Red Hat Device Edge is a new solution that delivers a lightweight enterprise-ready Kubernetes distribution called MicroShift combined with an edge-optimized operating system built from Red Hat Enterprise Linux (RHEL).
This article will guide you through the process of building your own customized Red Hat Device Edge images, from setting up the necessary building infrastructure to deploying the image on a device or virtual machine.
This tutorial will also show you a way to manage edge devices using supported tooling such as Red Hat Ansible Automation Platform in a pull-based model. This approach simplifies management and more accurately emulates real-life edge device connectivity.
Building Red Hat Device Edge images
Before you start to learn the process of creating and customizing Red Hat Device Edge images, we have pre-built one for you. Jump ahead to the section Test a pre-built Red Hat Device Edge image so you can download the image and start testing. If you are interested in the process, keep reading.
The diagram in Figure 1 shows the architecture of what we are going to build in this tutorial.
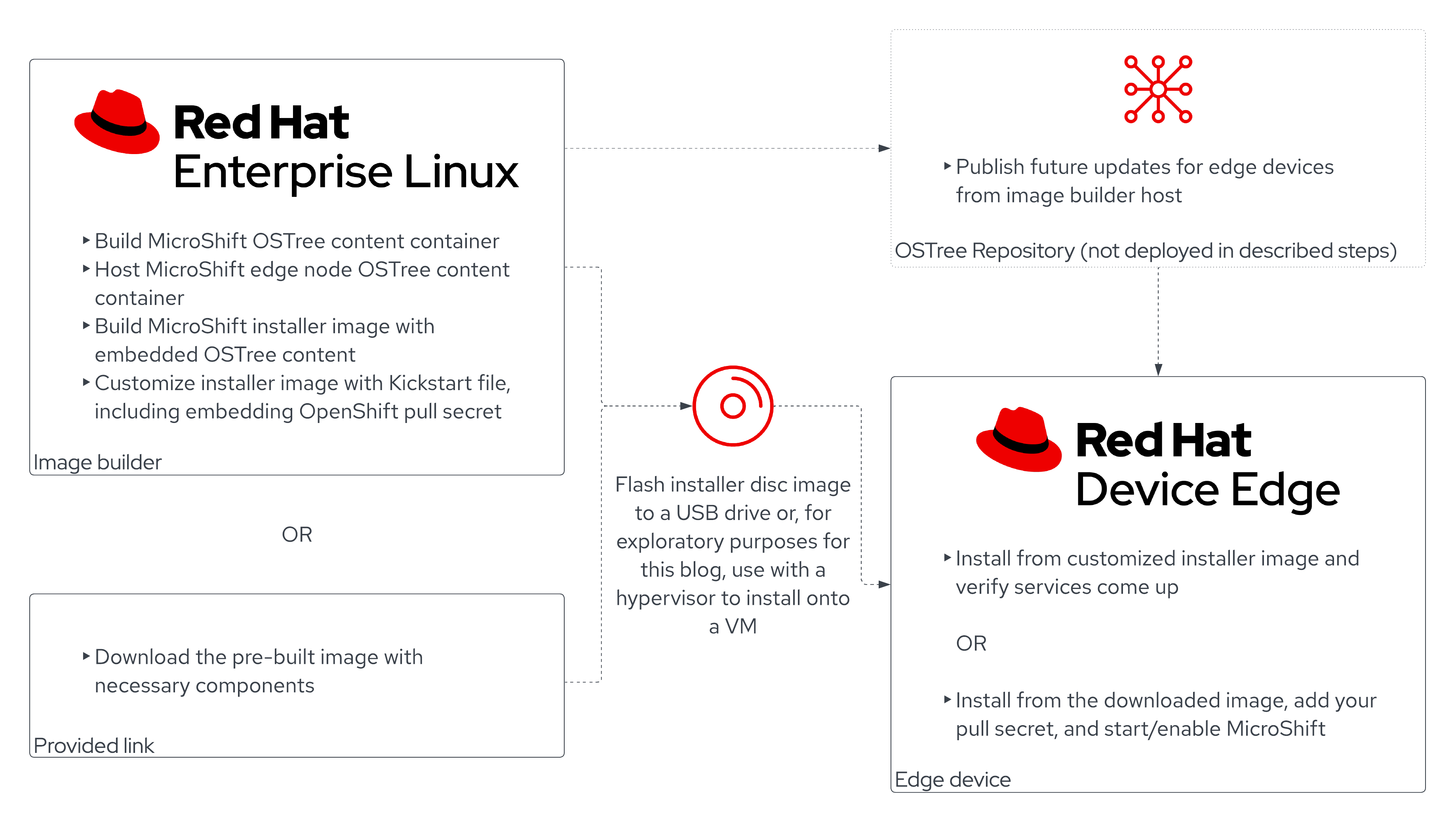
First of all, we will need to set up our building machine. This is basically a Red Hat Enterprise Linux system where we are going to install a tool called image builder. Image builder allows you to build customized RHEL system images prepared for deployment on cloud platforms or on bare metal machines. Image builder automatically handles the setup details for each output type and therefore is easier to use and faster than other manual methods of image creation.
