutes to pull the image before changing the status to Running. Your project should look similar to Figure 1.
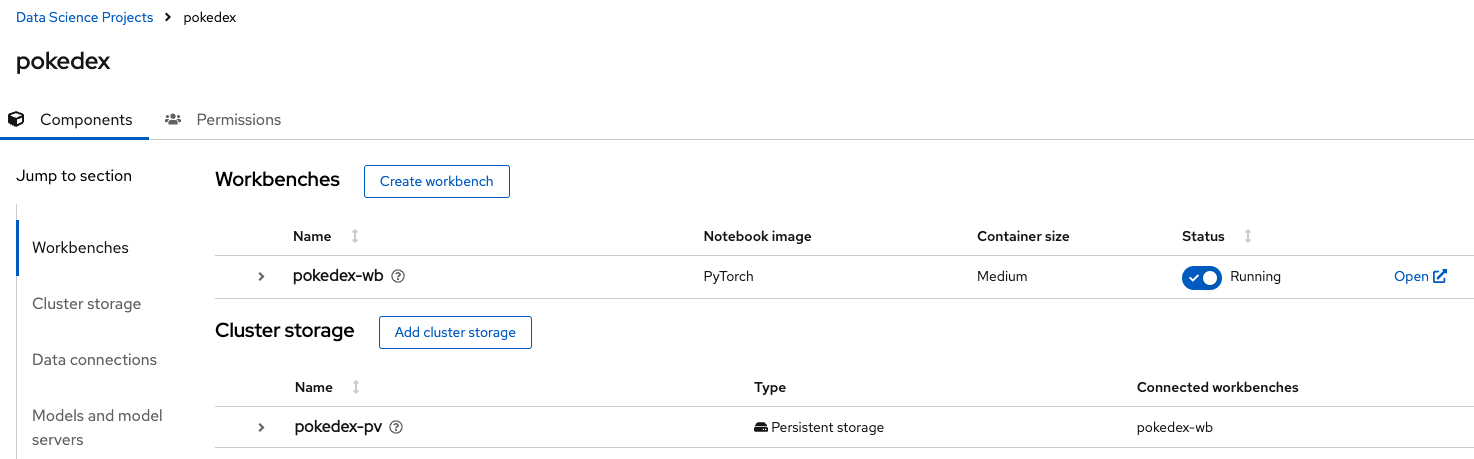
- Now you can access the Workbench Interface by clicking Open and logging in using your kubeadmin credentials.
That's it! Our workbench is ready and the next step will be to deploy the Notebook containing the training instructions. Now, jump to the model training section.
Model training
The moment to directly work with the AI model has arrived. When you open your workbench, you will be directed to a Jupyter environment, a versatile computational platform used for interactive computing, data analysis, and scientific research. It provides a web-based interface that allows users to create files with code in multiple programming languages, as shown in Figure 2.

Notebooks in Jupyter serve as interactive computing documents that combine live code, visualizations, explanatory text, and multimedia elements in a single interface, allowing users to execute code blocks individually, visualize results immediately, and document their processes in real-time. We can always spin up a new Python Notebook and start programming right from scratch, but OpenShift AI also makes it possible to import Git repositories and visualize the dataset and Notebooks directly from the Jupyter interface.
On the left side of the screen, you should see the Git icon (shown in Figure 3).
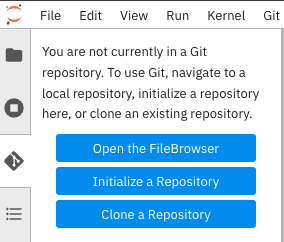
Click Clone a Repository and paste the Safari GitHub repository URL: https://github.com/OpenShiftDemos/safari-demo
After a few moments, you should see the safari-demo directory cloned in your Jupyter environment. Let me briefly explain the repo folder architecture:
notebooks: Stores different notebooks. We will use:Safari_YOLOv8.ipynb.dataset: Contains the images and annotations for the animal images.weights: Stores the weights resulting from the training. You can use them in case you don’t want to train the model on your own.
Info alert: Note
If you are trying to build your own model, you can use the notebook in the safari-demo as a reference. Remember to adapt the following steps to point out the model to your custom dataset.
Navigate to safari-demo > notebooks > Safari_YOLOv8.ipynb to open the notebook. The file contains code cells that can be run by clicking the Play button at the top. At this point, you can proceed with the training by reading through the notebook or via this article, as we will be reviewing some of the most important code cells.
First of all, we are going to clone the official YOLO repository and install some of the package dependencies:
!pip install --upgrade pip
!pip install pickleshare
!pip install seaborn
!pip install opencv-python-headless
!pip install py-cpuinfo
!git clone https://github.com/ultralytics/ultralytics
%cd ultralytics
from ultralytics import YOLO
from PIL import ImageNext, verify that the images and labels for the training are in the right path. If you are using your own dataset, from now on, you will have to replace this information with the path where your dataset images are stored.
