The Red Hat Data Grid is a hosted data storage platform that offers different levels of caching for fast access to data in memory. Well-chosen indexes allow the data store to fetch results faster than non-indexed caches. This article demonstrates how to create indexes in Data Grid and use them in a Java application built on Spring Boot. Then we will run and test the application in a container on Red Hat OpenShift.
Understanding indexed cache structure
To use indexing, you need to define the indexed entity both in Data Grid and on the application side. The example in this article uses a Book entity, shown in Figure 1.

The Book structure needs to be mapped on either side of the communication, as a Java object in the application (Book.java) and as a Protocol Buffers (protobuf) schema in the cache. Figure 2 shows the relationship between all the components using the cache.
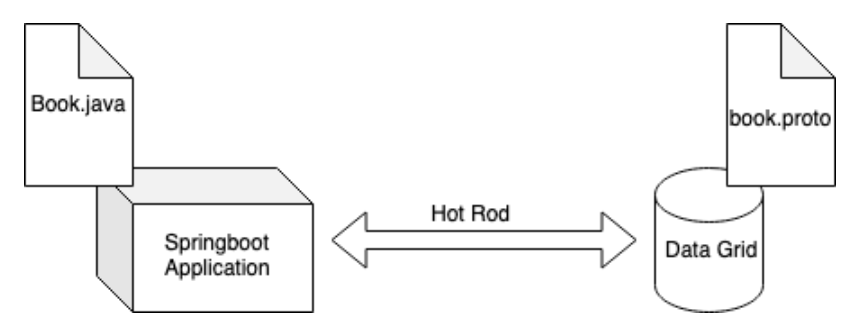
The Book.java class defines the Book entity fields using the @Protodoc and @Protofiled annotations as follows:
package com.redhat.dg8remote.controller;
...
@ProtoDoc("@Indexed")
public class Book {
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)")
@ProtoField(number = 1)
String title;
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)")
@ProtoField(number = 2)
String description;
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)")
@ProtoField(number = 3, defaultValue = "0")
int publicationYear;
@ProtoFactory
Book(String title, String description, int publicationYear) {
this.title = title;
this.description = description;
this.publicationYear = publicationYear;
}
}
The book.proto schema file defines the same fields as Book.java does, but using the syntax for a protobuf schema:
syntax = "proto2";
package book_sample;
/**
* @Indexed
*/
message Book {
/**
* @Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)
*/
optional string title = 1;
/**
* @Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)
*/
optional string description = 2;
/**
* @Field(index=Index.YES, analyze = Analyze.YES, store = Store.NO)
*/
optional int32 publicationYear = 3 [default = 0];
}
To use indexes, you also need to make changes in the XML definition of the Data Grid cache.
First, you need to add an <indexing> element. This element causes the data marshaling process to use the ProtoStream library to handle protobufs. Then, define the <indexed-entity> element referring to the <package>.<entity-name> structure.
For the current article the indexed cache should be configured as follows:
<replicated-cache name="books" mode="SYNC" statistics="true">
<indexing enabled="true">
<indexed-entities>
<indexed-entity>book_sample.Book</indexed-entity>
</indexed-entities>
</indexing>
</replicated-cache>
Note that the default cache encoding is application/x-protostream. Therefore, no additional elements are required for this cache configuration.
The remote query application
The current query demo application is based on the example provided in the Data Grid documentation section Querying caches from Hot Rod Java clients. I have adapted this application and configured it to run as a Spring Boot application. The application can run standalone or be deployed in a containerized environment such as OpenShift. The code source can be found in the dg8remote demo project on GitHub.
The application defines three classes for remote query and entity definition. A fourth class implements data marshaling (Figure 3).
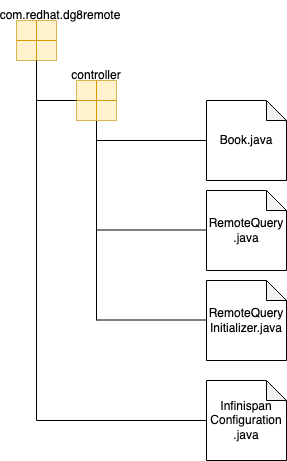
The classes have the following purposes:
- Book.java: Contains the fields for the Book entity. Each field has
@Protodocand@Protofieldannotations for indexing purposes. - RemoteQueryInitializer.java: An interface that contains the protobuf schema details, such as a
Bookclass reference for automatic proto file generation, package name, proto file name, and path. - RemoteQuery.java: Contains the exposed REST service that returns the query results. The constructor uploads the generated
book.protofile in the Remote Data Grid instance. This class also tells the compiler to generate aRemoteQueryInitializerImpschema. - InfinispanConfiguration.java: Adds a marshaller, which is needed in the client to serialize the application's object.