Install image build tools
Assuming there is already a RHEL 8 or RHEL 9 system with an active subscription you can work on (we recommend a disk size of 85 G to allow room for multiple images), let’s go ahead and install a set of packages:
sudo dnf update -y
sudo dnf install -y git osbuild-composer composer-cli cockpit-composer bash-completion lorax
sudo systemctl enable --now osbuild-composer.socket
This installs the required tools to build our customized images. Image builder works with a construct called sources, which basically are RPM repositories where the tool is going to find extra packages not provided by the standard sources. MicroShift is shipped as part of the Red Hat OpenShift repository, and it needs as a dependency, the Open vSwitch package shipped as part of the Fast Datapath repository.
Add image builder sources
In the next step, we will add these two repositories as image builder sources:
ARCH=$(uname -i)
cat << EOFRHOCP > rhocp-source.toml
check_gpg = true
check_ssl = true
id = "rhocp-4.12"
name = "rhocp-4.12"
rhsm = true
system = false
type = "yum-baseurl"
url = "https://cdn.redhat.com/content/dist/layered/rhel8/$ARCH/rhocp/4.12/os"
EOFRHOCP
cat << EOFFDP > fdp-source.toml
check_gpg = true
check_ssl = true
id = "fast-datapath"
name = "fast-datapath"
rhsm = true
system = false
type = "yum-baseurl"
url = "https://cdn.redhat.com/content/dist/layered/rhel8/$ARCH/fast-datapath/os"
EOFFDP
composer-cli sources add rhocp-source.toml
composer-cli sources add fdp-source.toml
After adding the sources, now you list them with the following command:
composer-cli sources listAnd see the following four sources:
appstream baseos fast-datapath rhocp-4.12
Create a blueprint for the Device Edge image
Image builder has the concept of blueprint, a definition of the image to be built, where you can specify a set of packages, versions, and several customization options. Refer to the upstream documentation. Now, we will create the blueprint for our Red Hat Device Edge image and push it to the image-builder service.
cat << EOF > microshift-container.toml
name = "microshift-container"
description = ""
version = "0.0.1"
distro = "rhel-8"
modules = []
groups = []
# MicroShift and dependencies
[[packages]]
name = "microshift"
version = "*"
[[packages]]
name = "openshift-clients"
version = "*"
[customizations]
hostname = "edge"
[customizations.services]
enabled = ["microshift"]
EOF
composer-cli blueprints push microshift-container.tomlThe depsolve sub-command will check if all packages are reachable from the build host and dependencies will be fulfilled, ensuring a better result during the build process. It will show a list of all packages included in the resulting image.
composer-cli blueprints depsolve microshift-containerCreate a rpm-ostree based RHEL image
Red Hat Device Edge makes use of the benefits of certain technologies that are suitable for edge computing scenarios. rpm-ostree is a technology that allows fully managed and reprovisionable operating system images with transactional upgrades and rollbacks.
Image builder provides a set of image types (such as qcow2, gce, ami, etc.) that includes rpm-ostree based images types, like edge-container, edge-commit, etc. If you want to find out more about these image types, read the documentation.
