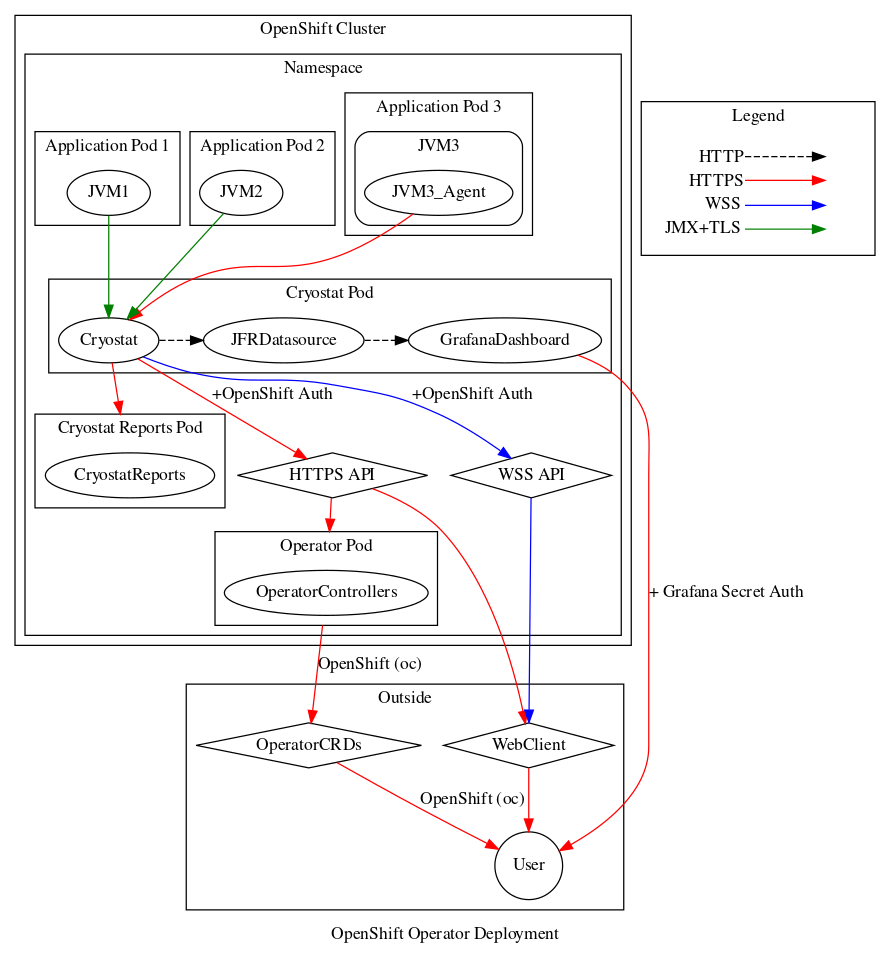
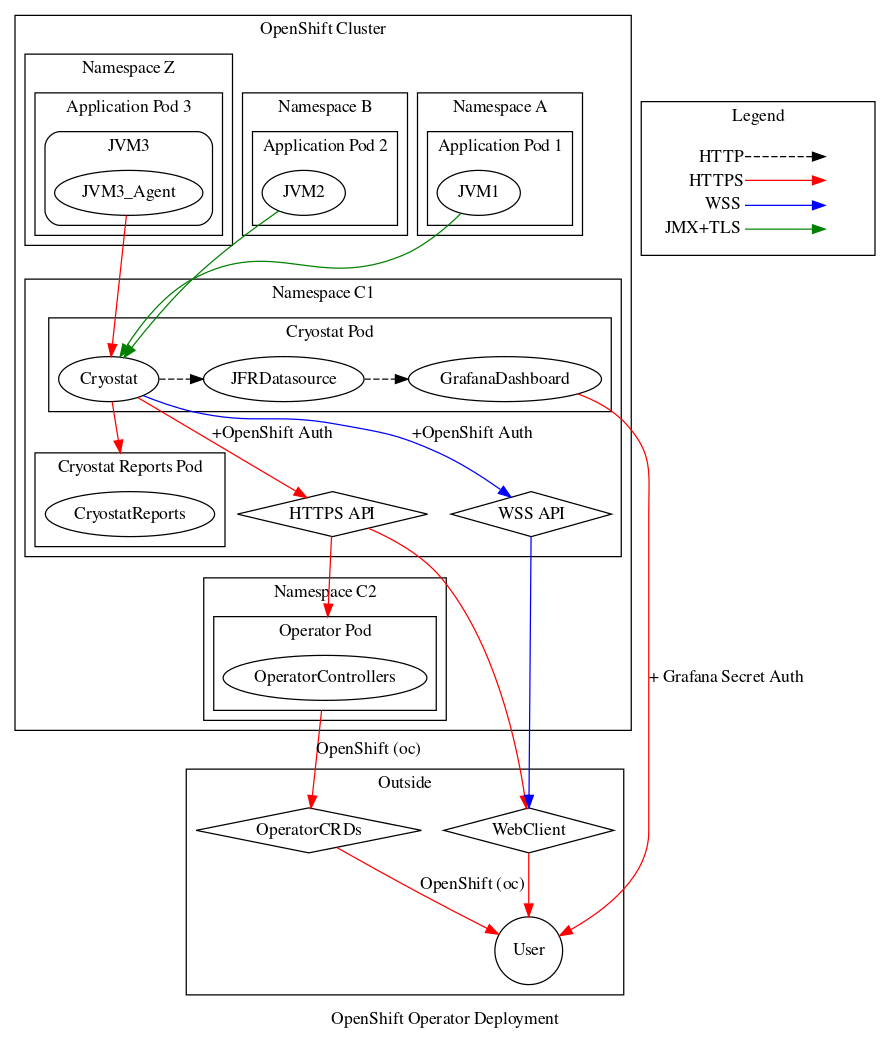
Cryostat 2.3 includes another popular community-requested feature: multi-namespace support*. With this release it is now possible to deploy a single Cryostat instance for monitoring and profiling Java application instances across all of your OpenShift projects, whereas previous Cryostat releases required you to deploy one Cryostat instance into each project. This is the first half of multi-tenant support in Cryostat.
* Kubernetes Namespaces are referred to as Projects in OpenShift Container Platform (OCP).
Before I continue, there is an important caveat to be aware of with this initial support. Cryostat 2.3 can be deployed such that it discovers target applications in multiple projects, but it does not silo the data. What this means is that any user who can access the Cryostat instance has access to all target applications in any project visible to that Cryostat instance. When deploying a multi-namespace Cryostat instance, administrators must be careful and considerate about which projects to select for monitoring, which project to install Cryostat into, and which users to grant access.
In order to deploy a new multi-namespace-enabled instance, users can create a new ClusterCryostat Custom Resource (CR) in OCP after installing or updating the Cryostat Operator. The old Cryostat CR is still available and is used for creating single-namespace Cryostat instances. The Cryostat Operator will warn the user and fail the deployment if there is a collision between a Cryostat CR namespace and the installation namespace or target namespaces of any ClusterCryostat CR.
The installation namespace of a ClusterCryostat is straightforward - it is the namespace (OpenShift Project) into which the Cryostat Operator will create a Deployment, Service, etc. for Cryostat and its associated components. This namespace should be separate from the target application(s), ideally reserved for the ClusterCryostat instance alone, and RBAC permissions within this installation namespace are how administrators can control which users have access to the instance.
