Page
Understand and implement RAG on OpenShift AI
Before we can put it into practice, it’s important to understand how RAG works. In this section, we describe a typical RAG workflow and explain the steps required to implement RAG on top of OpenShift AI.
In order to get full benefit from taking this lesson, you need to:
- Access to an OpenShift cluster with OpenShift AI installed on it.
In this lesson, you will:
- Implement RAG on top of OpenShift AI.
RAG workflow
Figure 1 depicts a typical RAG workflow.
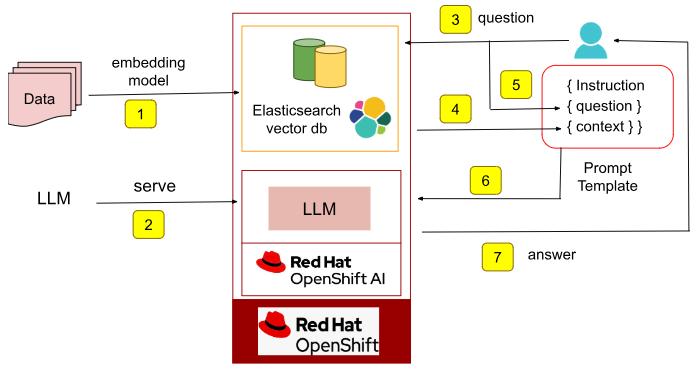
The phases shown in Figure 1 are as follows:
- Data gets stored in a vector database. A machine learning model is used to derive the vector representation of the data and is then indexed into the vector database of choice. In this example, we are using an Elasticsearch vector database.
- The user serves an LLM of their choice on Red Hat OpenShift AI. This could be an LLM developed from scratch on top of OpenShift AI or an open source model. In this example, we are using the Mistral AI model from Hugging Face.
- The user asks the model a question.
- A search is initiated into the vector database to retrieve information relevant (context) to this question.
- The instruction, question, and context together make up the prompt.
- The LLM then uses the prompt to generate a more relevant and accurate answer.
- The answer is returned to the user.
Implementation with OpenShift AI and Elasticsearch
Now that we understand the basic RAG workflow, we are ready to implement RAG on top of OpenShift AI. Below, we describe the steps required to accomplish this. We assume that the user has access to an OpenShift Cluster with OpenShift AI installed on it and is working in the dashboard.
Step 1: Create a Data Science project
Create a data science project titled myRAG in OpenShift AI as shown in the product documentation.
Step 2: Create an S3 backend to store the model
Normally, you would have an existing database to use, but for the purpose of this learning path, we have a script you can use to set one up. To do this, you will need to go to your OpenShift console (not within OpenShift AI). Once you are in your OpenShift console:
- Select your
myRAGproject. - Make sure you are in the +Add section within the OpenShift console.
- Select Import YAML.
- Either drag and drop https://github.com/rh-aiservices-bu/rag-with-elasticsearch/blob/main/setup-s3.yaml or copy and paste the contents of this file into the Import YAML box.
- Click Create.
This will create an S3 object store needed to store the LLM. To serve LLMs with OpenShift AI, models must be stored in such object stores. Model servers in OpenShift AI then reference these stored models when serving them
Step 3: Download a model and upload it to an S3 bucket
In your OpenShift AI console, create a workbench using JupyterLab IDE by following the instructions in the product documentation. It is important to:
Connect the workbench to the object store
My Storagecreated in Step 2 above.Allocate sufficient storage for a persistent volume claim (~100GB) to download the Mistral model.
Include an accelerator/GPU due to the compute-intensive nature of working with LLMs.