For this purpose, we are going to create an OSTree-based Red Hat Enterprise Linux 8.7 image with the following command:
composer-cli compose start-ostree microshift-container --ref rhel/8/$ARCH/edge edge-containerYou can check the status of the build with the following command:
ID=$(composer-cli compose list | grep "RUNNING" | awk '{print $1}')
watch composer-cli compose list
Once it’s finished you can cancel the watch with Ctrl+C. Download the image with the following commands:
composer-cli compose image $ID
sudo chown $(id -u):$(id -g) $ID-container.tarThis file is ready to be loaded into Podman and run as a container. The container will expose the OSTree commit for image builder to pull and embed it into the installer image:
podman load -i $ID-container.tar
IMAGE_ID=$(podman images | awk '/<none>/{print $3}')
podman tag $IMAGE_ID localhost/microshift-container
podman run -d --name=edge-container -p 8080:8080 localhost/microshift-container
The following steps will create an empty blueprint that will basically pull the rpm-ostree commit from the container we have just created, and embed it into the installer image. The resulting device will not point at the exposed rpm-ostree, but the local copy for the sake of simplicity and demonstration. In following steps, we will show you how to configure the device to point at the endpoint where the rpm-ostree is going to look for updates.
cat <<EOF > microshift-installer.toml
name = "microshift-installer"
description = "MicroShift Installer blueprint"
version = "0.0.1"
EOF
composer-cli blueprints push microshift-installer.toml
composer-cli blueprints depsolve microshift-installer
composer-cli compose start-ostree microshift-installer edge-installer --ref rhel/8/$ARCH/edge --url http://localhost:8080/repo/
ID=$(composer-cli compose list | grep "RUNNING" | awk '{print $1}')
watch -n 5 composer-cli compose listOnce the image is ready, the status will show as FINISHED. Cancel this watch with Ctrl+C as well and download the resulting image with the following command:
composer-cli compose image $IDThe installer ISO image has been created.
Inject and configure the kickstart file
In order to have a fully automated installation experience, we will inject a kickstart file that configures several aspects such as LVM partitioning and firewall rules. Read through the kickstart file to understand what it is doing and you will find a couple of sections you might want to uncomment:
cat << EOF > kickstart-microshift.ks
lang en_US.UTF-8
keyboard us
timezone UTC
text
reboot
# Configure network to use DHCP and activate on boot
network --bootproto=dhcp --device=link --activate --onboot=on
# Partition disk with a 1GB boot XFS partition and an LVM volume containing a 10GB+ system root
# The remainder of the volume will be used by the CSI driver for storing data
#
# For example, a 20GB disk would be partitioned in the following way:
#
# NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
# sda 8:0 0 20G 0 disk
# ├─sda1 8:1 0 200M 0 part /boot/efi
# ├─sda1 8:1 0 800M 0 part /boot
# └─sda2 8:2 0 19G 0 part
# └─rhel-root 253:0 0 10G 0 lvm /sysroot
#
zerombr
clearpart --all --initlabel
part /boot/efi --fstype=efi --size=200
part /boot --fstype=xfs --asprimary --size=800
part pv.01 --grow
volgroup rhel pv.01
logvol / --vgname=rhel --fstype=xfs --size=10240 --name=root
# Configure ostree
ostreesetup --nogpg --osname=rhel --remote=edge --url=file:///run/install/repo/ostree/repo --ref=rhel/8/$ARCH/edge
%post --log=/var/log/anaconda/post-install.log --erroronfail
# Uncomment the following line and replace the rpm-ostree server name variable
# in case you want to expose updates remotely at a certain URL
# echo -e 'url=http://REPLACE_OSTREE_SERVER_NAME/repo/' >> /etc/ostree/remotes.d/edge.conf
# The pull secret is mandatory for MicroShift builds on top of OpenShift, but not OKD
# The /etc/crio/crio.conf.d/microshift.conf references the /etc/crio/openshift-pull-secret file
cat > /etc/crio/openshift-pull-secret << EOFPS
REPLACE_OCP_PULL_SECRET_CONTENTS
EOFPS
chmod 600 /etc/crio/openshift-pull-secret
# Create a default redhat user, allowing it to run sudo commands without password
useradd -m -d /home/redhat -p $(openssl passwd -6 redhat | sed 's/\$/\\$/g') -G wheel redhat
echo -e 'redhat\tALL=(ALL)\tNOPASSWD: ALL' >> /etc/sudoers
# Uncomment the following lines if you want to inject your ssh public key
# mkdir -m 700 /home/redhat/.ssh
# cat > /home/redhat/.ssh/authorized_keys << EOFK
# REPLACE_REDHAT_AUTHORIZED_KEYS_CONTENTS
# EOFK
# chmod 600 /home/redhat/.ssh/authorized_keys
# Make sure redhat user directory contents ownership is correct
chown -R redhat:redhat /home/redhat/
# Configure the firewall (rules reload is not necessary here)
firewall-offline-cmd --zone=trusted --add-source=10.42.0.0/16
firewall-offline-cmd --zone=trusted --add-source=169.254.169.1
# Make the KUBECONFIG from MicroShift directly available for the root user
echo -e 'export KUBECONFIG=/var/lib/microshift/resources/kubeadmin/kubeconfig' >> /root/.profile
%end
EOFThis kickstart file performs a set of steps to configure the host during the installation in a way required by MicroShift.
