In our previous article, we discussed the basics of Apache Kafka MirrorMaker 2, and how it improves data replication between Kafka clusters. This article will focus more on the practical side of things. We'll dive into how to deploy MirrorMaker 2 when using Red Hat AMQ Streams and how to fine-tune MirrorMaker 2 settings for better performance, a crucial step for anyone using this tool. We will also focus on Kafka migration use-cases and describe how the consumer-first Kafka migration strategy can be beneficial in many scenarios.
Prerequisites
Red Hat AMQ Streams, which leverages the open source project Strimzi, provides a way to deploy Apache Kafka to Kubernetes using the operator pattern. The deployment of MirrorMaker 2 is supported with the creation of a custom resource of type KafkaMirrorMaker2.
In order to connect to the Kafka clusters, MirrorMaker 2 requires Kafka users with specific permissions to be configured in both source and target clusters. For instance, in the source cluster, MirrorMaker 2 will require read and describe permissions on all topics and consumer groups. The permissions that need to be granted to the Kafka user will depend on the MirrorMaker 2 architecture you decide to implement. As mentioned in the previous blog, by default the mm2-offset-syncs is created on the source Kafka cluster. If the defaults are kept, the Kafka user connecting to the source cluster would require write permissions to the source cluster for creating this topic. However, in order to simplify the configuration for this user, it would be better to instruct MirrorMaker 2 to create this topic on the target cluster. Moreover, this would be also helpful when MirrorMaker 2 will only have read access to the source cluster. To configure MirrorMaker 2 mm2-offset-syncs topic to be deployed on the target Kafka cluster, just set offset-syncs.topic.location = target in MirrorMaker 2 config (more details in the upcoming sections).
In order to protect the source cluster, it is also recommended to insert user quotas for network traffic. The value will be set in bytes and will correspond to the limitation on each of the brokers.
The user definition to be created on the source cluster in a custom resource version may look like this:
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: kafka.mm2.migration-user
namespace: <kafka-custer-namespace-source> # (1)
labels:
strimzi.io/cluster: <kafka-cluster-name-source> # (2)
spec:
authentication:
type: <authentication-type> # (3)
authorization:
acls:
- operation: Read # (4)
resource:
name: '*'
patternType: literal
type: topic
- operation: DescribeConfigs # (5)
resource:
name: '*'
patternType: literal
type: topic
- operation: Describe # (6)
resource:
name: '*'
patternType: literal
type: group
- operation: Describe # (7)
resource:
patternType: literal
type: cluster
type: simple
quotas:
consumerByteRate: 52428800 # 50MiB/s per broker # (8)
producerByteRate: 52428800 # 50MiB/s per broker # (9)
requestPercentage: 50
(1) Namespace where Source Kafka cluster is deployed.
(2) Name of the Kafka cluster.
(3) Authentication type and details (i.e., scram, TLS).
(4) Read permissions on topics that need to be replicated. This is required by Source Connector. If the topic pattern is not a match all (*) and mm2-offset-syncs topic is created on source, this aforementioned topic needs to be added to the list as well. This is required by Checkpoint Connector.
(5) DescribeConfigs permissions on topics that need to be replicated. This is required by Source Connector. If the topic pattern is not a match all (*) and mm2-offset-syncs topic is created on source, this aforementioned topic needs to be added to the list as well. This is required as well by the Source Connector.
(6) Describe permissions on the groups of whose offsets need to be synced. This is required by Checkpoint Connector.
(7) Describe permissions on cluster. This is required by Checkpoint Connector.
(8) Network quota for consumers in bytes per broker.
(9) Network quota for producers in bytes per broker.
Regarding the permissions required by MirrorMaker2 on the target cluster, this will require most permissions on all MirrorMaker 2 internal topics, like: mirrormaker2-cluster-offsets, mirrormaker2-cluster-status, mirrormaker2-cluster-configs, my-source-cluster.checkpoints.internal, heartbeats, as well as most permissions to manage the topics and consumer groups that are going to be migrated to the target cluster.
