Introduction
One of the biggest challenges for developers to build mobile applications is data synchronization. It's the foundation for many different types of mobile applications, but it's very complicated and very hard to implement.
This can be even harder for enterprise developers, as often they have to make sure the data is not only synchronized to the server side of their mobile apps but also synchronized to the database backends of their enterprises, as demonstrated in this diagram:
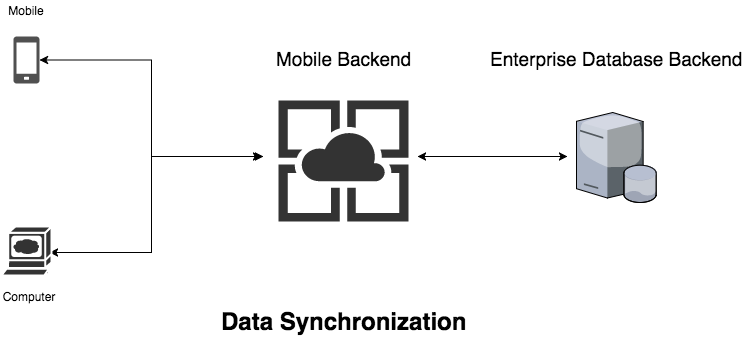
That's why we have built the sync solution on the Red Hat Mobile Application Platform (RHMAP). It's a framework that will enable developers to easily build mobile applications that will support data synchronization. It has been used by many of our customers in the last few years, with many depending on the sync solution quite heavily.
The framework consists of the following components:
- A suite of client-side libraries to manage data on different mobile platforms, including Android, iOS, NET, and Javascript.
- A server library that will handle the data synchronization between the mobile devices and the server, and between the server and the enterprise's backend databases. It's embedded as part of our cloud library.
Here is the high-level architecture of the sync framework:
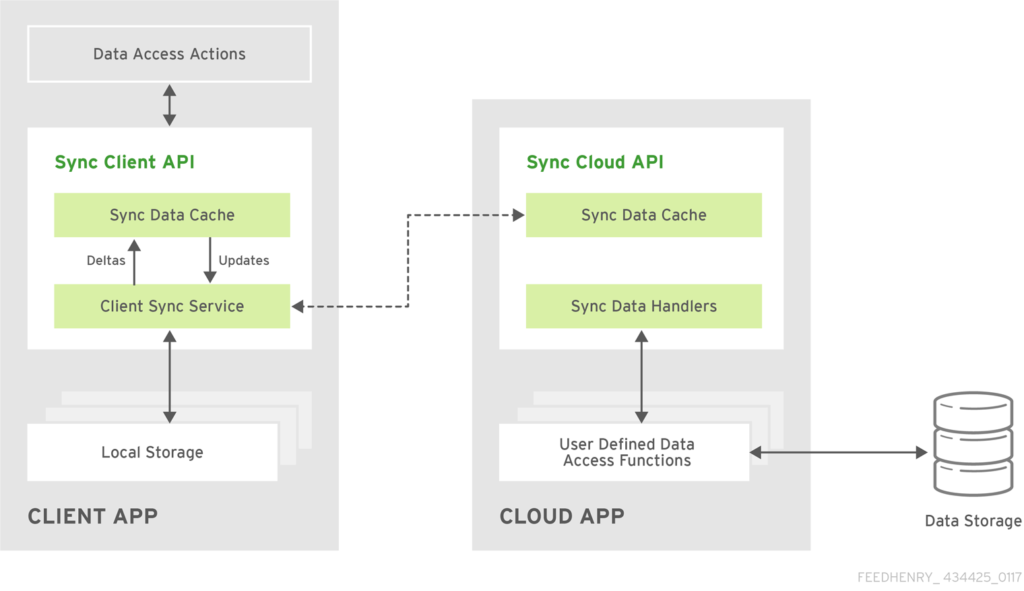
The Problem
Although the solution works fine for many of our customer's use cases, there is one problem with the server library: it doesn't scale. For performance reasons, the current implementation keeps a lot of data in memory, and that has sacrificed the ability to scale.
Recently this has become a blocker for one of our customers to roll out their mobile apps to more users, and we are determined to solve the problem for our customer. We set the goals of our work to be:
- Make the sync server library scale.
