Open source language models can deliver incredible performance because of their smaller size and efficient cost, but they might not deliver the required results for more targeted use cases. There is, however, one more key benefit that open source models have over their frontier model counterparts: customizability. Often, you can fit an open source model to your specific use case via post-training, which offers better and cheaper performance than even frontier models can provide. while running securely and safely for private data, offline platforms, and so on.
This leads to the question: how do you actually get started with language model post-training? Many methods are available today, spanning dozens of libraries with diverging requirements, APIs, setup, usage, and more. How can you learn and resolve all of these differences while also trying to learn what method works best for a given task, data, or hardware? On top of this, what if you are trying to run multiple methods in sequence or to include them in the same project or application?
Therein lies the value of Training Hub, an open source library with algorithm-level abstractions for common, modern post-training techniques. It pulls from a collection of community implementations and provides a common, pythonic interface from Supervised Fine-Tuning to Reinforcement Learning.
An intuitive, uniform entrypoint
Training Hub is a Python-based library built by Red Hat’s AI Innovation team. It helps developers focus on language model post-training algorithms without having to manage the unique constraints and overhead of discovering, understanding, and running a number of independent libraries of varying complexity.
More specifically, Training Hub provides a mapping of algorithms to community libraries and official backend implementations, and also a common interface for running the post-training algorithms (Figure 1).
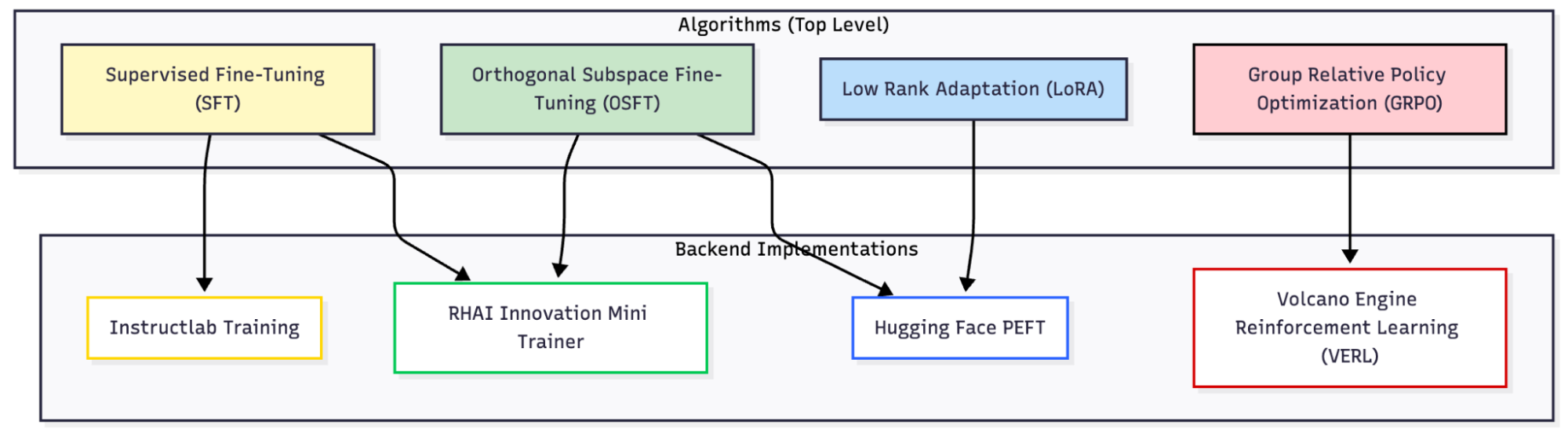
Every algorithm is exposed and runnable as a simple Python function, with a set of common arguments (base model, data, learning rate, batch size, GPU/node distributed setup, and so on), alongside a set of algorithm-specific arguments. For example, running standard Supervised Fine-Tuning (SFT) is as simple as calling the sft function with desired model, data, and hyperparameters:
from training_hub import sft
sft(
model_path="/path/to/model",
data_path="/path/to/data",
ckpt_output_dir="/path/to/checkpoints",
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16
)If you wanted to run the same algorithm, but with a different backend implementation (perhaps the default community library doesn’t support a model or data format you need during training, or another library includes an enticing optimization for certain hardware), switching out the backend is as simple as just asking for it! For the same algorithm, the interface remains constant:
from training_hub import sft
sft(
model_path="/path/to/model",
data_path="/path/to/data",
ckpt_output_dir="/path/to/checkpoints",
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16,
backend="alternate-backend" #<-implemented
)If you instead wanted to run a continual learning method like Orthogonal Subspace Fine-Tuning (OSFT), you would run the osft function with the same arguments, just adding one new algorithm-specific argument, unfreeze-rank-ratio, which dictates what percent of the most critical model weights remain frozen:
from training_hub import osft
osft(
model_path="/path/to/model",
data_path="/path/to/data",
ckpt_output_dir="/path/to/checkpoints",
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16,
unfreeze_rank_ratio=0.3 #<--- OSFT-specific
)Plug-and-play development
With Training Hub, adding new algorithms and new implementations for existing algorithms is incredibly simple.