However, for the sake of simplicity, in case we are going to migrate to a brand new Kafka target cluster (which doesn’t contain any other topics or groups), a Kafka user will require nearly full permissions on all groups and topics. A custom resource for MirrorMaker 2 could look like this:
|
Info alert: Note
Warning alert:The example authorizations required for the Kafka users are only informative and will need to be adapted based on your target architecture. A more fine-grained and secure authorization model can be found in Strimzi documentation.
Configure MirrorMaker
MirrorMaker 2 is highly configurable, but there are a few configuration parameters that should be finely tuned in order to improve MirrorMaker 2 performance for a migration scenario environment. The tuning focuses on improving throughput and parallelism for replicating the data.
These parameters are described in the following table.
| Parameter | About | Default value | Optimized value |
tasks.max |
The maximum number of tasks that should be created for this connector. The connector may create fewer tasks if it cannot achieve this level of parallelism. Can be set in Source and Checkpoint connector configuration:
To increase parallelism, configure higher values. |
1 |
|
producer.acks |
The number of acknowledgments the producer requires the leader to have received before considering a request complete. Can be set in producer configuration in the target cluster:
Optimization: Set this to 1. This means that ACK is not required from all ISR, which reduces latency. However, this doesn't provide strong delivery guarantee, which may lead to data loss. See details. |
all |
1 |
producer.batch.size |
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes. Can be set in producer configuration in the target cluster:
To increase throughput, configure higher values. |
16384 |
50000 |
producer.linger.ms |
Latency to add in order to fill the batch with more records. 0 means no delay, i.e., send the batch right away. If the batch is filled before linger.ms value is reached, then the batch is sent independent of the linger.ms value. Can be configured in producer configuration in the target cluster:
Optimization: Configure this to a higher value to improve throughput. |
1500 |
0 |
producer.buffer.memory |
The total bytes of memory the producer can use to buffer records waiting to be sent to the server. Can be set in producer configuration in the target cluster:
This needs to be set as about |
33554432 |
225000000 |
producer.compression.type |
The compression type for all data generated by the producer. Valid values are none, gzip, snappy, lz4, or zstd. Can be set in producer configuration in the target cluster:
Optimization: in order to increase network throughput and speed up initial load (at the expense of consumer apps CPU consumption after the migration). Gzip is the best tradeoff from the options. |
none |
gzip |
producer.max.request.size |
The maximum size of a request in bytes. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests. This is also effectively a cap on the maximum uncompressed record batch size. Can be set in producer configuration in the target cluster:
|
1048576 |
157286400 |
offset.flush.timeout.ms |
Maximum number of milliseconds to wait for records to flush and partition offset data to be committed to offset storage before canceling the process and restoring the offset data to be committed in a future attempt. Can be set in producer configuration in the target cluster:
Optimization: with the default value the Connect task are heavily loaded and timeout before flushing. Set this to a higher value. |
5000 |
250000 |
Info alert: Note
These settings should only be considered as guidelines. The best settings for you will depend on your environment. Experimenting with trial and error will help you to figure out what works best for your setup.
Allow-lists and deny-lists of topics and groups
For the topic migration, an allow-list approach is recommended. This is because it’s easier to track which topics are part of the migration.
The parameter to define the allow-list is called topicsPattern and its value supports a comma-separated list, as well as regular expressions. If one requires more control regarding the topics to be mirrored, it is recommended to have only full topic names in the allow-list. Here is an example:
topicsPattern: "app1-t1, app1-t2, app2-t1, app3-t1, app3-t2"
However, one can also use regular expressions to define topics to be mirrored. For example, if all the topics belonging to one application are prefixed with the application name, that prefix can be used in a regex to configure MirrorMaker 2 to replicate all its topics.
topicsPattern: ^app1.*|app2.*$
For the consumer groups to be replicated, the concept is the same. One can use a comma-separated list or regular expressions.