Open the JupyterLab IDE and clone the repo using the script I created below: https://github.com/rh-aiservices-bu/rag-with-elasticsearch.git
Install CLI and log in to Hugging Face
You will need to install the library to interact with the Hugging Face Hub and log in to Hugging Face in order to access the model. Use the below commands:
pip install huggingface_hub huggingface-cli loginUse a notebook to download the LLM
Download the Mistral model from Hugging Face using the notebook 1_download_save_model.ipynb. Note that the user must set the username and token in the notebook to access the model from Hugging Face. Replace
<user>and<token>with the appropriate values in the following command:git_repo = f"https://<user>:<token>@huggingface.co/mistralai/Mistral-7B-Instruct-v0.2"
Step 4: Install Elasticsearch
Elasticsearch Operator
Install the Elasticsearch (ECK) Operator as described in the Red Hat container catalog.
Deploy Elasticsearch
Deploy an Elasticsearch instance with a route as described in Elastic’s documentation.
Retrieve an Elasticsearch endpoint
Log in to the cluster via the OpenShift CLI (
oc cli). Then retrieve and test the Elasticsearch endpoint as shown in the steps below.Retrieve an Elasticsearch password
Retrieve the password with the following command:
[user~]$ PASSWORD=$(oc get secret elasticsearch-sample-es-elastic-user -o go-template='{{.data.elastic | base64decode}}')Retrieve Elasticsearch endpoint
Retrieve the endpoint with the following command:
oc get routesNAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD elasticsearch-sample elasticsearch-sample-elastic.apps.cluster-scclf.sandbox134.opentlc.com elasticsearch-sample-es-http <all> passthrough/Redirect NoneTest Elasticsearch endpoint
Use the following command to test the endpoint:
curl -u "elastic:$PASSWORD" -k "https://elasticsearch-sample-elastic.apps.cluster-scclf.sandbox134.opentlc.com" { "name" : "elasticsearch-sample-es-default-0", "cluster_name" : "elasticsearch-sample", "cluster_uuid" : "bIMS8eUkSHaTEbRxXL--0w", "version" : { "number" : "8.14.1", "build_flavor" : "default", "build_type" : "docker", "build_hash" : "93a57a1a76f556d8aee6a90d1a95b06187501310", "build_date" : "2024-06-10T23:35:17.114581191Z", "build_snapshot" : false, "lucene_version" : "9.10.0", "minimum_wire_compatibility_version" : "7.17.0", "minimum_index_compatibility_version" : "7.0.0" }, "tagline" : "You Know, for Search" }
Step 5: Store data into Elasticsearch
The notebook 3_RAG_with_Elastic.ipynb contains code to store data into the Elasticsearch vector database as well as perform a query with RAG.
First, let us look at how data is converted to vector representation and indexed into the Elasticsearch database (Figure 2).
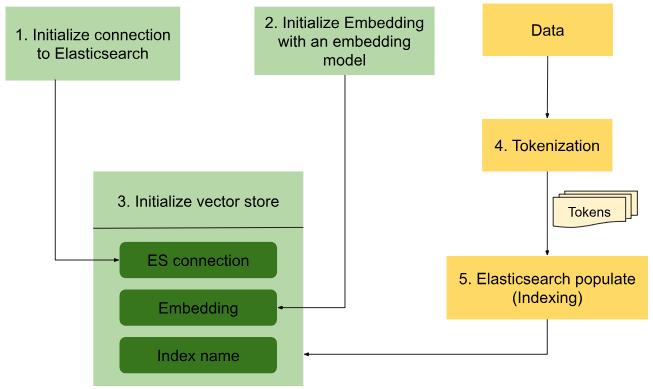
Below are some code snippets from the notebook 3_RAG_with_Elastic.ipynb that take care of loading the data as well as tokenizing and indexing the data into the Elasticsearch vector database:
1 | Initialize connection to Elasticsearch | |
2 | Initialize embeddings | |
3 | Initialize vector store | |
4 | Load data and tokenize | |
5 | Elasticsearch populate | |
Step 6: Serve the LLM in OpenShift AI
The next step is to serve the Mistral AI model on OpenShift AI. Apply the YAML file mistral-raw.yaml to create a custom LLM deployment and deploy the model that was downloaded into the object store in Step 3. Once deployed, retrieve the service endpoint for the model. For example, in our implementation, the endpoint looked like this: http://llm-predictor.myrag.svc.cluster.local:8080
Now that we have the model served, we can add the code to query the model with a particular request, using the notebook 2_vllm_rest_requests.ipynb. In this example, we are going to query the LLM's knowledge of OpenShift AI's support of GPU and other accelerators with the product. The code below shows the steps:
infer_endpoint = "http://llm-predictor.myrag.svc.cluster.local:8080"
infer_url = f"{infer_endpoint}/v1/completions"
import requests
def rest_request(prompt):
json_data = {
"model": "llm",
"prompt": [
prompt
],
..