Every algorithm has an entrypoint function under its name (sft, osft, etc.) and an Algorithm class defining the core train function, the required_params, and the optional_params.
There are then Backend classes that define how to execute_training for a given implementation—that is, how to parse the input arguments and run the training job using the community implementation selected (or defaulted). For any given algorithm, there can be any number of backend providers. For example, if you wanted to add a Hugging Face library, VERL, Unsloth, Llama Factory, etc., as a backend implementation for a given algorithm, you can define a new Backend class for the library. It will then be usable under the same common algorithm-centered interface as the rest of the implementations.
If you want to add a new algorithm, simply create a file under the algorithms directory defining a new Algorithm class and the entrypoint function (lora, grpo, cpt, etc.).
Outside of documentation, algorithms and backends can also be discovered directly through the library:
from training_hub import AlgorithmRegistry
# List all available algorithms
algorithms = AlgorithmRegistry.list_algorithms()
print("Available algorithms:", algorithms) # ['sft', 'osft']
# List backends for SFT
sft_backends = AlgorithmRegistry.list_backends('sft')
print("SFT backends:", sft_backends) # ['instructlab-training']
# Get algorithm class directly
SFTAlgorithm = AlgorithmRegistry.get_algorithm('sft')What's more, you can dynamically register, list, and use new algorithms and backends on the fly, enabling you to make use of the library in whatever way is most convenient to your workflow.
The first home for OSFT
The Training Hub is also home to the first official Orthogonal Subspace Fine-Tuning (OSFT) implementation available openly! This parameter-efficient method addresses continual learning and iterative updates in a language model. By analyzing component matrices via adaptive singular value decomposition (SVD), the method identifies the critical directions in the model and the corresponding weights. It instead only updates in orthogonal directions (the least critical model weights).
By setting the unfreeze_rank_ratio, a user can select what percent of the model’s weights are deemed critical and left frozen versus how much of the least critical model components should remain unfrozen for new task learning capacity. Setting the value to 1.0 is effectively equivalent to full-fine-tuning with SFT, whereas setting to 0.5 will leave 50% of the model frozen and 50% trainable. See Figure 2.
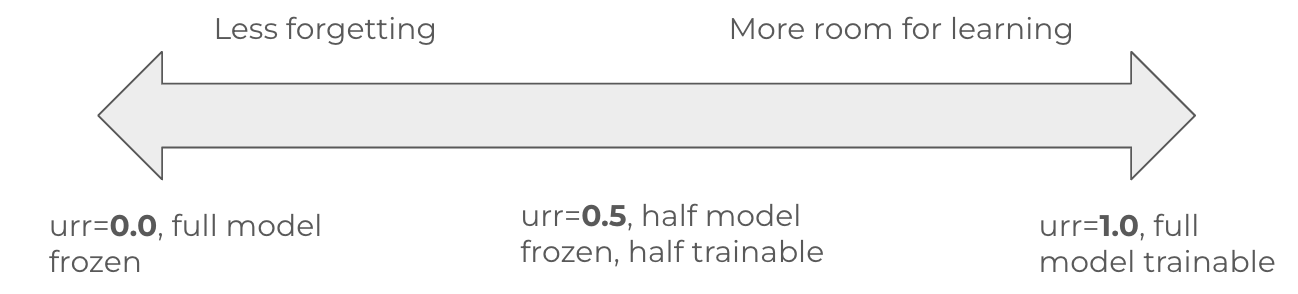
With OSFT now being officially merged into Hugging Face PEFT, we expect future adoption and collaboration with popular community training libraries. All of these will be available through the Training Hub as a common source with direct inventor support.
How to get started with Training Hub
Let’s now do a quick run-through of getting set up with the Training Hub. The package is available on PyPI and can also be installed from source.