- At least as good as the current implementation for performance.
- Keep it backward compatible.
- Easy to debug and understand the performance.
The New Sync Server Implementation
We looked at the current implementation of the sync server, looked at what data was being kept in memory, and came up with an improved architecture of the sync server that will allow it to scale:
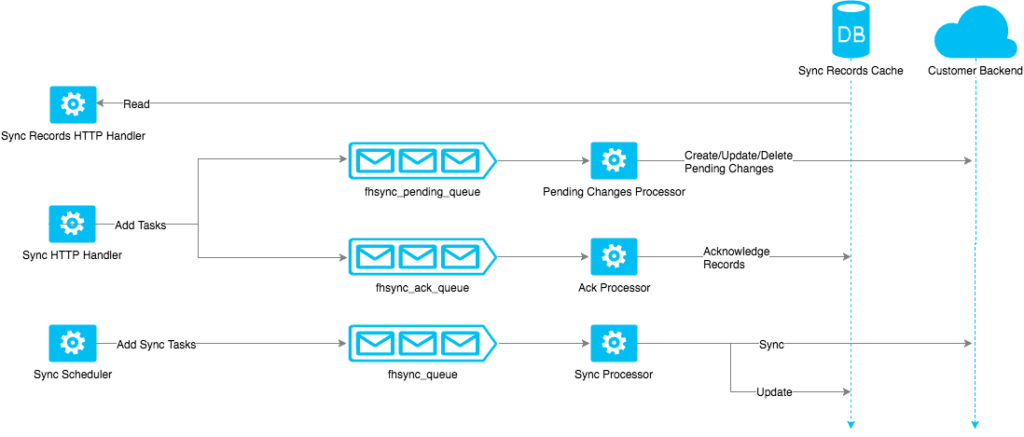
The main improvements of the new architecture include:
- Client requests with data are persisted first and processed asynchronously.
In the previous implementation, when the sync server receives sync requests from clients, it will keep the data in memory and try to process them before returning the response. This means that if a client uploads too much data for one request, it will cause the server to use more memory, with an increased chance of timing out. By writing the data to disk first, it solves those problems: it means the app will use less memory, the clients will get responses back very quickly, and the data can be processed by multiple processes.
You might think there should be a problem with this approach because the client won’t get the information about the changes it submitted immediately. But turns out this is not a problem because the client is designed to work with this case. The client only cares about the confirmation of the changes at some point eventually.
- Introducing a queuing mechanism to allow scalability.
As mentioned above, in the previous implementation, the HTTP request handlers will start to process the client request data immediately when the request is received. This means the request handlers are tightly coupled with the data processors. To avoid that, we introduced a queue mechanism. The HTTP request handlers will become the producer and they are only responsible for pushing the request data onto the queues, while the data processors becomes the consumer of the queues and they don’t need to care about who pushes the data to the queue. More importantly, it gives the sync server the ability to scale, for both the HTTP handlers and data processors. To avoid data loss, persisted queues are being used.
- Adding an extra layer of data caching.
Sometimes full dataset synchronization operations are required between the clients and the sync server. In the previous implementation, this is mainly done by listing the data from the backend database directly. The biggest problem with this approach is that the sync server becomes dependent on the backend database. The other problem is that when the sync server scales up in order to handle more clients, the backend database could be overloaded by the increased number of clients. So to help with those issues, we added an extra layer of data caching in the sync server. It will keep a copy of the backend data and sync periodically with the backend database. The sync operations between the cache and the backend database are queued as well, and a distributed locking mechanism is used to allow only one process run the sync operation at any time, to avoid any potential problem that could be caused by concurrency.
Performance Test
The new architecture of the sync server meets the requirements of scaling. But we also need to make sure its performance is at least on par with the previous implementation.
We conducted a series of tests to measure the performance of the new sync server. Each test script will do the following:
- Creates a record of ~1k payload size
- Waits for acknowledgment from server that it was processed (sync loop every 2 mins)
Send acknowledgment back to server - Updates a field on the record (~2k payload as pre & post object are included)
- Waits for acknowledgment from server that it was processed
- Send acknowledgment back to server
A test run will run this test script at a configured concurrency and for a specified number of times.
