This article is the second installment of a series that helps you choose among the many open source integration runtime provided by the Apache Camel framework. Part 1 of the series introduced the landscape of Camel runtime options and explained the use case and historical needs addressed by each runtime. This article expands on the advantages and recommended uses for the main runtimes currently supported by the Apache Camel project: Apache Karaf (OSGi), Spring Boot, Quarkus, and Camel K.
Camel's light footprint and versatility also allow for other types of deployment. For instance, you might embed Camel directly as a library to empower your existing application with integration abilities. Or, for similar reasons, you might deploy Camel in an existing web container.
This series doesn't intend to enumerate all the available Camel permutations. We're simply covering the most common community-supported runtimes to run Camel in the enterprise, whether standalone or using a containerized environment such as Kubernetes.
Camel Karaf (OSGi)
From a technical viewpoint, to gain unlimited access to the full power of Camel to tackle all use cases, from the most basic to the most challenging ones, Karaf is the more capable of all the Camel runtimes. The core ability of Karaf's underlying standard, OSGi, is to host many independent modules (bundles), each one loaded by its privately assigned class loader, which allows you to run multiple Camel projects simultaneously. The comprehensiveness of the OSGi solution allows numerous CamelContext instances to coexist under the same JVM and to communicate with one another.
If you want maximum control and intend to implement many services, OSGI seems like the right choice. It's important to note, though, that exploiting OSGi's special powers might create difficulties if down the line you plan to transition to containers. On the one hand, OSGi encourages you to modularize your services well, which helps you adopt a microservices mindset. But if you're not cautious, you might lock yourself into the technology.
Camel Spring Boot
OSGi proved to be overwhelming for many developers, especially inexperienced ones, who prefer simple runtimes where only a single service (CamelContext) runs. These developers gravitated to Camel in Spring Boot, which sacrifices the ability to bundle multiple services together, but still tapped into most of Camel's flexibility and functionality and provided much simpler dependency management.
Spring Boot offers advantages, among other areas, in easier development, autoconfiguration, and more straightforward setup and management, all significantly contributing to its popularity.
Camel on Spring boot has become the most attractive option when deploying in container environments because of its one-Camel-per-instance simplicity. However, as pointed out in Part 1 of this series, running many Spring Boot microservices becomes expensive; its footprint is too big in comparison with non-Java runtimes that are better adapted to the needs of container environments.
Camel Quarkus
Camel Quarkus is the latest Camel runtime generation. It allows you to run integration processes with super low memory usage, fast startup, and outstanding performance. The article Boost Apache Camel performance on Quarkus introduces the topic well.
Like Spring Boot, Quarkus runs a single CamelContext runtime. Although Quarkus doesn't provide you with the unique characteristics that OSGi offers to contain many Camel instances, Quarkus runs standalone both outside and inside containers.
Camel Quarkus requires the latest version of Camel (version 3), whose use is encouraged for all Camel users anyway. If you happen to depend on Camel 2, you'll have to choose a different runtime and forego Quarkus's compactness.
Camel Quarkus is also the base runtime for Camel K, which I'll explain in detail in the following section.
Camel K: Operator-based Camel
With generic Camel and Camel Quarkus, developers have complete framework control at their disposal. In more specific terms, the developer has full access to the CamelContext and can, for instance, wire in Java beans and use them in Camel routes. In other words, the developer rides the Camel.
In contrast, with Camel K, the Operator takes the reins (Figure 1). Camel K introduces abstraction layers to make Camel easier for the end-user and consequently needs to take over some control from the developer. It's a compromise you could accept to enjoy a more user-friendly experience.

{kind=link}
The following subsections describe three levels of abstraction that you can achieve using Camel K.
Abstraction 1: Improved developer experience
To start with, Camel K encourages you to create a single file to implement your Camel routes. You might have to include extra resource files (typically to help configure your endpoints), but that's about it: No project trees, no dependency descriptors (e.g., POM files in Maven).
The sweet spot of Camel K is connectivity or event-driven use cases, from source to target, where process/data mediation may be necessary. If you find that your use case requires higher complexity, perhaps with more than one or two target endpoints, Camel K may still be suitable, but probably you should rely on traditional Camel using Quarkus.
Abstraction 2: Kamelets
A second abstraction layer, introduced by Camel K, involves Kamelets, which are essentially predefined route snippets. A Kamelet typically uses a Camel connector (component) with additional logic. By enriching standard Camel connectors, Kamelets effectively become "intelligent connectors" convenient to have as reusable building blocks that you can invoke in a single line from your Camel code.

Figure 2 portrays a Kamelet metaphorically as a smart encapsulated device that plugs by default into a network socket, that is, the standard Camel component from where the data originates. Think of the pluggable device as a preprogrammed connector with added intelligence.
Camel K provides a whole collection of Kamelets out of the box. You can browse its catalog and pick the Kamelet that fits your use case. A valuable benefit to consider is that you can also create your own Kamelets, customized to your team's needs, effectively composing a catalog for your organization.
Kamelets are great to use as generic sources and sinks (illustrated in Figure 3) and are also ideal building blocks for low-code and no-code web and graphical user interfaces. Because of Kamelets' atomic encapsulation, you can just specify some parameters in their environment to configure them. The pluggable aspect of Kamlets enables the next abstraction level in Camel.

