Welcome to the world of generative AI, where cutting-edge large language models (LLMs) combine with retrieval-augmented generation (RAG) to create sophisticated chatbots and AI-powered applications. This articles explores how to leverage the power of LLMs with RAG within the Red Hat OpenShift AI environment, enabling businesses to answer complex questions, enhance customer interactions, and streamline operations. You will be able to understand this architecture and even implement it in your environment where you can customize LLM outcomes with your own set of documents and get relevant results from your chat bot.
What is RAG?
RAG is a technique that enhances the capabilities of LLMs by augmenting their knowledge with additional, domain-specific data. LLMs are powerful, but their knowledge is limited to the public data they were trained on. RAG overcomes this limitation by retrieving relevant information from specific datasets and integrating it into the model's responses. This approach is particularly useful for providing accurate answers to questions about private or recently updated data.
Why RAG?
RAG allows the LLM to overcome lack of source attribution while potentially eliminating incorrect generation or biased information from pre-trained LLMs. Because LLMs are very costly to train or even sometimes fine tune, accessing real-time information on specific scenarios can be a challenge to incorporate in an LLM where RAG can play a vital role. Figure 1 depicts an architecture diagram of an LLM with RAG.
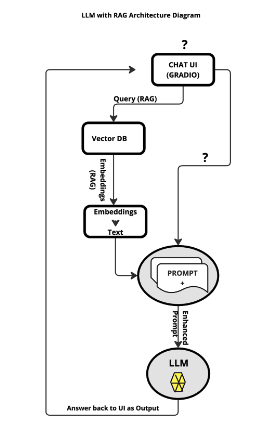
RAG architecture
A typical RAG application consists of two main components:
- Indexing:
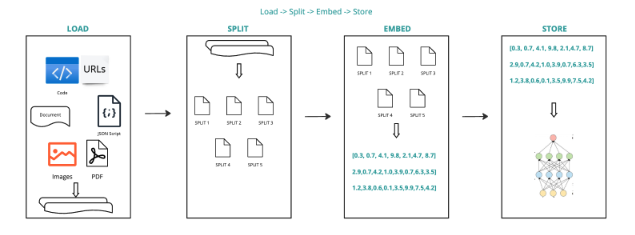
- Load: Data is ingested using Document Loaders.
- Split: Text splitters break down large documents into manageable chunks.
- Store: The chunks are stored in a Vector Store, indexed, and made ready for retrieval.
- Process Flow: Load -> Split -> Embed -> Store.
Figure 2 depicts this part of the process.
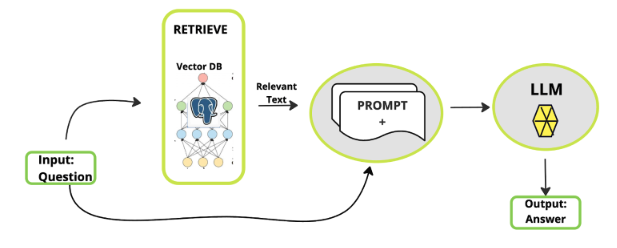
- Retrieval and generation:
- Retrieve: The system retrieves relevant data splits in response to user queries.
- Generate: The LLM generates an answer using the retrieved data and the original question.
Figure 3 depicts this part of the process.
Business benefits of using LLMs with RAG
Combining LLMs with RAG offers several advantages for businesses:
- Enhanced customer support: LLMs in chatbots provide quick, accurate responses, improving customer satisfaction.
- Content creation: Automate the generation of high-quality content for marketing and communication.
- Personalized recommendations: Analyze customer data to generate tailored product or service recommendations.
- Automated data analysis: Extract insights from large datasets, enabling faster, data-driven decision-making.
- Improved search relevance: Enhance search results on websites and applications by integrating domain-specific knowledge.
- Efficient knowledge management: Create and maintain knowledge bases, FAQs, and internal documentation with ease.
- Adaptive learning systems: Continuously update the LLM with new data to improve its accuracy and relevance.
See Figure 4.
How to create the demo
You can use this link to bootstrap the application set using ArgoCD to deploy everything needed to create this environment on Red Hat OpenShift using Red Hat OpenShift AI. You need to ensure that you add the two ApplicationSets, one in the bootstrap folder and other one in the bootstrap-rag folder applicationset/applicationset-bootstrap.yaml. This approach allows you to implement the setup yourself and gain a deeper understanding of how it works. The bootstrap has LLM deployed whereas the bootstrap-rag will have a vectordb with customized data pre-ingested during deployment of the application set. Additionally, you can explore and create pipelines for data ingestion in a vector database, tailored to different personas involved in the process.
Scenarios
Let's examine a few different scenarios.
Scenario 1: End-to-end deployment
You can follow the instructions provided in the linked guide to bootstrap an end-to-end environment using ArgoCD. This environment will include all necessary components, such as the AI model, vector database, and data pipelines. You'll learn how to set up the infrastructure and deploy the application stack, giving you hands-on experience with Red Hat OpenShift AI.
Scenario 2: Data ingestion pipelines
After setting up the environment, you can explore the creation of data ingestion pipelines tailored to specific personas. For example, you can design pipelines for data scientists who need to preprocess and insert data into the vector database or for DevOps engineers who are responsible for maintaining the system's efficiency and scalability. This will give you insights into different roles and how they interact with the system. See Figure 5.