Here are some of the results from the performance tests. For simplicity, the results here are given as:
- Total time to execute all scripts
- Number of test scripts that completed successfully
Please also note that all the tests are done against relative modest hardware: the sync server is running inside a container with 2 vCPUs and 1G of memory. The test results may vary depending on the hardware you are using. Also In the ‘New Sync Server’ results, any success rate below 100% was due to an artificial timeout of 5 minutes built into the test script when waiting for a create or update to be processed. In those cases, the create or update was processed by the server eventually.
Here are the results of relative low concurrency tests:
| Concurrency | Number | Rampup | Num Workers | Num Datasets | Success | % Success | Total Time (ms) | |
| Old Sync Server | 200 | 400 | 200 | 1 | 1 | 400 | 100.00% | 127807 |
| New Sync Server | 200 | 400 | 200 | 1 | 1 | 400 | 100.00% | 466002 |
| New Sync Server | 200 | 400 | 200 | 2 | 1 | 400 | 100.00% | 492300 |
As you can see, in this scenario, the new sync server is taking a lot longer to complete the tests. This is mainly because the changes are processed asynchronously - the clients need to run extra loops to be notified of the updates. All the tests are running with a relatively high client sync frequency (2 minutes).
Then we increase the concurrency:
| Concurrency | Number | Rampup | Num Workers | Num Datasets | Success | % Success | Total Time (ms) | |
| Old Sync Server | 400 | 800 | 100 | 1 | 1 | 800 | 100.00% | 468953 |
| New Sync Server | 400 | 800 | 100 | 1 | 1 | 800 | 100.00% | 452833 |
| New Sync Server | 400 | 800 | 100 | 2 | 1 | 800 | 100.00% | 438612 |
As you can see, when the concurrency value is doubled, the old sync server is taking a significantly long time to complete the test, while the new sync server is using the similar time as the first test.
We then double the concurrency value again:
| Concurrency | Number | Rampup | Num Workers | Num Datasets | Success | % Success | Total Time (ms) | |
| Old Sync Server | 800 | 1600 | 200 | 1 | 1 | 262 | 16.38% | 658139 |
| New Sync Server | 800 | 1600 | 200 | 1 | 1 | 1600 | 100.00% | 503179 |
At this point, the old sync server will not be able to handle the load, and a lot of the requests failed. But the new sync server is still able to handle the load and can complete all the tests without taking extra time.
We then tried to push the concurrency even higher to see how the new sync server will perform:
| Concurrency | Number | Rampup | Num Workers | Num Datasets | Success | % Success | Total Time (ms) | |
| New Sync Server | 1600 | 3200 | 400 | 1 | 1 | 3200 | 100.00% | 645525 |
| New Sync Server | 1600 | 3200 | 400 | 2 | 1 | 3200 | 100.00% | 617976 |
| New Sync Server | 1600 | 3200 | 400 | 2 | 5 | 3186 | 99.56% | 3897898 |
| New Sync Server | 3200 | 20000 | 400 | 2 | 1 | 19993 | 99.97% | 2407943 |
Based on those test results, we can clearly conclude that the new sync server can handle much more load compared to the old implementation, and with the ability to scale to multiple workers/processes.
Our customer has also tested the new sync server and they are happy to see that the new implementation can support the number of clients they are targeting, without major changes to the existing solution.
Other Improvements
We also made other improvements to the sync server implementation.
- We added a lot more documents to our customer portal to explain the details about the sync solution. Including the details about the sync protocol, the various guides around debugging, logging, metrics, and APIs, etc.
- We also moved the sync server implementation to its own repo, with the hope that it will be useful to more developers, and build a community around it. The repo is located here and we are open to contributions.
Future Work
The work to improve scalability we have done so far sets up a solid foundation for our next generation of the sync solution. We will continue our efforts to improve our sync solution to make sure our developers can easily build mobile apps that can sync data, and it will be done in the open source way, with the help of the community. If you are interested, please join us and help make it better!
Red Hat Mobile Application Platform is available for download, and you can read more at Red Hat Mobile Application Platform.
Last updated: February 23, 2024