Automated software testing sometimes operates on the code as a black box. The tools build the software, run the test suites, and collect results. At minimum, the tools can report pass/fail numbers. Generally, the tools cannot understand the scores, such as the cause and effect relationships between upstream code changes, environmental factors, and the results. Therefore, a human is tasked with taking manual action, because the testing tools don't grok the upstream.
In this article, we'll look at how Bunsen, a lightweight test suite result repository and analysis engine, addresses this issue.
How Bunsen addresses this issue
Bunsen scales enough to track large and busy upstream projects with millions of unit tests and is still nimble enough to fit onto a single server with practically zero infrastructure. Recently, we have extended Bunsen with upstream analysis capabilities, which has resulted in neat labor-saving and automation, with more coming.
Our public Bunsen server is fed from a variety of automated builders and testers, including a local installation of buildbot. Hundreds or thousands of builds occur every day. These build and test runs have always collected complete logs, including build and environmental metadata that also identify the processed upstream Git repo/commit. The Bunsen tools have now started processing this upstream metadata and maintaining lightweight (blob-free) clones of upstream Git repos.
Examples
The first example sounds goofy on first blush. Left to itself, a firehose of test run archives would eventually consume all storage in the universe. We were informed that this is undesirable, so the Bunsen servers are configured to periodically age out data from its archives and index.
This is based on factors such as age and bulk, saving storage, and the world. However, we may want to keep some data indefinitely, such as tests of those builds that correspond to releases of upstream software. Many projects treat such test suite results—or at least result summaries—as precious artifacts that are useful for quality assurance of future major releases. But automatic aging based on age would clear them out without special treatment.
With manual input, Bunsen users could mark particular test runs for protection from aging, but now Bunsen knows upstreams. It can find out which builds correspond to tagged commits—those that the upstream community thinks are worthy of note—and protects them. No manual Bunsen side work needed!
The second example is a user convenience. In the Bunsen web interface, each bit of build/environment metadata associated with test runs is represented as plain text. Now, upstream-related metadata fields are rendered as clickable links to point at the upstream Git repo and the particular Git commit, if a gitweb or cgit like system exists for them. This makes manual test run analysis easier (Figure 1).
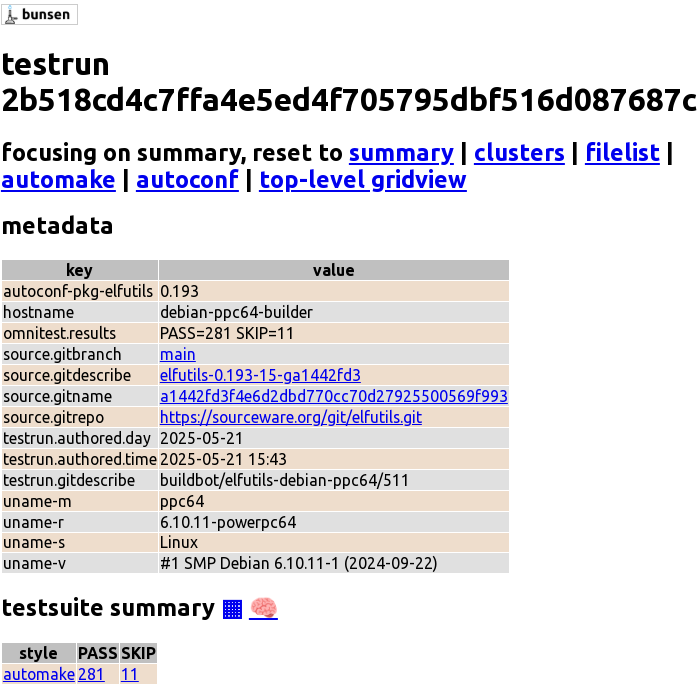
But what if we could reduce manual test run analysis? The holy grail of testing is identifying causes of test result effects. While Bunsen cannot know all the possible causes for an errant test, it does know some environmental metadata (like architecture, compiler versions, etc.).
We've previously added some AI capabilities for metadata/test correlating facilities. But now, Bunsen is also aware of upstream development. Joining the data together, it can also know what environment has changed between any two test runs, and the exact sequence of upstream commits that separate the two. It can also find other test runs for the same or nearby upstream commits. All the tool needs then is some intelligent analysis of those differences.
Enter AI/LLM. Bunsen now has a tool and a web interface (a brain icon, naturally), for comparing sets of build/test runs. Bunsen can compute the metadata differences between pairs of test runs, enumerate all the upstream commits from one to the other, and formulate an analysis request as a prompt plus context to a large language model (LLM). Given your choice standard OpenAI-style inferencing system URL and apikey, Bunsen can submit the text to the LLM and report the analysis response. Ideally, high likelihood causal factors will be accurately identified. This is shown in Figure 2.

Summary
This is just the start. Fully automated regression blaming may become a practical possibility, all because of a single system that can understand both the causes and the effects of test results.