Abstraction 3: Kamelet bindings
A third abstraction layer consists of Kamelet bindings. As the name suggests, Camel K allows you to plug Kamelets together, typically a source and a sink, to form a processing chain that enables an integration data flow between a source system and a target system (see Figure 4).
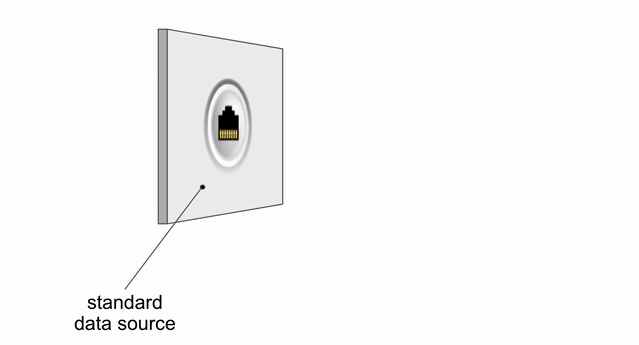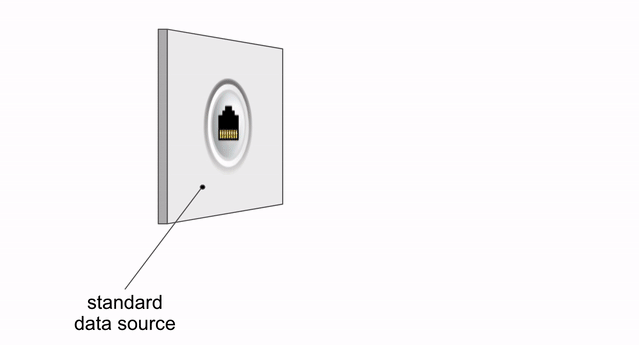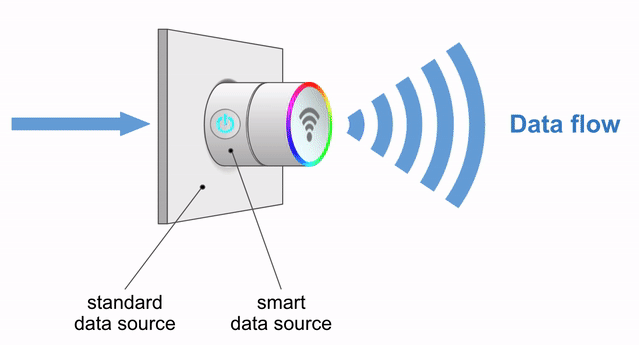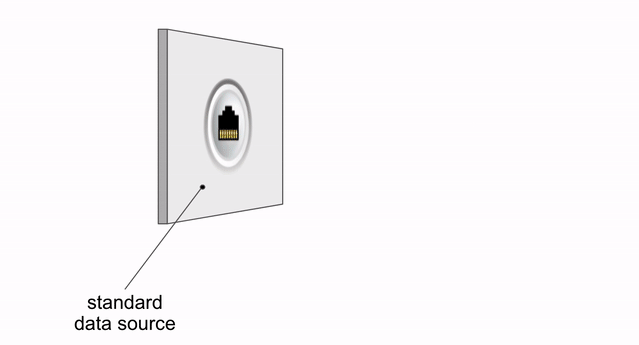
You could implement the same processing flow with plain Camel code, but the power of Kamelet bindings lies in relieving you from coding the flows; you're only selecting and configuring reusable components. Kamelet bindings translate into deployed executable instances that Camel K operates, whereas Kamelets are passive entities in a catalog.
Because Kamelets represent reusable connectors requiring just configuration, Kamelet bindings are inherently no-code definitions (in YAML) with just input parameters. It's easy for anyone with access to an environment powered by Camel K to quickly compose a Kamelet binding by pairing a source Kamelet with a sink Kamelet and populating their parameters. The Operator will ride the Camel and deploy a running instance that complies with your definition.
For example, imagine that you pick the Twitter source Kamelet and the Kafka sink Kamelet from the catalog and bind them together (Figure 5). The moment you push its YAML definition to Kubernetes, the Camel K Operator reacts by deploying an integration process that goes live. A data stream of tweets starts flowing from Twitter to Kafka.

Up next
This article covered the main advantages of the major runtimes currently supported by open source communities, as well as comprehensive information on the most innovative runtime, Camel K.
The final installment in this series will offer a quick guide to help you organize your criteria and choose the best Camel to ride.
Learn more about Camel Quarkus and Camel K
See the following resources to learn more about Camel Quarkus and Camel K:
- Explore in more detail Camel Quarkus by reading Boost Apache Camel performance with Quarkus.
- Read the article Improve cross-team collaboration with Camel K to learn about Kamelet bindings and the DSL.
- Learn how to implement a complete API integration using Camel K and AtlasMap.
- A good place to start learning about Camel K is the Camel K topic page on Red Hat Developer.
- Visit the Red Hat Integration page on developers.redhat.com to see complementary capabilities around Camel.