With a renewed focus on revenue, organizations are looking to maximize their return on IT. Often this is achieved by removing silos: hybrid clouds are extending to the edge and edge computing is reaching out to the hybrid cloud. This integration creates a lot of questions on how to build an effective edge solution. After 5+ years in the edge computing space, I am afraid to say there is no simple answer. There is no one-size-fits-all solution; every use case has different requirements, calling for a different solution.
In this series, I will give guidance on how to find the best-fitting, sharpest edge solution for your needs. After a quick introduction and definition of terms, I will present a list of guiding questions to better understand the problem space. Considering all of these is crucial to make a successful edge deployment—a single missed aspect could be a game-changer. The decentralized nature of edge computing offers a lot of benefits, but also presents challenges.
In the final two installments of this series, I will provide an overview of Red Hat Edge solutions, how they interact with each other, and their strengths so as to give you guidance on crafting your solution.
What is edge computing?
There are plenty of definitions out there, but I usually go with a simple one:
Edge computing is the use of decentralized compute resources to process data that are not in your data center, not in your cloud, but are at other locations where some constraints apply.
Let’s dissect this a bit.
Compute resources are needed to run a workload. A workload is more valuable to the business if it makes data accessible and turns it into actionable insights, e.g., cost savings, efficiency improvements, higher customer satisfaction, etc.
Unlike your traditional datacenter or cloud deployment, edge is decentralized: you need to use compute where the data is. For example, due to latency, you have to react within 50 milliseconds, but a cloud deployment would take too long. Coca-Cola’s private valve mixture data (one of the best guarded business secrets) is not allowed to leave premises, but is needed for quality control.
We see all types of workloads at the edge, from traditional monolithic applications to modern microservices or event-driven architectures running in containers to loading and training data into a machine learning model. This is quite similar to hybrid cloud workloads, depending on where your organization is on their application modernization journey.
The constraints are what makes edge computing interesting and different from data center or cloud-based solutions. Examples of constraints include physical limitations like space, cooling requirements, and networking. Physical limitations might require the edge device to fit under the retail shop counter. The cooling requirements for a manufacturing shop might need to be passive, as there's a lot of dust on the shop floor. Finally, networking constraints might include needing 4G or 5G only when the mobile edge device has arrived in safe harbors, or needing to air-gap critical infrastructure skills (only non-IT people are on site or the site is completely unstaffed).
To create the best edge solution for your situation, you must fully understand two things: the workload and the constraints. But before we jump into those details, we need to talk briefly about how we structure or layer edge computing.
One size fits all?
There is no one single edge, but rather layers that serve as stops along the way from core systems out to the edge. Examples of these include provider edge, access/aggregation, or operational edge. There might be only one layer of edge locations directly connected to the core system, but there might also be four or more intermediate layers.
To simplify the discussion I will use the following terms to describe edge architecture: far edge, near edge, and core. These three layers are a good enough abstraction for a general discussion.
Figure 1 shows general layers of an edge computing deployment.
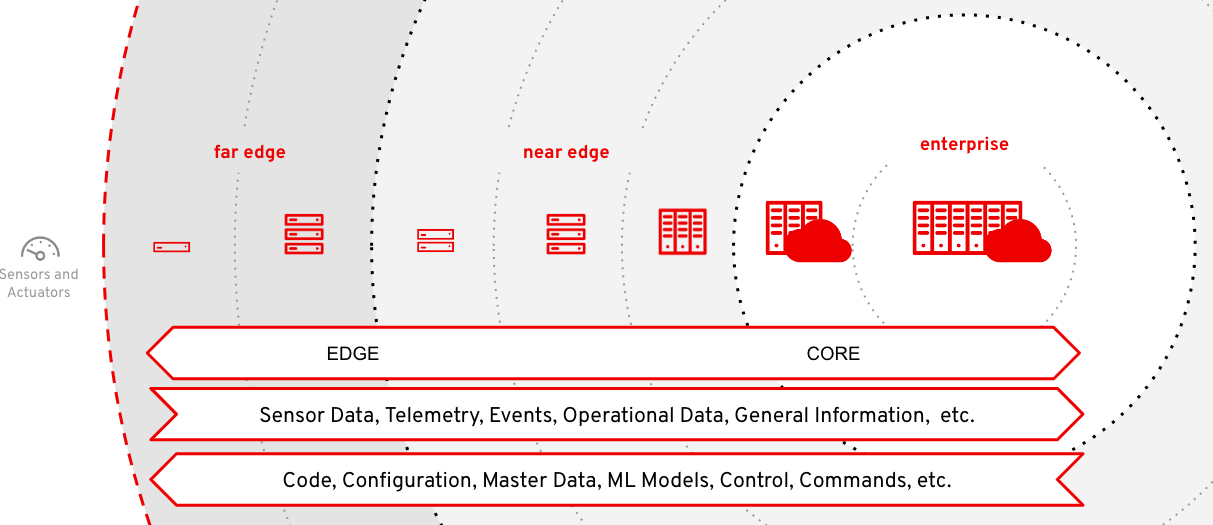
Core systems are the enterprise systems inside the centralized data center or cloud. Edge is everything else outside of that. For the sake of simplicity, I will assume just two layers: near edge and far edge. These are not necessarily defined by physical location or distance. For example a far-edge site could be on the same campus within 100 meters of the near edge site, but because it is a totally isolated network, it is considered “far” from near edge or core components.