Running the remote query service
For the current demo, deploy the Data Grid cache cluster and the remote query service on OpenShift. The caches and the service are in separate projects, just like the original version of the application described in the article Integrate a Spring Boot application with Red Hat Data Grid.
Environment details
I used the following versions of the components that make up this example:
- Red Hat Data Grid 8.3
- Red Hat OpenShift 4.10
- Spring Boot 2.7.2
- Java 11
Defining the Data Grid cluster custom resource
The previous article explains how the Data Grid cluster is generated using an Operator. We have to make one change in our example to expose the cluster through the LoadBalancer. Here is how our configuration looks:
apiVersion: infinispan.org/v1
kind: Infinispan
metadata:
name: infinispan-test
namespace: dgtest
spec:
expose:
type: LoadBalancer
service:
type: DataGrid
replicas: 2
Creating the book cache
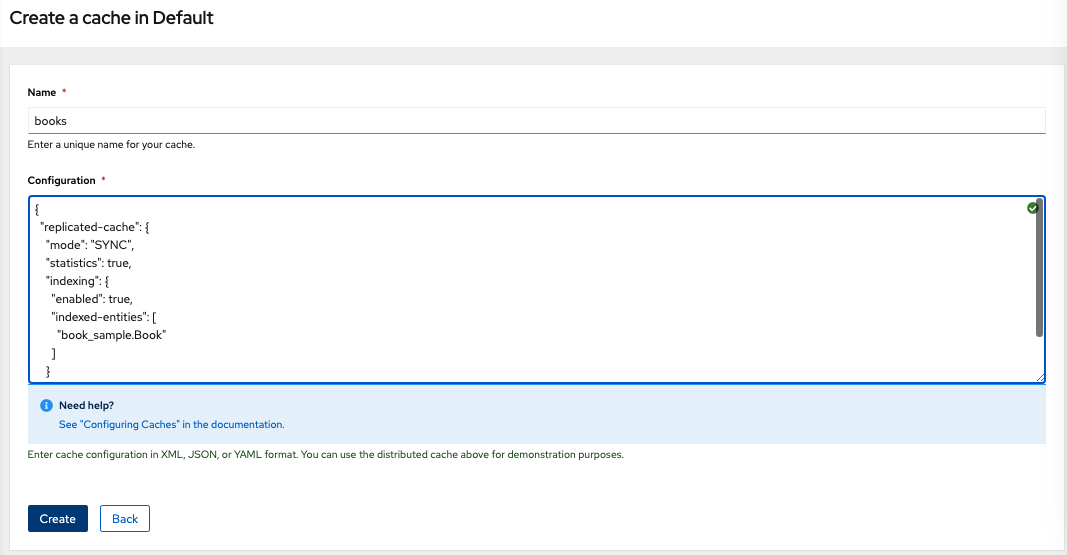
To create the cache, go to the Data Grid Web Console in a browser, then create a custom cache named books using the following JSON code. Include the book_sample.Book indexed entity as shown. Figure 4 shows where to enter the JSON.
{
"replicated-cache": {
"mode": "SYNC",
"statistics": true,
"indexing": {
"enabled": true,
"indexed-entities": [
"book_sample.Book"
]
}
}
}
Finish by clicking the Create button:
There are other ways to create caches, detailed in Data Grid Documentation.