!ls /opt/app-root/src/safari-demo/dataset/*The output will show us the training, test, and validation folders with the images and labels subfolders. Also, the data.yaml file will be listed. Let me show you the information this file contains:
train: /opt/app-root/src/safari-demo/dataset/train/images
val: /opt/app-root/src/safari-demo/dataset/test/images
nc: 80
names: ['Hippopotamus', 'Sparrow', 'Magpie', 'Rhinoceros', 'Seahorse', 'Butterfly', 'Ladybug', 'Raccoon', 'Crab', 'Pig', 'Bull', 'Snail', 'Lynx', 'Turtle', 'Canary', 'Moths and butterflies', 'Fox', 'Cattle', 'Turkey', 'Scorpion', 'Goldfish', 'Giraffe', 'Bear', 'Penguin', 'Squid', 'Zebra', 'Brown bear', 'Leopard', 'Sheep', 'Hamster', 'Panda', 'Duck', 'Camel', 'Owl', 'Tiger', 'Whale', 'Crocodile', 'Eagle', 'Otter', 'Starfish', 'Goat', 'Jellyfish', 'Mule', 'Red panda', 'Raven', 'Mouse', 'Centipede', 'Lizard', 'Cheetah', 'Woodpecker', 'Sea lion', 'Shrimp', 'Polar bear', 'Parrot', 'Kangaroo', 'Worm', 'Caterpillar', 'Spider', 'Chicken', 'Monkey', 'Rabbit', 'Koala', 'Jaguar', 'Swan', 'Frog', 'Hedgehog', 'Sea turtle', 'Horse', 'Ostrich', 'Harbor seal', 'Fish', 'Squirrel', 'Deer', 'Lion', 'Goose', 'Shark', 'Tortoise', 'Snake', 'Elephant', 'Tick']Info alert: Note
You will need to create a similar file if you are using a custom dataset, modifying the number of classes, labels list, and the route to your images.
As you can see, this is the file that YOLO uses as a reference to know where the training and validation folders are located. We also need to let it know how many classes we have. In our case, there are 80 different animals. Next comes the list of the class names in order. This is important when labeling the dataset images. Figure 4 shows an example.

Each line in the text file corresponds to a boundary box. The first number on each line corresponds to the class name. In this example, 0 means Zidane, but in our model, 0=Hippopotamus, as shown in the data.yaml.
Now that we know the basics, it’s time to train the model. As you can see below, the code is quite simple. First, we load a pretrained model that the YOLO Ultralytics team provides. These weights will be used as a starting point for the training with the new animal data. Next, we just need to call the train function and fill in a couple of parameters:
- data: the path to our
data.yamlfile. - epoch: maximum number of iterations during the training.
- imgsz: size of the images used for the training.
- batch: number of images used during each training iteration.
model = YOLO("yolov8m.pt")
model.train(data='/opt/app-root/src/safari-demo/dataset/data.yaml', epochs=100, imgsz=640, batch=16)Here starts the training of the YOLOv8 model using our dataset. In the first line of the output shown when running the cell, you should spot your GPU card, which is used to speed up the process. In my case, it’s the Tesla M60 GPU card:
Ultralytics YOLOv8.0.221 🚀 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (Tesla M60, 15102MiB)Wait until the training process finishes. This will be done automatically when either the function reaches the iteration number specified in the epoch parameter or if at some point there is no significant accuracy improvement between iterations. The training time will depend on different factors, including the size of the images and the GPU used. When finished, the weights file will be automatically saved in the following folder:
Results saved to runs/detect/trainAt this point, our recently trained model should be able to detect animals on images. Let's try it out by passing a sample image. We just need to load our weights file to the model and specify the path to the image used as an example.
Info alert: Note
If you want to save some time and skip the training process, you can use the weights file provided in the Git repository (safari-demo > weights > best.pt). Modify the paths to point to the file if needed.
model = YOLO('/opt/app-root/src/safari-demo/notebooks/ultralytics/runs/detect/train/weights/best.pt')
results = model('/opt/app-root/src/safari-demo/dataset/validation/sample.png', save=True)Here you have the results (Figure 5):
Image.open('/opt/app-root/src/safari-demo/notebooks/ultralytics/runs/detect/predict/sample.png')
Our brown bear is detected correctly. Now that we know that our model is working, we just need to save the model in onnx format so that we can use it in a container image later:
model.export(format='onnx')The file is saved in the following folder. Navigate to the directory and download it to your computer. We will use it later to be part of our Safari application:
Results saved to
/opt/app-root/src/safari-demo/notebooks/ultralytics/runs/detect/train/weights/best.onnxThat’s all we need for the training. We are ready to jump to the latest episode: the model deployment in Red Hat build of MicroShift.
Video demo
The following video explores the relevance of Red Hat's AI platform in order to train a computer vision model using a GPU to speed up the process.
Next steps
In this tutorial, you used Red Hat OpenShift AI to train a YOLO v8 model. Our exploration has not only delved into the intricacies of object detection but also showcased the integration of computer vision cutting-edge technology with the robust OpenShift platform.
As we bid farewell to this series, our final destination awaits in the next article, where we will witness the deployment of our trained model onto MicroShift. Join us in the grand finale: Deploy computer vision applications at the edge with MicroShift
Last updated: May 23, 2024