The device will need to have the OpenShift pull secret from the user injected so container images can be downloaded from the Red Hat registry. Follow this link, copy your pull secret, and paste it in the following variable:
PULL_SECRET=’’ # Don’t forget the single quotes to keep all characters from the pull secret
sed -i "s/REPLACE_OCP_PULL_SECRET_CONTENTS/$PULL_SECRET/g" kickstart-microshift.ks
sudo mkksiso kickstart-microshift.ks $ID-installer.iso redhat-device-edge-installer-$ARCH.isoDeploy the image
Now you are ready to deploy the ISO you have customized into your device (or virtual machine). It should be located in redhat-device-edge-installer-x86_64.iso in your working directory on the RHEL machine you've been working on. Recover it if necessary and flash it to a USB drive using this documentation or your own preferred method. The installation process is completely automated, and whenever the process is finished, you can log into your device using redhat:redhat credentials.
MicroShift should be up and running, and the OpenShift client is ready to use. You can copy the kubeconfig file into the default location of your user:
mkdir ~/.kube
sudo cat /var/lib/microshift/resources/kubeadmin/kubeconfig > ~/.kube/config
Or log in as root (sudo -i) and it will be ready for you.
$ oc get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE openshift-dns dns-default-87gk8 2/2 Running 0 111s openshift-dns node-resolver-tdpdc 1/1 Running 0 111s openshift-ingress router-default-54765bcdf7-qbvz7 1/1 Running 0 106s openshift-ovn-kubernetes ovnkube-master-l6xgk 4/4 Running 0 111s openshift-ovn-kubernetes ovnkube-node-gdwhj 1/1 Running 0 111s openshift-service-ca service-ca-79dbd484cf-kr549 1/1 Running 0 106s openshift-storage topolvm-controller-5c9ccfcf45-jzkdd 4/4 Running 0 112s openshift-storage topolvm-node-j8zbj 4/4 Running 0 112s
Test a pre-built Red Hat Device Edge image
If you want to test a Red Hat Device Image right away, we've provided a pre-built image for you to download here. This image contains all the necessary components, except an OpenShift pull secret that you must insert once the device is up and running. Log into your device using redhat:redhat credentials.
Copy your pull secret to the following location:
/etc/crio/openshift-pull-secretFinally, enable and start MicroShift:
sudo systemctl enable --now microshift.serviceYour device is now ready to be managed!
Managing Red Hat Device Edge
Red Hat Ansible Automation Platform is an automation platform beloved by administrators in the data center and cloud for its simplicity (to learn and to use), flexibility, and advanced capabilities. Ansible Automation Platform is capable of managing any endpoint with a remote management interface, and includes out-of-the-box support for anything that can be managed over SSH, WinRM, and many API-driven environments (such as cloud providers and indeed, the Kubernetes API).
Ansible Automation Platform is designed to support a push-based, agentless management model. This flexibility means that managing new devices is as simple as updating a centralized inventory file with connection and authentication information, which is great for IT administrators looking to manage a large fleet of devices. The agentless architecture also gives us the flexibility to manage devices with a remote management interface that lack the capacity to install an agent, such as the common "appliance" form-factor devices in enterprise IT environments.