Scenario 3: Customization and scaling
Once you've deployed the environment and created the initial pipelines, you can delve into customizing and scaling the setup. This scenario allows you to experiment with scaling the vector database, optimizing the AI models, and ensuring that the system can handle increased loads as the application grows.
By following these scenarios, you'll not only set up a robust AI environment on Red Hat OpenShift but also gain practical experience in managing and scaling it. The guide will provide you with all the necessary steps and considerations, ensuring that you're well-equipped to handle real-world applications.
Personas
Next, let's also examine a few different personas.
DevOps persona: Pipeline manifest
As a DevOps person, you can import and execute pipeline manifests directly from the OpenShift AI dashboard. This pipeline ingests data, verifies it, and ensures the LLM is functioning correctly after the ingestion process.
Data scientist/machine learning (ML) engineer persona
Data scientists and ML engineers can use the Elyra pipeline editor to create, modify, and execute pipelines without deep knowledge of the underlying Red Hat OpenShift Pipelines. The intuitive interface allows them to focus on tasks like quality checking and response generation.
Everything you need is already set in this environment post deployment of the bootstrap manifest (link) on OpenShift like pipeline server, runtime environment, and etc. Elyra run will convert your pipeline on canvas to creating a pipeline run for Tekton in OpenShift. Recent releases have introduced Argo Workflow to interact with Tekton. You may need to update the pipeline code to suit your deployment release.
Go back to the data science project ic-shared-rag-llm your OpenShift AI Dashboard and create a workbench similar to the one already running. Once the new workbench is created, open it and clone the Git repo before you do the demonstration to save time, as shown in Figure 6.
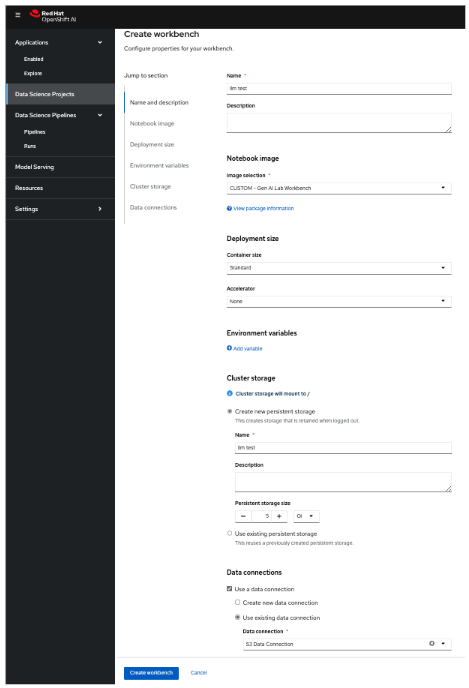
Once the workbench is created, you should select Open for llm test workbench only (Figure 7).

This will ask you to log in if it's for the first time. Use the same admin username and password as you have used previously and log in to the workbench. Do Allow selected permissions before you access your workbench, as shown in Figure 8.