However, sometimes for consumer groups it's not always easy to identify the groups that require to be considered for migration. For this a deny-list approach can be used (created also using regular expressions).
One thing to consider is also that if a consumer group is in the list to be migrated, but is not attached to any topic which is migrated, the consumer group will not be migrated either. A deny-list might look like this:
groupsPattern: ^(?!.*(heartbeats|)).*$
Configure clusters and mirrors
Two sections of the MirrorMaker 2 are particularly important in the KafkaMirrorMaker2 custom resource: clusters and mirrors.
clustersdefine the clusters to be synchronized. There can be multiple source clusters, but a single target cluster. For a simple migration scenario, one will have only two clusters defined in this section: a single source cluster and a destination cluster.mirrorsset the configuration parameters of the MirrorMaker connectors. More details on the tuning parameters that can be applied in this section can be found below.
MirrorMaker 2 definition
Considering all of the previous information, let’s now take a look at an example of a MirrorMaker 2 custom resource.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaMirrorMaker2
metadata:
name: my-mirror-maker-2
spec:
version: 3.4.0 # (1)
replicas: 2 # (2)
connectCluster: "my-target-cluster" # (3)
clusters: # (4)
- alias: "my-source-cluster" # (5a)
bootstrapServers: my-source-cluster-kafka-bootstrap:9093 # (5b)
tls: # (5c)
trustedCertificates:
- secretName: my-source-cluster-cluster-ca-cert
certificate: ca.crt
authentication: # (5d)
type: tls
certificateAndKey:
certificate: tls.crt
key: tls.key
secretName: mm2-source-cluster
- alias: "my-target-cluster" # (6a)
bootstrapServers: my-target-cluster-kafka-bootstrap:9093 # (6b)
tls: # (6c)
trustedCertificates:
- secretName: my-target-cluster-cluster-ca-cert
certificate: ca.crt
authentication: # (6d)
type: scram-sha-512
username: kafka.mm2.migration-user
passwordSecret:
password: password
secretName: mm2-target-cluster
config: # (6e)
## Configure Kafka Connect topics default replication factor. -1 means it will use the default replication factor configured in the broker
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
## Configure Kafka Connect topics names (in case the defaults need to be changed).
#config.storage.topic: mirrormaker2-cluster-config
#offset.storage.topic: mirrormaker2-cluster-offset
#status.storage.topic: mirrormaker2-cluster-status
## Configure MirrorMaker2 tuning parameters for producers
producer.ack: 1
producer.batch.size: 50000
producer.buffer.memory: 225000000
producer.compression.type: gzip
producer.linger.ms: 1500
producer.max.request.size: 157286400
producer.request.timeout.ms: 60000
offset_flush_timeout: 250000
task_shutdown_graceful_timeout_ms: 10000
mirrors: # (7)
- sourceCluster: "my-source-cluster" # (7a)
targetCluster: "my-target-cluster" # (7b)
sourceConnector: # (8)
tasksMax: 32 # (9)
config: # (10)
sync.topic.acls.enabled: "false" # (10a)
sync.topic.configs.enabled: "false" # (10b)
refresh.topics.enabled: "false" # (10c)
topic.creation.enable: "false" # (10d)
replication.policy.class: "io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy" # (10e)
offset-syncs.topic.location: target # (10f)
heartbeatConnector: # (11)
config:
heartbeats.topic.replication.factor: 3
checkpointConnector: # (12)
tasksMax: 8 # (13)
config: # (14)
sync.group.offsets.enabled: true # (14a)
sync.group.offsets.interval.seconds: 10 # (14b)
checkpoints.topic.replication.factor: 3 # (14c)
replication.policy.class: # (14d)
"io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy"
offset-syncs.topic.location: target # (14e)
topicsPattern: "app1-t1, app1-t2, app2-t1, app3-t1, app3-t2" # (15)
groupsPattern: "^(app1.*|app2.*)$" # (16)
(1) Kafka version on the target Kafka cluster. If the target cluster is deployed by AMQ Streams, its version is bounded to a specific Kafka version.