Managing workloads on resource-constrained edge devices
Red Hat Device Edge, being designed for very small form factor devices, finds its niche in the field rather than the data center or cloud. The OSTree deployment brings some nice features for that data center environment, but the features clearly target the edge—and the minimal-footprint Kubernetes at the heart of the Red Hat build of MicroShift clearly targets constrained resource environments who sacrifice features for size, weight, and power (SWAP).
This reality means that in some cases, we won’t control the network environment our Red Hat Device Edge nodes work in. Sometimes they’ll be on a constrained network hosted by a mobile provider; sometimes they’ll be mobile and connecting to WiFi networks opportunistically; sometimes they'll simply have very intermittent network connectivity and a push-based model might imply that a device is unhealthy when it’s simply not reachable.
A more flexible approach
Ansible does have a viable solution for these kinds of devices called ansible-pull, but ansible-pull is only designed for situations where we want a device to manage only itself—and it strictly controls how Ansible inventories may be applied to the node running the command. Because MicroShift’s Kubernetes API is not the same management interface as Red Hat Device Edge’s SSH-based remote access at the OS layer, we might find ourselves in a situation where an application needs host configuration alongside the application deployment. We want a system that works like ansible-pull (rather than the traditional push model of Ansible Automation Platform), but gives us more flexibility.
Luckily, there are supported components of Ansible Automation Platform that make this kind of management model possible. It should be noted that this deployment architecture is not currently explicitly supported by Red Hat in production, but problems with the supported pieces we’re using should be able to be reproduced in a fully supported environment. If you’re a Red Hat customer interested in solving for these constraints then you should work with your account team at Red Hat to express interest.
Architecture diagram
The diagram in Figure 2 shows all the components we are going to use to manage edge devices with Ansible Automation Platform.

Configure the example repository
With all of that stage-setting out of the way, let’s get started. Because we’re driving management of our Red Hat Device Edge node in a GitOps-based pull model, we need a repository to declare our configurations in.
It’s simplest to start from a working example, so head to https://github.com/redhat-na-ssa/microshift-ansible-pull and click the Fork button in the top right to fork the repository into your own account or organization; then click Create fork.
When GitHub finishes making your copy, clone the fork down to the RHEL 8 instance you used as the image builder in the preceding section using whatever method you prefer (GitHub CLI, SSH, HTTPS, your own IDE) and change into the repository root. If you have another RHEL device with valid entitlements and network access to your Red Hat Device Edge node, then it’s safe to run from that as well, but you won’t be able to run these commands from your Device Edge node.
This monorepo is designed to help you manage a single application deployed to a single MicroShift instance right now, but it should be extensible enough that once you get the idea of the workflow contained within you can extend it to fit your edge management use case. Let’s get to using the components included out of the box. Ensure that you have enabled the repositories for supported Ansible Automation Platform components:
sudo subscription-manager repos --enable ansible-automation-platform-2.3-for-rhel-$(rpm -qi redhat-release | awk '/Version/{print $3}' | cut -d. -f1)-x86_64-rpmsInstall the packages we’ll need:
sudo dnf -y install ansible-navigator openshift-clientsRecover your kubeconfig from the MicroShift node. First, identify the IP address of the node from its own console, your DHCP server’s status page, or some other means—and set that IP address to a variable for easy consumption in later steps.
RHDE_NODE=192.168.1.213 # MAKE SURE YOU SET THIS TO THE ACTUAL IP
mkdir -p ~/.kube
ssh redhat@$RHDE_NODE sudo cat /var/lib/microshift/resources/kubeadmin/kubeconfig > ~/.kube/config
sed -i 's/127\.0\.0\.1/'"$RHDE_NODE/" ~/.kube/config
In order to be able to reach the MicroShift API, we’re going to temporarily open the firewall on the Red Hat Device Edge node to port 6443. You should understand, for production systems, which management method is best for your edge endpoints. You can enable SSH and enforce strict security, or you can drop packets to SSH and open the path to the API endpoint (which doesn’t have any authentication/users, simply the built-in administrator who is identified by an X509 certificate), or you can choose to disable both once we get the pull-based management bootstrapped.