…
}
response = requests.post(infer_url, json=json_data, verify=False)
return response.json()
prediction = rest_request("What accelerators are supported in openshift AI?")
predictionWhile the model answered the question, it is not completely correct. The model knows only about NVIDIA GPU support in OpenShift AI, when in reality, OpenShift AI also supports other accelerators. Let us see how we can improve the accuracy of the model output by using the information stored in the Elasticsearch vector store:
OpenShift AI currently supports TensorFlow Serving as its machine learning model serving accelerator.
TensorFlow Serving is an open-source serving system for machine learning models, built by Google and the
TensorFlow community. It converts TensorFlow models to serving formats that serve prediction requests in
high throughput, low latency, and with high availability. OpenShift AI also supports CUDA GPUs for training
and inference. So you can use NVIDIA GPUs to accelerate the training of machine learning models that use
TensorFlow or other deep learning frameworks such as PyTorch and MXNet that have CUDA GPU support.
For model serving, you can use TensorFlow Serving or other containerized serving systems that have
CUDA GPU support, such as TorchServe or other model serving frameworks that support CUDA GPUs.',Step 7: Question and answer with RAG
While we were able to use RAG to augment the LLM’s results with information on OpenShift AI, we will now use prompts to enhance it and produce even more accurate results.
Use the notebook 3_RAG_with_Elastic.ipynb to define a prompt template, which will contain the instructions on how to answer the question. We will include the question as well as the context that will be retrieved from the Elasticsearch vector store before answering the question:
template = """
### [INST]
Instruction: Answer the question based on your OpenShift AI knowledge.
Here is context to help:
{context}
### QUESTION:
{question}
[/INST]
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = VLLMOpenAI( … )
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=store.as_retriever( search_type="similarity", search_kwargs={"k": 4} ),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True
)
os.environ["TOKENIZERS_PARALLELISM"] = "false"
question = "What accelerators are supported on OpenShift AI?"
result = qa_chain.invoke({"query": question})In the above code, we can see that RetrievalQA, a question-answer chain from LangChain, retrieves relevant information from the Elasticsearch vector store using similarity search, and answers the question. See below:
OpenShift AI supports two types of accelerators for running machine learning workloads: NVIDIA graphics processing units (GPUs) and Habana Gaudi hardware processing units (HPUs). To use GPUs, you need to install the NVIDIA GPU Operator. For HPUs, you can use the Habana libraries and software associated with Habana Gaudi devices available from your notebook.The model answers the question more accurately this time. It uses information stored in the Elasticsearch vector store to report that OpenShift AI supports two kinds of accelerators namely NVIDIA GPUs and Habana Gaudi HPUs.
Conclusion
In this learning path, we explored the basics of RAG and showed how users can implement RAG to significantly improve the accuracy of LLMs using OpenShift AI as their choice of AI/ML platform and Elasticsearch database as the vector database.
For more information on Red Hat OpenShift AI, be sure to check out the following resources:
- OpenShift AI website, including a free trial:
- OpenShift AI on the Red Hat Developer Portal:
- OpenShift AI product documentation:
- Elastic in the Red Hat Ecosystem Catalog:
References
1. IDC FutureScape: Worldwide Artificial Intelligence and Automation 2024 Predictions, Doc #AP50341323, October 2023