(2) Number of replicas of MirrorMaker 2 instances. As MirrorMaker2 is built on top of Kafka Connect, this corresponds to the number of Kafka Connect workers. The value depends also on the number of tasks the Connect cluster will handle. As a start, one can use two workers. (i.e., replicas). However, this heavily depends on the cluster load and the data to be migrated.
(3) Name of the Connect Cluster. Should correspond to the alias for the defined target Kafka cluster. In our example, the target Kafka cluster has the my-target-cluster alias.
(4) Clusters array. As explained in the previous section, it may contain only one target cluster, but more source clusters. For the described migration scenario, use will use only one source cluster.
(5) Definition of the source cluster. In this section, one can define the alias name of the cluster (5a), the bootstrap server(5b), the TLS truststores(5c), the authentication parameters(5d) or configuration parameters (5e). The configuration parameters may be related to the MirrorMaker2 consumer’s configuration. Related to authentication, in this particular example, a TLS authentication for the source cluster is used.
(6) Definition of the target cluster. Similar to the above definition. The config section (6e) will be in general broader for the target cluster. The producer tuning parameters explained in the previous section will be defined in this section. Additionally, one can define in this section the configuration for the Kafka Connect topics, like the topic names and the replication factor. In regards to authentication (6d), for this example, SASL-SCRAM was used for authentication to the target cluster.
(7) Mirrors array. One mirror corresponds to a combination of one source (7a) and the target cluster (7b). In each mirror, one can define MirrorMaker 2 connectors configurations.
(8) Configuration of the Source Connector for the specified mirror.
(9) Maximum number of tasks across all Connect workers for the Source Connector. As mentioned above, for a migration scenario one can start with 32. However, this heavily depends on the cluster load and the data to be migrated.
(10) Configuration block for the Source Connector. If using User Operator, one should set sync.topic.acls.enabled: "false" (10a), as this is not compatible with it. As for the described migration scenario, the topics are created manually and not by MirrorMaker 2, the following settings will prevent MirrorMaker 2 to update the configuration for the manually created topics: sync.topic.configs.enabled: "false" (10b), refresh.topics.enabled: "false" (10c) and topic.creation.enable: "false" (10d). A very important setting for the source connector is also to define the replication policy class (10e). This must be set to: io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy, as it’s desired to have the same topic names in the target cluster. By default, MirrorMaker 2 uses the DefaultReplicationPolicy which renames the replicated topics in the target cluster by prefixing them using the source cluster alias name. As mentioned in the previous sections, the following setting should be present: offset-syncs.topic.location: target (10f) if the mm2-offset-sync topic should be deployed in the target Kafka cluster. The configuration block supports many more config parameters. More about all the available options for configuring MirrorMaker 2 connectors can be found in the official documentation.
(11) Configuration of the Heartbeat Connector including the config block. Details about config parameters in the same official documentation.
(12) Configuration of the Checkpoint Connector for the specified mirror.
(13) Maximum number of tasks across all Connect workers for the Checkpoint Connector. As mentioned above, for a migration scenario one can start with 8. However, this heavily depends on the cluster load and the data to be migrated.
(14) Configuration block for the Checkpoint Connector. Two important settings here are: sync.group.offsets.enabled: true (14a) for enabling synchronization of consumer group offsets and sync.group.offsets.interval.seconds: 10 (14b) for setting the frequency of consumer group synchronization. One can also set the replication factor for the checkpoint point, though the default of 3 should be fine (14c). As in Source Connector configuration, it is important to set replication.policy.class to io.strimzi.kafka.connect.mirror.IdentityReplicationPolicy (14d) and offset-syncs.topic.location to target (14e). As for the other connectors, more details about the available configs can be found in the official documentation.