ssh redhat@$RHDE_NODE sudo firewall-cmd --add-port=6443/tcp
oc get nodes # to verify that you have connectivity to the endpoint
Ensure that your terminal is in the repository root that you cloned down:
ls
ansible.cfg ansible-navigator.yml app deploy inventory LICENSE playbooks README.md
Edit the inventory to point to your Red Hat Device Edge node:
sed -i 's/10\.1\.1\.11/'"$RHDE_NODE/" inventory/hosts
Ensure that you can locally pull the supported execution environment using the PULL_SECRET you saved earlier by putting it in one of the paths that Podman would find it:
mkdir -p ~/.docker
echo "$PULL_SECRET" > ~/.docker/config.json
Make sure that the Ansible Vault password for your secrets is saved in the location the repository expects it:
vault_pass="definitely a secure password" # This is actually the password encrypting the vault in the repository you forked
mkdir -p /tmp/secrets
echo "$vault_pass" > /tmp/secrets/.vault
If you changed the password for the redhat user on the Red Hat Device Edge node from what was included in the kickstart, you’ll need to edit that. You might also want to change the vault password for the symmetrically encrypted Ansible Vault in the repository. You can do those with the following (optional) steps:
ansible-vault () { podman run --rm -it --entrypoint ansible-vault -v ./:/repo -v /tmp/secrets/.vault:/tmp/secrets/.vault -e ANSIBLE_VAULT_PASSWORD_FILE=/tmp/secrets/.vault --security-opt=label=disable --privileged --workdir /repo registry.redhat.io/ansible-automation-platform-23/ee-supported-rhel8:1.0.0 "${@}" ; }
ansible-vault decrypt inventory/group_vars/node/vault.yml
${EDITOR:-nano} inventory/group_vars/node/vault.yml # and update the password
vault_pass="a totally new password"
echo "$vault_pass" > /tmp/secrets/.vault
ansible-vault encrypt inventory/group_vars/node/vault.ymlOur last little bit of configuration will be to point management to our own fork of the repo, instead of the default. It’s simplest right now to stick with HTTPS repository access for the Red Hat Device Edge node, but you could manage SSH deploy keys as secrets and mount them in place to access a repository over SSH, including a private repository, if it makes sense. Edit the configuration that defines where to look for updates:
MY_GITHUB_ORG=redhat-fan-42 # set this to your actual GitHub org or user who forked the repository
sed -i "s/redhat-na-ssa/$MY_GITHUB_ORG/" deploy/cronjob.yml
Let’s push our changes to the repository up to GitHub:
git status -u # make sure the changed files include only your vault (if applicable), inventory hosts, and the CronJob
git diff # make sure the edits are what you expect (vault re-encrypted, hosts pointing to your IP, and the CronJob pointing to your fork
git add .
git commit -m 'Update for my environment'
git push
To ensure that we can push the bootstrapping configuration to the Red Hat Device Edge node, run the following command to use an Ansible “ping” (which is much more than a simple ICMP ping):
ansible-navigator exec --eev /tmp/secrets:/tmp/secrets:Z -- ansible microshift_node -m pingmicroshift_node | SUCCESS => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/libexec/platform-python"
},
"changed": false,
"ping": "pong"
}
With that, we’re ready to kick off our Red Hat Device Edge configuration bootstrapping!
The Ansible Automation Platform configuration could be embedded into the ISO or by using a provisioning system of your choice as well, instead of doing these manual steps.
Bootstrap the MicroShift configuration
Load the Ansible Vault secret manually into the MicroShift API:
oc create namespace microshift-config
oc create secret generic --from-literal=.vault="$vault_pass" vault-key -n microshift-config
And run the playbooks locally, in push mode, using Ansible Navigator:
for playbook in playbooks/*.yml; do ansible-navigator run $playbook -l microshift,microshift_node --eev ~/.kube/config:/home/runner/.kube/config:Z --eev /tmp/secrets/.vault:/tmp/secrets/.vault:Z; doneExplore the microshift-config namespace to see what we’ve bootstrapped into there:
oc get cm -n microshift-configNAME DATA AGE kube-root-ca.crt 1 2m22s microshift-ansible-pull 1 67s microshift-config-env 5 67s openshift-service-ca.crt 1 2m22s
oc get cronjob -n microshift-config
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE microshift-config 15 * * * * False 0 76s
oc get pvc -n microshift-config
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE microshift-config-data Pending topolvm-provisioner 83s runner-home Pending topolvm-provisioner 83s
oc get pod -n microshift-config
No resources found in microshift-config namespace
Some ConfigMaps, a CronJob (that hasn’t run yet), and two PVCs that will bind when the CronJob does finally run. Feel free to explore those ConfigMaps to better understand them, or dig into the README in the repository you cloned for a detailed explanation of what each of the pieces of this repository does.