Step 1: Set up your environment
You’ll need Python 3.11+ installed. Then, create a project directory and virtual environment:
mkdir training-project && cd training-projectEnter python3 -m venv .venv or uv venv if preferred. Then run:
source .venv/bin/activateStep 2: Install training-hub
For basic installation with GPU support:
pip install training-hub[cuda]For development, one can do an editable install from source:
git clone https://github.com/Red-Hat-AI-Innovation-Team/training_hub
cd training_hub
pip install -e .[cuda]Note: If you encounter build issues with flash-attn, install the base package first:
# Install base package (provides torch, packaging, wheel, ninja)
pip install training-hub
pip install training-hub[cuda] --no-build-isolationSimilarly, for development, you can run:
pip install -e .
pip install -e .[cuda] --no-build-isolationStep 3: Begin training
To start training, either create your own Python file or notebook, or start with one of our existing examples. To see a list of available algorithms, you can run:
from training_hub import AlgorithmRegistry
algorithms = AlgorithmRegistry.list_algorithms()
print("Available algorithms:", algorithms)All algorithms are also listed in the Training Hub main README and on the examples page.
3.1: General guidance
To begin training with a given algorithm, start by importing the desired algorithm:
from training_hub import <algorithm_name>All you have to do from there is run:
<algorithm_name>(
model_path=”/path/to/model”,
data_path=”path/to/data”,
ckpt_output_dir=”path/to/save/checkpoints”,
…
)Most algorithms will have a set of similar common parameters along with a few algorithm-specific parameters. While there are also only a few required parameters, there is a large variety of available optional parameters. To view the available parameters for a given algorithm, you can run:
from training_hub import create_algorithm
osft_algo = create_algorithm('osft', 'mini-trainer')
required_params = osft_algo.get_required_params()
print("Required parameters:", list(required_params.keys()))
optional_params = osft_algo.get_optional_params()
print("Optional parameters:", list(optional_params.keys()))Or, simply view the documentation for the algorithm within our docs directory.
3.2: Algorithm-specific examples
Getting started with an algorithm like SFT is relatively straightforward. Run:
from training_hub import sft
sft(
model_path="/path/to/model",
data_path="/path/to/data",
ckpt_output_dir="/path/to/checkpoints",
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16,
)However, the options for customizing to fit your use case and hardware are quite expansive:
- To set a limit on the number of tokens per GPU (a hard cap for memory) you will want to set
max_tokens_per_gpu. - For specifying the number of GPUs, set
nprocs_per_node. - For configuring your checkpoint frequency, you can adjust
checkpoint_at_epochandsave_samples, or to save optimizer state, addaccelerate_full_state_at_epoch. - If you are starting a multi-node job,
nnodes,node_rank,rdvz_id, andrdvz_endpointwill all be critical.
The Training Hub lets you access the full power of the underlying implementations:
# All possible SFT parameters
training_params = {
# Required parameters
'model_path': model_path,
'data_path': data_path,
'ckpt_output_dir': ckpt_output_dir,
# Core training parameters
'num_epochs': num_epochs,
'effective_batch_size': effective_batch_size,
'learning_rate': learning_rate,
'max_seq_len': max_seq_len,
'max_tokens_per_gpu': max_tokens_per_gpu,
# Data and processing parameters
'data_output_dir': data_output_dir,
'warmup_steps': warmup_steps,
# Checkpointing parameters
'checkpoint_at_epoch': checkpoint_at_epoch,
'save_samples': save_samples,
'accelerate_full_state_at_epoch': accelerate_full_state_at_epoch,
# Distributed training parameters
'nproc_per_node': nproc_per_node,
'nnodes': nnodes,
'node_rank': node_rank,
'rdzv_id': rdzv_id,
'rdzv_endpoint': rdzv_endpoint,
}For example, if running on 8xH100 (single node) and training Llama-3.1-8B-Instruct, your function might look like:
from training_hub import sft
sft(
model_path="meta-llama/Llama-3.1-8B-Instruct",
data_path="/path/to/data",
ckpt_output_dir="llama-ckpts",
num_epochs=3,
learning_rate=1e-5,
effective_batch_size=16,
nprocs_per_node=8,
max_tokens_per_gpu=25000,
max_seq_len=8192,
checkpoint_at_epoch=True,
accelerate_full_state_at_epoch=False
)For runnable examples for both SFT and OSFT (using settings for 2x48GB GPUs by default), check out the following notebooks:
For more in-depth guidance, tutorials, documentation, and examples, check out our examples page.
Continued progress
The Training Hub will continue to receive new algorithm and community implementation support and is also fully open to contribution. If you have any core post-training algorithm or required library that you would like to incorporate in your workflows under the Training Hub interface, feel free to open issues or PRs directly on the GitHub repository. For any further inquiries, you can tag me directly on GitHub @Maxusmusti. Let’s work together to build a common home for all language model post-training!