(15) Regex or comma-separated list of the topics to be replicated for the specified mirror.
(16) Regex or comma-separated list of the consumer groups to be migrated for the specified mirror.
Data migration
In the previous sections, we took a deep-dive into MirrorMaker 2 architecture and configuration. But how do we actually migrate the Kafka client applications after MirrorMaker 2 is set up and it is replicating the data from the source cluster to the target cluster?
One of the most common approaches to migrate client applications to the new Kafka cluster is called consumer-first approach.
As the names state, consumer-first means that the application migration starts with switching the consumer to the target Kafka cluster. After the consumer is switched and its functionality is validated, the producer can be switched as well.
Considering the fact that MirrorMaker 2 replicates also the consumer group offsets, this approach has the advantage of no or minimal downtime for clients when performing the switch.
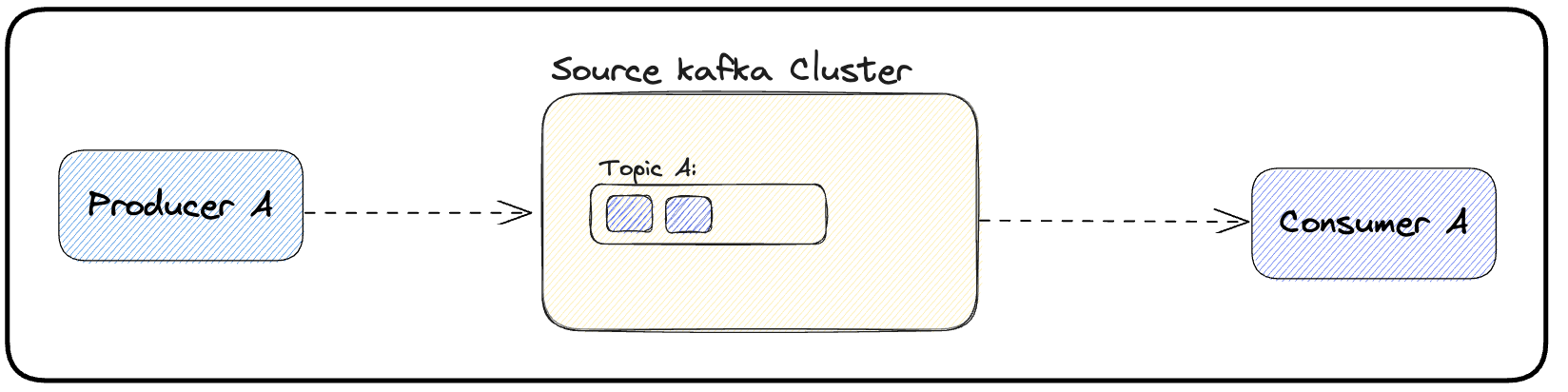
(a) In the initial phase, both producers and consumers for a specific topic are connected to the Kafka source cluster. Figure 1 shows a standard Kafka producer-consumer application architecture.
