When you have lots of test suites to run, you want somewhere safe to keep all the logs and some way to analyze them. We introduced the Bunsen toolkit in last year's blog post. We return with news about an AI/ML-based extension that lets developers focus on unexpected results.
Recap: Git + SQLite
Bunsen stores test-suite log files, even large ones, in an ordinary Git repo, then analyzes the logs with various parsers, depositing results in an ordinary SQLite file. Queries on the SQLite database let you navigate test runs in aggregate, or down to individual test cases and their log file fragments. They tally aggregate results and allow immediate comparison to other test runs. Simple shell or Python-based scripts perform all the computation, storage management, reporting, and web interfacing. Bunsen requires no complicated infrastructure.
Why AI/ML, too?
Some test suites run 100% clean, but many do not. Quite a few have inconsistent PASS/FAIL scores, reflecting sensitivity to precise system configuration conditions or even to randomness and race conditions in the subject code. These imperfections are difficult to eliminate, so a fact of life of many test suites is having to search through numerous test run-to-test run deltas manually. Like hogs looking for truffles, the hope is that by tediously digging through many deltas, one may find some novel or interesting ones among them: the ones most worth analyzing and fixing.
Bunsen's new AI/ML extensions are designed to help find interesting test cases. Bunsen does this by training a neural network on a corpus of historical test cases in the SQLite database so that it can classify each test case into its actual PASS/FAIL/other outcome. Since the input to the training includes not only test suite and test case names, but also all the metadata that describes the test run, the model can learn what's typical on what platforms, with what compilers, for which test cases—and what's not. Figure 1 shows a sample run to update and train the model on one test run's worth of data.
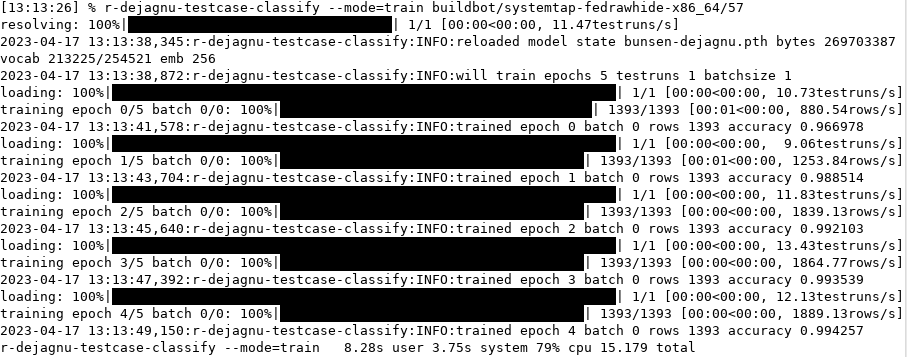
Once the model is trained sufficiently (when its inferred classifications generally match the actual outcomes), it has learned the general patterns and trends. (This is the accuracy fraction above: it went from ~97% to ~99% in one training run.)
Running the model
It's time to enjoy the model. The most basic use is comparing actual to predicted outcomes for future test runs. Simply run the model in the forward direction, feeding in the new test run's metadata, plus each test suite/test case name. Out comes a prediction (with a likelihood). Most of the predictions should match actual results. The mismatches reflect the model's designation as "unexpected," and thus worth human attention. Figure 2 shows a (partial) report running this model against another test run in predict mode.
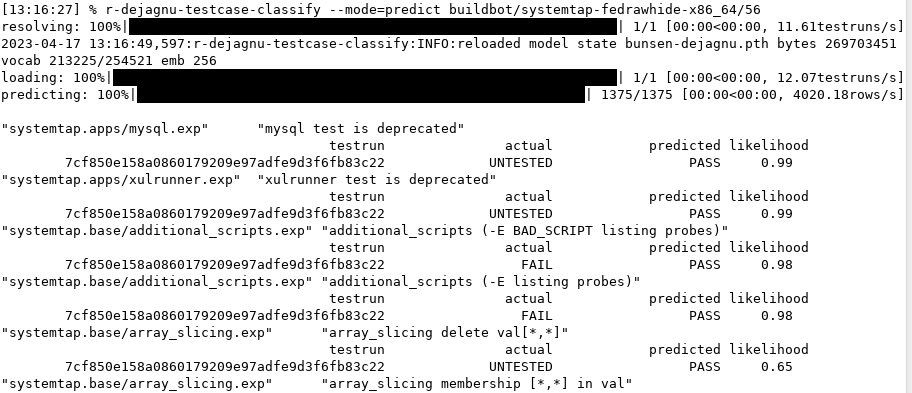

The high-likelihood mispredictions are good candidates for human study. As a starting point, other Bunsen utilities can provide links to the exact file and line where the actual test result was.