The target namespaces of a ClusterCryostat are simply those namespaces within which the Cryostat instance attempts to discover target applications. This is still done in the Cryostat conventional way of querying for Kubernetes Endpoints objects that have a port with either the name jfr-jmx or the number 9091. This list of target namespaces may also optionally include the installation namespace, if you want Cryostat to be able to discover its own components as applications to be monitored.
What if the conventional Endpoints name and number querying mechanism does not suit your application deployment scenario? In this case, I recommend you use the new Cryostat Agent to instrument your workload containers. This is an easy to use implementation of the Cryostat Discovery Plugin API from the last 2.2.0 release, which also works across namespaces. If you exclusively use the Discovery Plugin API (via the Agent or otherwise) then you may choose to leave the target namespaces list empty. Otherwise, an application container could be discovered both via the Discovery Plugin and via Endpoint querying. This is generally harmless but may be cluttered and confusing.
If the Endpoints query-based discovery does suit your deployment scenario, why should you consider creating a ClusterCryostat rather than a simple Cryostat? This mainly comes down to overhead and operating costs. If your application deployment spans multiple namespaces, or if you have a team of developers with their own individual workspace namespaces (and no concerns about data visibility across them), then choosing to install a single ClusterCryostat rather than many Cryostats can add up to significant memory overhead savings and more efficient utilization of resources.