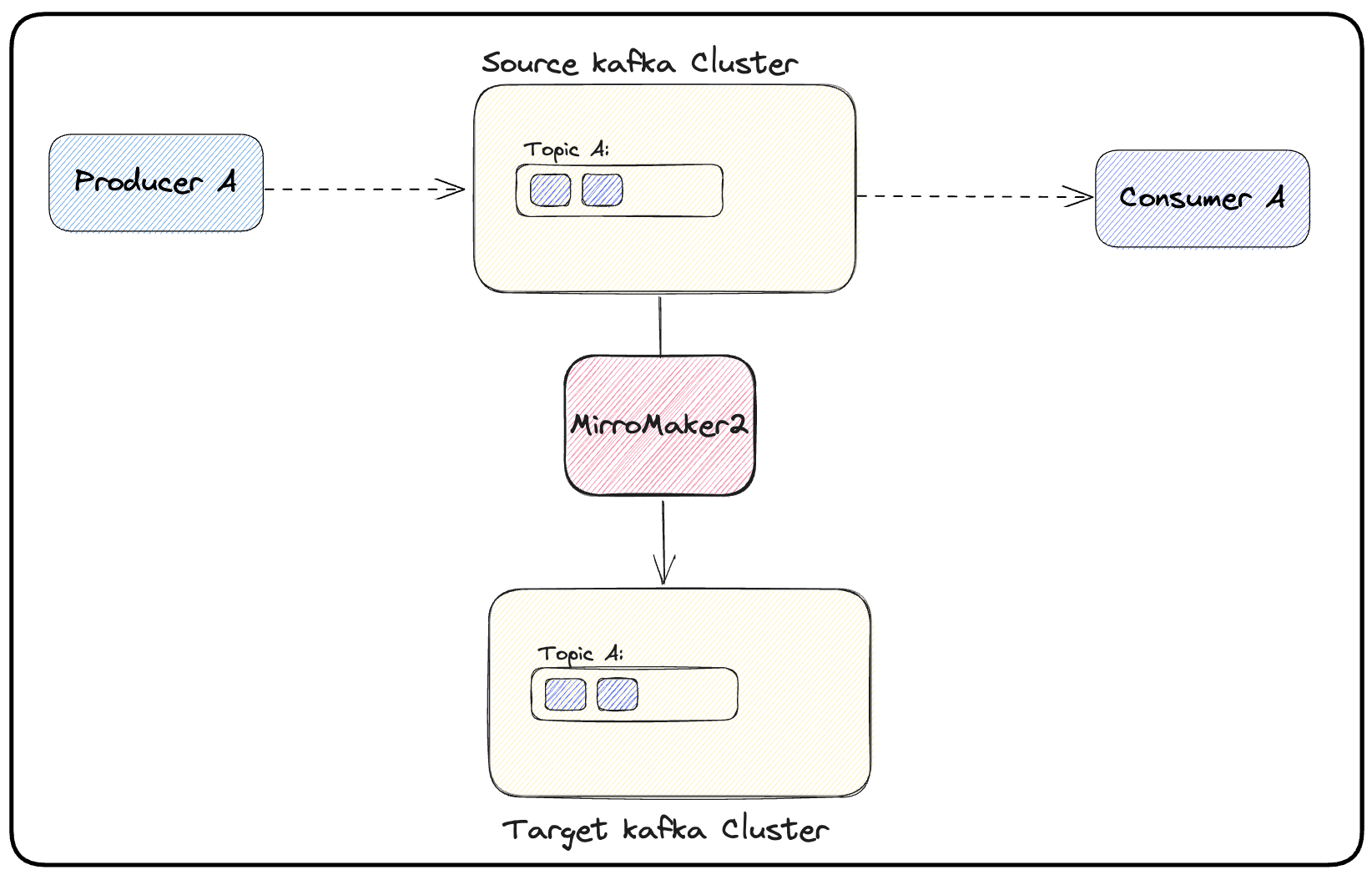
(b) Next, MirrorMaker 2 will start to replicate the topic(s) and consumer group(s) from the Kafka source cluster to the Kafka target cluster. At this stage, the consumer will still be connected to the source Kafka cluster. Figure 2 explains the first step of the consumer-first approach, which is mirroring topics of interest to the target cluster.