Logistics Q&A
Q. What if my Bunsen server does not have a GPU?
A. No problem. The model, while written in Python / PyTorch, is relatively small. In inference-prediction mode, it runs just fine on moderate CPU/RAM servers. A trained model checkpoint can be easily transferred between computers, as can the basic Bunsen Git and SQLite data. That means that model training can run elsewhere, on a beefier or GPU-equipped machine, and the resulting models can be deployed anywhere else.
Q. You mentioned PyTorch. Where do I get that?
A. Unfortunately, Fedora and Red Hat Enterprise Linux (RHEL) do not distribute a version of PyTorch, which is a pretty big library. On such machines, you need to install this via Python's pip3 and virtualenv facilities. A % pip install torch is the only new module needed.
Q. Can I retrain the model?
A. Absolutely. We envision a model being trained on batches of test runs, periodically catching up with newer data. A model trained on a large corpus does not have to be up to date with all recent test runs to infer high-quality predictions on brand new ones.
Try it live: Sourceware Buildbots
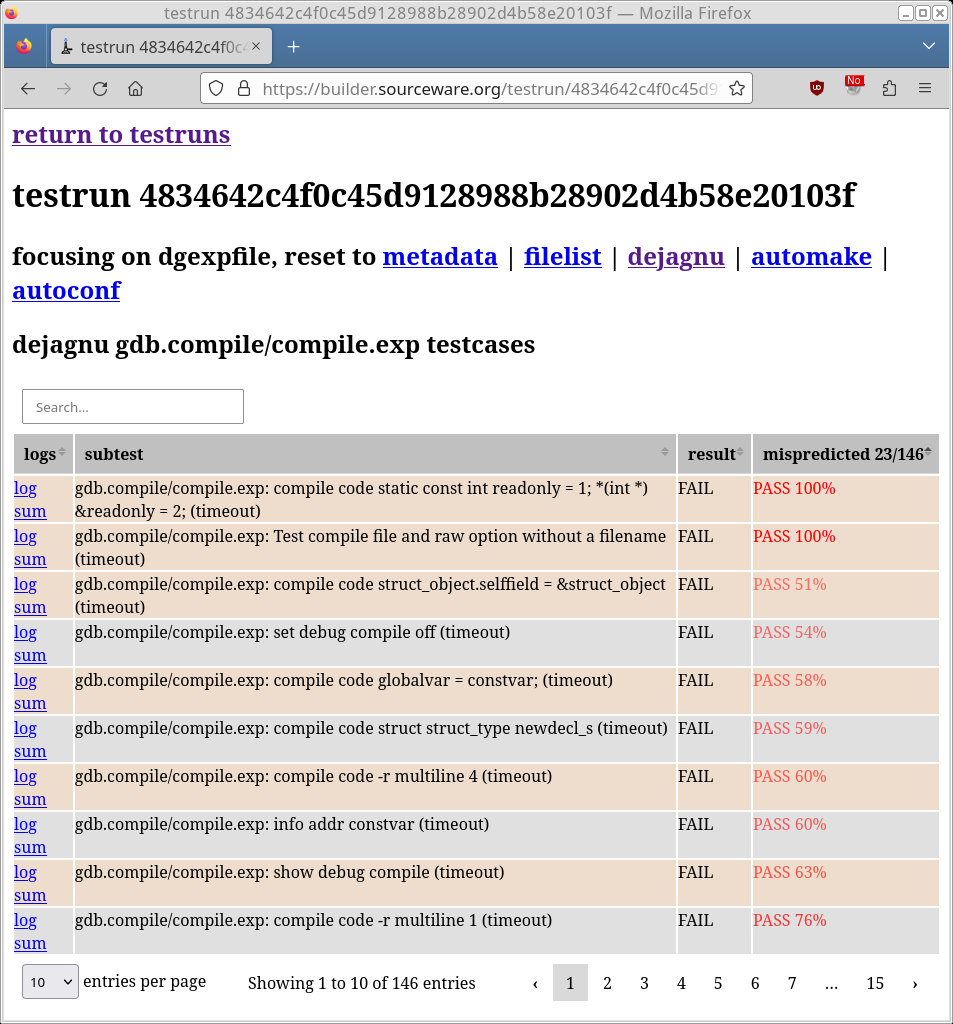
The AI/ML engine is already running on our showcase sourceware.org server. The AI/ML predictions are shown on the DejaGnu panels, highlighting "mismatches" (Figure 3).
Try it at home: Containers
Being a Python 3 toolkit, you can easily build Bunsen on a Fedora or RHEL 8+EPEL system. The previously published Bunsen container image is now updated with PyTorch on a Fedora 37 base:
% podman run --rm -i -t quay.io/bunsen-testsuite-analysis/bunsen /bin/sh
sh-5.1% ls /usr/local/bin/r-dejagnu-testsuite-classifyLet's build more together
We encourage you to get in touch with the team at bunsen@sourceware.org if you find the tool interesting and useful, or if you need something it doesn't do yet. We have planned several usability and analysis improvements this year.
Last updated: November 5, 2025