Ever wondered how your JavaScript code runs seamlessly across different platforms? From your laptop to your smartphone to a server in the cloud, the Node.js runtime ensures that your code is executed flawlessly regardless of the underlying architecture. What’s the magic that makes that possible? It’s the V8 JavaScript engine.
This article discusses how our team enhanced V8 to handle certain platform differences, notably big-endian versus little-endian byte order.
The V8 JavaScript engine and IBM processors
The V8 JavaScript engine is the core technology that translates your JavaScript source code into machine instructions. V8 is an open source JavaScript and WebAssembly engine, used in the Google Chrome web browser and in Node.js.
Behind the scenes, the Red Hat Node.js team is a major contributor to the V8 project. We ensure that the latest V8 releases are fully compatible and optimized for the IBM Power processor (Linux and AIX operating systems) and the IBM Z processor using the s390x architecture (Linux operating system). In fact, we have gotten the chip developers to add new hardware instructions that improve V8 performance on these systems. Examples include new arithmetic instructions in the IBM z14 designed specifically to improve pathlength for overflow checks in V8’s internal small integer representation, and prefixed instructions on Power10 for better constant handling (detailed later in this article).
Although a runtime like Node.js frees you from working at the machine level, knowing what's going on at that level can help you debug issues you might encounter. This is true for JavaScript as well as for any other language or runtime that you might use across different platforms.
Now we'll highlight some of the differences between the platforms on which V8 runs. We will focus on the Power and Z platforms, sometimes contrasting them with Intel's x86-64.
PowerPC fixed-length instructions on V8
PowerPC is a RISC architecture that defines a fixed instruction length of 4 bytes. This design helps keep the instruction set simple and makes code generation easier. Let's take a look at addition as an example to see how it works.
Assume you want to add two numbers in JavaScript:
let t = a + 6;
The a+6 expression maps nicely to the Add Immediate PowerPC instruction (addi), whose 4-byte layout is shown in Figure 1.

This instruction encodes a 2-byte immediate value in the SI field, adds it to the content of the RA register, and puts the result in the RT register.
Assuming that the value of a is in register RA, V8 can generate the addi instruction with the constant value 5 in the SI field and store the sum into register RT. In this example, the constant 5 fits into the 16 bits of the SI field. However, special handling is required if the constant value we are adding exceeds 16 bits.
One technique to handle this scenario is to divide the constant value into chunks and use separate instructions to update individual chunks before concatenating them at the end. The multiple instructions in this technique add pathlength and have a negative impact on performance.
An alternate and more performant technique, implemented in V8, is to use a constant pool. Essentially, a region of memory is allocated to hold 8-byte constant values with a dedicated register (r28) pointing to this area at all times, as displayed in Figure 2.
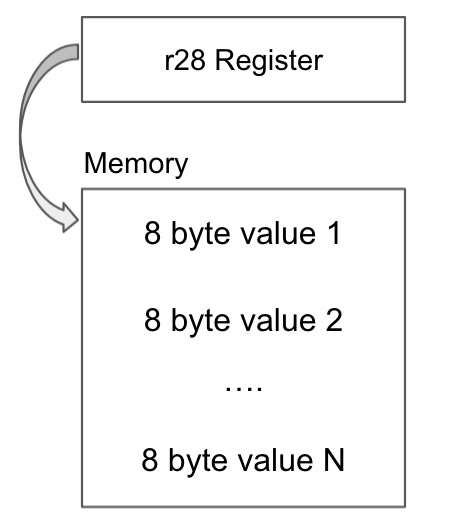
During code generation, the engine checks the size of constants. If their size exceeds the limit, the engine places them into this region and emits a single load instruction to load the constant value from this location, given an offset at runtime.
The Power10 has introduced a set of new prefixed instructions that can extend the instruction length to 8 bytes. This allows for larger immediate values to be encoded in an instruction, which in turn reduces the use of constant pools and gains even better performance.
Big-endian byte order on V8
x86-64 has a little-endian byte order. This means that data larger than a byte has to have its bytes switched around as it moves between the processor and memory. However, the z/Architecture used by IBM Z (s390x) platforms are big-endian, which means data is stored in the same order as it was in a CPU register. (This order is also called network byte order because it is specified for all traffic on the internet.)
The difference in endianness can be viewed in JavaScript using typed arrays:
let buffer = new ArrayBuffer(16);
let int8View = new Int8Array(buffer);
let int16View = new Int16Array(buffer);
int16View[0] = 5;
console.log(int8View[0]);
This example stores a 2-byte (16-bit) constant value of 5 in memory and reads the result in single-byte chunks. The code outputs 5 on little-endian machines because the 2-byte value is reversed when stored in the buffer variable in memory. Big-endian machines, however, print 0 because the byte order remains unchanged when storing data.
Compiling a WebAssembly binary
Our team often applies patches to make sure V8 remains compatible on big-endian platforms and is endian-agnostic to the end-user.
This task becomes more challenging when compiling a WebAssembly (Wasm) binary, because the Wasm specification dictates a little-endian memory model. This means that when storing data in memory, V8 has to put it in little-endian order even on big-endian platforms.
V8 detects if the target platform is big-endian and, if so, adds a byte reverse instruction to every load and store. As you can, imagine this imposes a significant performance drawback on big-endian platforms because every load and store instruction is accompanied by a byte reverse instruction that is not needed on little-endian platforms.
Fortunately, both z/Architecture and big-endian PowerPC have instructions to load and store data in little-endian order. We detect if a load/store is being done during Wasm compilation and emit a single instruction to load/store data in reverse to mimic the behavior on x86-64 without incurring any extra instruction overhead.
With the addition of single instruction multiple data (SIMD) and vector instructions to s390 and their usage in Wasm, our load/store feature was later extended to include vector load/store instructions on PPC and s390.
Conclusion
This article was a short overview of Node.js "behind the scenes" on certain key platforms. Our aim is to make sure Node.js and V8 remain compatible with PowerPC and s390 and maximize V8's performance by exploiting the functionalities provided by these platforms.
We hope our brief intro piqued your interest. Working at the machine and operating system levels is pretty interesting, and contributing to the platform-specific components of Node.js (V8 and libuv) is a great way to learn more about what goes on under the covers.
To learn more about what Red Hat is up to on the Node.js front, check out our Node.js topic page. You can also peruse the IBM Power ISA V3.0B specification.
Last updated: January 5, 2023