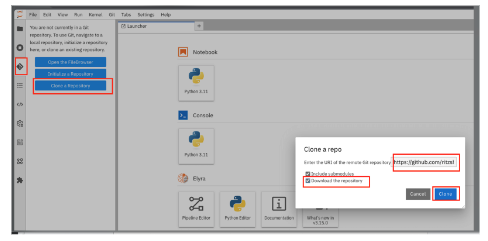
Wait for the JupyterHub notebook to launch (takes a minute for the first time) and then clone this Git repository.
From the left side panel, select the icon to clone the Git repository and use the above Git repo. Select Clone. This will download and add this git repository to your JupyterHub notebook. See Figure 9.
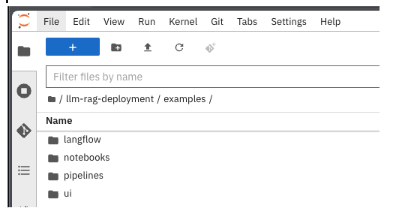
In llm-rag-deployment/examples, go to the pipelines folder and select the data_ingestion_response_check file, as depicted in Figure 10 and 11.
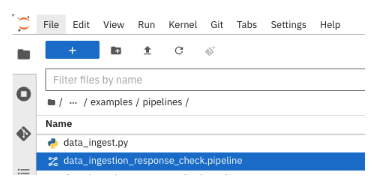
This will open the file in the Elyra editor and you will see those 4 tasks which you saw earlier as well. Now as a data scientist you can add or delete the tasks (just drag a Python code and it gets added as a task into the pipeline—it's that simple for a data scientist and you do not need to know how the pipeline works).
Task 1’s code can be updated to point to new data and that should push new data to vectordb.

Press the Run button as you see in the above screenshot. Select the defaults and say OK and then again press OK. Ensure that you update the Pipeline Name with a different name, as the same name already exists from the previous run. See Figure 13.
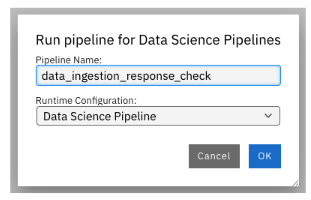
Let's say you created a Python code to check the quality of the response and want to add it alongside test response. You can do this right in the Elyra editor and this will create additional Tekton tasks in the pipeline run automatically for you.
Isn’t that cool?
This next section demonstrates that you can add new tasks and execute. Currently this new task is not executed correctly in the pipeline and so does not show the complete output or wait for it to finish. Just execute and show that it's running and close the discussion for now.
Let’s add a task. Say we want to check the quality of the response output from LLM. We can add that as a task through the Elyra editor. Drag the Python code which does response quality check. See Figure 14.

Then connect the lines from the second task to this new task and from this new task to summarize task. This should run both the response tasks in parallel.
Figure 15 shows step 1.

While Figure 16 shows step 2.

Now re-run the complete pipeline again and this time it should include the new task as well.
Then check the AI dashboard (Figure 17).
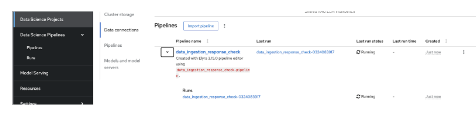
You will see this new pipelinerun. Select the run and this should take you here (Figure 18).
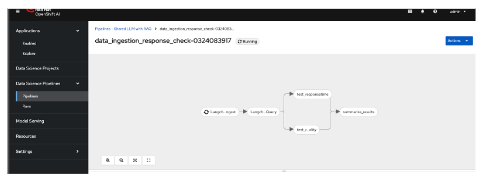
This is what you will see in the OpenShift Console as well. The first one in the list is the new pipeline run. Note that it does not show the complete pipeline run after adding this new task, as that task is not working for now. See Figure 19.
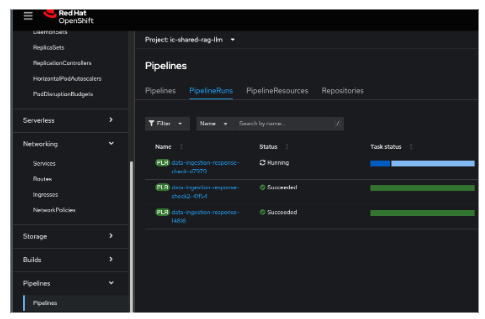
This is how it looks when you select that pipelinerun (Figure 20).
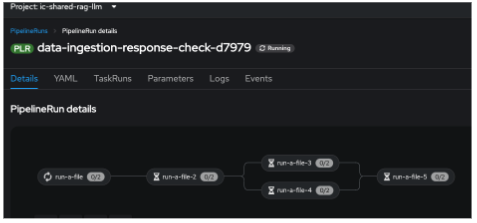
You as a data scientist do not need to know about the underlying Tekton—just use the Elyra editor and drop your code as tasks, connect it the way you want to create workflow, and run. That’s it.
Conclusion
By integrating LLMs with RAG on Red Hat OpenShift AI, businesses can unlock a new level of AI-driven efficiency, innovation, and customer satisfaction. Whether you're an admin or a data scientist, the tools and techniques demonstrated in this guide offer a seamless way to harness the power of AI in your organization. Welcome to the future of AI excellence with Red Hat OpenShift AI!
Last updated: December 11, 2024