Let’s look at the playbooks, now that everything’s set up:
cat playbooks/cluster.yml
---
- hosts: cluster
tasks:
- name: Create the namespace
redhat.openshift.k8s:
state: present
api_version: v1
kind: Namespace
name: hello
- name: Deploy the application
redhat.openshift.k8s:
state: present
namespace: hello
src: '{{ playbook_dir }}/../app/{{ item }}'
loop:
- 00-deployment.yml
- 05-svc.yml
- 10-route.yml
- name: Update the CronJob for the next run
redhat.openshift.k8s:
state: present
src: '{{ playbook_dir }}/../deploy/cronjob.yml'cat playbooks/node.yml
---
- hosts: node
become: true
tasks:
- name: Open firewall ports for the OpenShift Router
ansible.posix.firewalld:
state: enabled
service: '{{ item }}'
permanent: true
immediate: true
loop:
- http
- httpsThese are pretty straightforward and even if you’ve never written a line of Ansible in your life, they should make sense pretty quickly. We’re going to target our MicroShift cluster with a playbook that configures a namespace and deploys an application from some manifests, and update our CronJob definition. Then we’re going to configure the firewall on the node to expose HTTP and HTTPS ports for the OpenShift Router to expose our web-based application.
Because we used ansible-navigator in a more traditional push management model, our changes are reflected right away. We have a CronJob that reaches out to Git for updates before applying the playbooks, so it can be reconciled without any external connectivity to its SSH or Kubernetes API ports.
It is important to highlight that the Ansible Automation Platform execution environment can be executed by a systemd service and a timer using Podman rather than a CronJob, if that's appropriate for your use case.
Let’s look at the route that was created. From your machine with the repository cloned (and the kubeconfig set up), run the following:
cat app/10-route.yml
---
apiVersion: route.openshift.io/v1
kind: Route
metadata:
name: hello-world
spec:
port:
targetPort: 8000
to:
kind: Service
name: hello-world
weight: 100
wildcardPolicy: None
tls:
insecureEdgeTerminationPolicy: Redirect
termination: edge
oc get route -n hello hello-world
NAME HOST ADMITTED SERVICE TLS hello-world hello-world-hello.apps.example.com True hello-world
Our MicroShift default configuration set the cluster’s router to be at apps.example.com, so our route has a fake DNS name. Let’s add that to /etc/hosts so we don’t have to update the cluster base domain or set up DNS on the network:
HELLO_ROUTE=$(oc get route -n hello hello-world -ojsonpath='{.status.ingress[0].host}')
echo "$RHDE_NODE $HELLO_ROUTE" | sudo tee -a /etc/hosts 10.1.1.11 hello-world-hello.apps.example.com
Then let’s curl that Route, accepting the default self-signed TLS certificate:
curl -k https://hello-world-hello.apps.example.comHello, world, from hello-world-b8747f4d7-qc7v8!
oc get pods -n helloNAME READY STATUS RESTARTS AGE hello-world-b8747f4d7-j4bnd 1/1 Running 0 11h hello-world-b8747f4d7-qc7v8 1/1 Running 0 11h hello-world-b8747f4d7-qrpx6 1/1 Running 0 11h
In my example here, it was the second replica that ended up answering the request. Let’s try some GitOps management, changing something pretty straightforward about our application. Set the number of replicas to 1:
sed -i 's/replicas: 3/replicas: 1/' app/00-deployment.yml
Commit the changes and push to your remote repository without running ansible-navigator imperatively:
git status -u
git diff
git add .
git commit -m 'Changed to single replica'
git push
The output of the previous commands should look like this:
$ git status -u
On branch main
Your branch is up to date with 'origin/main'.