Configuring the application to use the data grid cluster
Clone the remote query service project:
$ git clone -b openshift https://github.com/alexbarbosa1989/dg8remote
Refer to Integrate a Spring Boot application with Red Hat Data Grid and follow the instructions in Gather relevant Data Grid cluster data and How to deploy the Spring Boot project. The application.properties file should look like the following:
# context-path
server.servlet.context-path=/redhat
# allow all endoints exposure
management.endpoints.web.exposure.include=*
# Connection
infinispan.remote.server-list=181.123.123.123:11222
infinispan.remote.client-intelligence=BASIC
# Authentication
infinispan.remote.use-auth=true
infinispan.remote.sasl-mechanism=BASIC
infinispan.remote.auth-realm=default
infinispan.remote.auth-server-name=infinispan-test
infinispan.remote.auth-username=developer
infinispan.remote.auth-password=ygwaioo0XWhxMtBU
infinispan.remote.sasl_properties.javax.security.sasl.qop=auth
# Encryption
infinispan.remote.sni_host_name=181.123.123.123
infinispan.remote.trust_store_file_name=/mnt/secrets/truststore.jks
infinispan.remote.trust_store_password=password
infinispan.remote.trust_store_type=jks
# Marshalling
infinispan.remote.marshaller=org.infinispan.commons.marshall.ProtoStreamMarshaller
infinispan.remote.java-serial-allowlist=com.*,org.*
infinispan.remote.java-serial-whitelist=com.*,org.*
infinispan.client.hotrod.marshaller=org.infinispan.commons.marshall.ProtoStreamMarshaller
infinispan.client.hotrod.java_serial_allowlist=com.*,org.*
infinispan.client.hotrod.java_serial_whitelist=com.*,org.*
Because we are using the LoadBalancer, the infinispan.remote.server-list property has an assigned external IP address for the data grid service, exposed by OpenShift, instead of the SVC name rendered by DNS that appeared in the original version of the application. You can the IP address using the following command:
$ oc get svc |grep external
infinispan-test-external LoadBalancer 10.20.21.22 181.123.123.123 11222:30890/TCP 22m
Deploying the remote query application in OpenShift
After updating the properties file, it's time to create a new OpenShift project. You can create it in the same OpenShift cluster where the Data Grid cluster is running or in a different remote cluster. A remote cluster can be used because you have external access to the Data Grid cluster via LoadBalancer:
$ oc new-project springboot-test
Now, you can deploy the remote query application. Take care to run the following command from the application's new OpenShift project, which you can get into using the oc project springboot-test command. Compile and deploy the application as follows:
$ mvn clean fabric8:deploy -Popenshift
Finally, create a secret that will store the Keystore generated in the previous step:
$ oc create secret generic truststore-secret --from-file=truststore.jks
$ oc set volume dc/hotrodspringboot --add --name=truststore-secret -m /mnt/secrets/ -t secret --secret-name=truststore-secret --default-mode='0755'
Testing the remote query
Once you have deployed the application, you can test the remote query integration. You must get the exposed route for the service by using the oc get routes command. Here is the output:
$ oc get routes
NAME HOST/PORT
remote-query remote-query-springboot-test.openshiftcluster.com
PATH SERVICES PORT TERMINATION WILDCARD
remote-query 8080 None
Send a request to the REST endpoint for the service using the curl command:
$ curl -X GET http://remote-query-springboot-test.openshiftcluster.com/redhat/query-cache/
- Book title 10 - 2022%
Let's understand what happened when you invoked the/query-cache service. First, as mentioned earlier, the Data Grid cluster imported the book.proto structure to get the data structure needed to process the request from the remote query service. The proto.book file was generated when you compiled the RemoteQueryInitializer.java class. The RemoteQuery.java constructor uploads the proto.book file into the Data Grid cluster. The following code in the RemoteQuery class puts that generated schema into the Data Grid cluster's cache data structure:
public class RemoteQuery {
...
@Autowired
public RemoteQuery(RemoteCacheManager cacheManager) {
...
GeneratedSchema schema = new RemoteQueryInitializerImpl();
metadataCache.put(schema.getProtoFileName(), schema.getProtoFile());
}
...
}
Having the schema mapped on both sides, as shown in Figure 2, the service uploads a set of Book objects into a Map and stores them in the Data Grid cache.
Data Grid executes the query and put the resultset into a List of Book objects. This query gets all books that contain the characters '10' in their titles:
QueryFactory queryFactory = Search.getQueryFactory(remoteCache);
Query<Book> query = queryFactory.create("FROM book_sample.Book WHERE title:'10'");
List<Book> list = query.execute().list();
Our example performs both the data load into the cache and the query in the same /query-cache service for the purpose of simplicity. However, each step could also be performed in different services, depending on the use case and application architecture.
There are also multiple ways to perform queries. The Ickle query syntax is explained in the Data Grid documentation.
Adding indexes to Data Grid is easy and beneficial
This article demonstrated how you can easily add Indexes to Data Grid. Indexed caches offer benefits such as:
- Remote queries
- Supports more complex data based on entities with multiple fields.
- A broad range of query alternatives, shaped according to each use case.
The official product documentation contains details about indexing in Red Hat Data Grid. Please comment below if you have questions. We welcome your feedback.
Last updated: September 20, 2023