As each layer gets further away from the core and closer to the far edge, you typically see an increase in the number of distributed locations, but a decrease in each location’s size.
As an example of this architecture would be a manufacturing company that might house their core systems in the cloud. They have 50 manufacturing sites worldwide, each equipped with 2-5 racks of compute power, which make up the near edges. Each site has 2-10 assembly lines on a dedicated operational network, with around 10-100 industrial PCs per line, which we consider far edge.
Understanding the workload
Let’s return to the necessary considerations for creating an edge computing solution. We want to first understand our workload. Here are some questions to ask yourself to get a better understanding of your edge use case:
What is the use case?
Consider the use case, including the business challenge and case, your reason to act, and the added value.
What kind of application development is involved?
You also want to consider development: Is this a custom application that your own organization develops, or is it commercial-off-the-shelf (COTS) software from an independent software vendor (ISV), or both?
What does the workload look like?
Think about what your workload looks like, whether it’s a traditional packaged application or a modern microservice or modular application. Is this a one-time deployment, or continuous, and how much does it change? You may have high availability requirements, where you’ll need to understand how planned and unplanned downtime affects your deployment. Also consider capacity: will you need certain numbers or types of CPU cores, memory, networks, disks, or GPU-acceleration? What do you need today vs. in 12 months?
What kind of data is involved?
What data are you needing to send to and from the edge and your core systems, and how much, how quickly, and how frequently will you need to move it? You might be able to analyze data on-site, but will need to know. Do you need to store data or state persistently? What about backup and recovery?
What kind of lifecycle management will you need?
Consider your needs and plans for initial provisioning, day 2 operations, and end of service life. Who or what is needed to do these tasks, and will they need to be on-site or remote?
Now that you have a good idea of our workload, you’ll want to understand the specific constraints you’re facing at your edge sites.
Understanding the constraints
There are a number of limitations you’ll want to consider for your edge devices.
Physical constraints
Consider rack requirements and dimensions of your physical space. Security will also be important, so ask how the space will impact the device’s vulnerability. Is there a regular and stable power supply or is it running on solar or batteries? Do you need passive cooling due to dust, oil, or other elements? Finally, how accessible is the device to staff?
Security constraints
Aside from physical security, how will you protect against device and disk theft or tampering? Think about how secrets and private keys are managed, whether they can be stolen in transit, or whether the BIOS can be altered when deployed. Consider the software supply chain and whether it’s secure. Are there standards you have to comply with, such as FIPS 140-2, IEC62443, HEPA, etc? What’s the worst case scenario if an attacker gains full access to the device?
Network constraints
It’s important to think about how an edge site is connected. Is it remote, low bandwidth, high latency, no connectivity, or only intermittently connected (e.g., when sun or wind energy is active)? Do notes have static or dynamic IP addresses?
Staffing constraints
Who will be on site to either operate or repair the infrastructure? Are the staff non-technical, minimally technically, or fully enabled technical staff?
Organizational constraints
Consider how mature an organization is for containerized/Kubernetes-based solutions. Who develops and who operates which parts of the solution? Also consider lifecycle management constraints at your organization. What is the flow of the device from manufacturer to final destination? Where is device identity established? Could you use something like FIDO secure device onboarding?
Conclusion
With all of these variables and challenges in mind, what sort of platforms can address them? Now that you know what considerations to keep in mind, the next article in this series will talk about Red Hat Edge platforms that can address them—as well as which ones are best for certain use cases.
Read Part 2: Red Hat Edge platforms: More options for more use cases
Last updated: November 20, 2023