Changes not staged for commit:
(use "git add ..." to update what will be committed)
(use "git restore ..." to discard changes in working directory)
modified: app/00-deployment.yml
no changes added to commit (use "git add" and/or "git commit -a")
$ git diff
diff --git a/app/00-deployment.yml b/app/00-deployment.yml
index 2564981..3568124 100644
--- a/app/00-deployment.yml
+++ b/app/00-deployment.yml
@@ -6,7 +6,7 @@ metadata:
labels:
app: hello-world
spec:
- replicas: 3
+ replicas: 1
selector:
matchLabels:
app: hello-world
$ git add .
$ git commit -m 'Changed to single replica'
[main 4e96db7] Changed to single replica
1 file changed, 1 insertion(+), 1 deletion(-)
$ git push
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 32 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 810 bytes | 810.00 KiB/s, done.
Total 4 (delta 2), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To github.com:solacelost/microshift-ansible-pull.git
9c271fd..4e96db7 main -> mainTrigger a manual CronJob run, without waiting for the timer to fire off, with the following command:
MANUAL_TIME=$(date +%s)
oc create job --from=cronjob/microshift-config -n microshift-config microshift-config-manual-$MANUAL_TIME
oc get pods -n microshift-config
At the time of this writing, you might be required to disable CSI Storage Capacity tracking to have the pod successfully create and bind the volumes. (Remember, MicroShift is still in Developer Preview!) To do that easily, you can run the following if your pod fails to schedule:
oc patch csidriver topolvm.io -p '{"spec":{"storageCapacity":false}}'
oc get pods -n microshift-config
Once your manual Job invocation has finished, you can check the logs to see what’s happened:
oc logs -n microshift-config job/microshift-config-manual-$MANUAL_TIME
[...] PLAY RECAP ********************************************************************* microshift : ok=4 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 [...] PLAY RECAP ********************************************************************* microshift_node : ok=2 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Note that on the cluster playbook, one thing changed. Nothing changed on the node. Let’s double-check our application now:
oc get pods -n hello
NAME READY STATUS RESTARTS AGE hello-world-b8747f4d7-qc7v8 1/1 Running 1 12h
curl -k https://hello-world-hello.apps.example.comHello, world, from hello-world-b8747f4d7-qc7v8!
And, just like that, we’ve enabled asynchronous, GitOps-based replication of our Red Hat Device Edge node, including the MicroShift API layer.
Now we’re ready to begin adding more nodes to our inventory and expanding the method we use to apply our CronJob in the playbook to support this flexibility. Let’s look at the existing inventory:
cat inventory/hosts
[cluster] microshift ansible_connection=local ansible_python_interpreter=python3 some_other_microshift ansible_connection=local ansible_python_interpreter=python3 [node] microshift_node ansible_host=10.1.1.11 ansible_connection=ssh ansible_user=redhat some_other_microshift_node ansible_host=86.75.30.9 ansible_connection=ssh ansible_user=redhat
And seeing that we’re managing some_other_microshift in this repository, despite not having it available to us, we should probably consider how we’d apply the same methodology to another edge cluster. Check out the certified collection documentation for the redhat.openshift.k8s module, and consider what we might do with the ansible.builtin.file lookup plug-in combined with the regex_replace filter, alongside the inventory_hostname special variable, available as part of our bootstrapping. A declarative inventory of many edge nodes running the same, or similar, applications are just a few more commits away with this framework.
The bottom line
Ansible Automation Platform is a very capable framework, able to meet your needs for robust and flexible management of endpoints with or without Ansible Controller. The depths of what you can accomplish, declaratively, with Ansible Automation Platform are limited only by your imagination—and, of course, the capabilities and reliability of the collection content at your disposal. If you need more robust workload management across your edge fleet, you could parameterize the shell script a bit further to prefer a branch named after the system UUID, but fall back to main, if desired.
Combining the power of Ansible Automation Platform with the full Kubernetes API available in MicroShift means that we have a wide array of tooling at our disposal for log aggregation, metrics, extensions via Kubernetes Operators, and more—in a fully edge-ready architecture.
Last updated: September 12, 2024