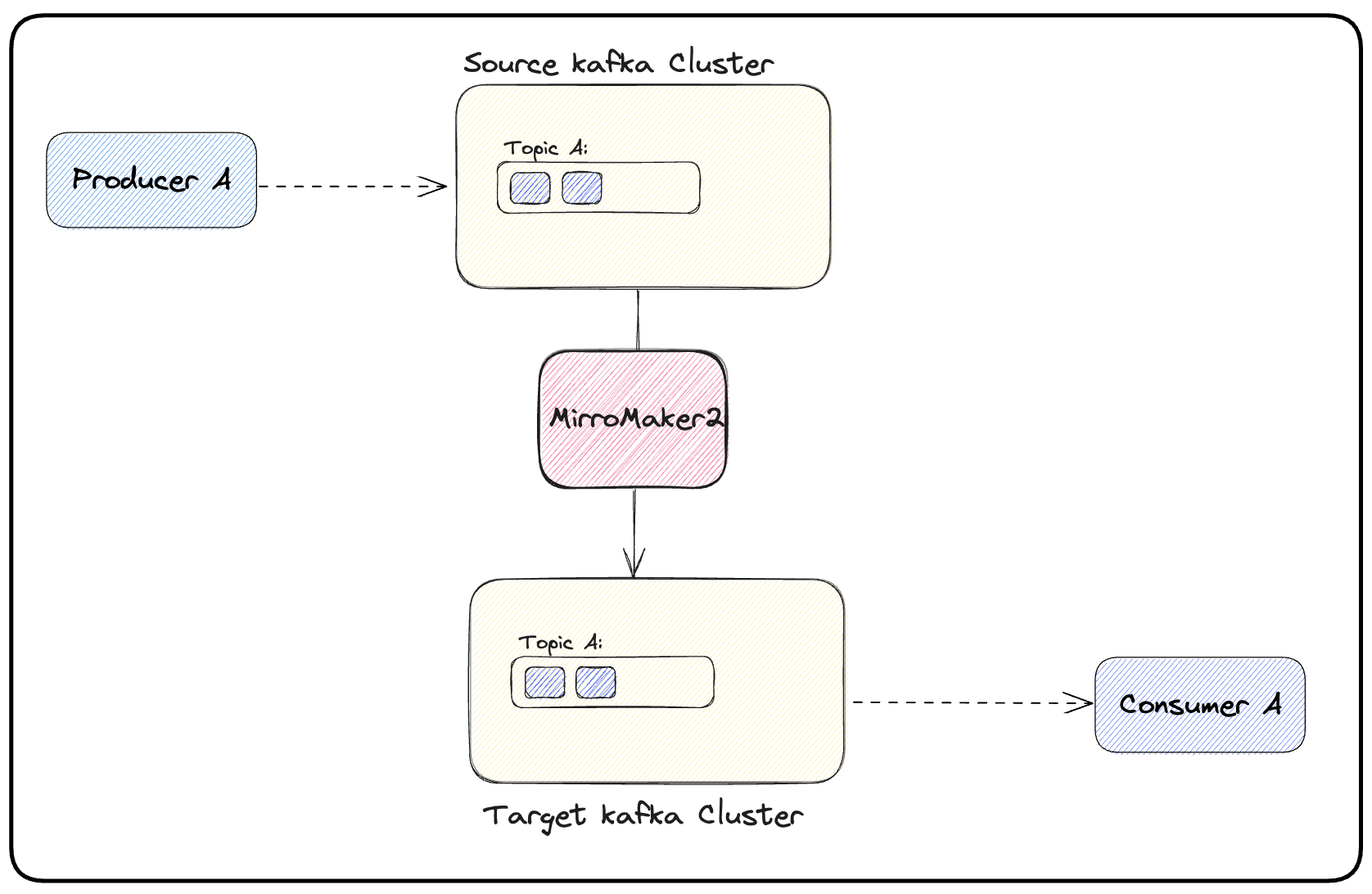
(c) Before the consumer application is migrated, some validations would need to be performed. One should check if the consumer groups are properly migrated to the target Kafka cluster and if the offsets committed on the source cluster are available on the target cluster.
If the validations succeed, the consumer may be switched to the Kafka target cluster. This will imply no downtime, as the consumers part of the consumer group will be rolled out gradually to point to the new cluster. After the switch, the consumer’s functionality should be tested. Figure 3 illustrates this.
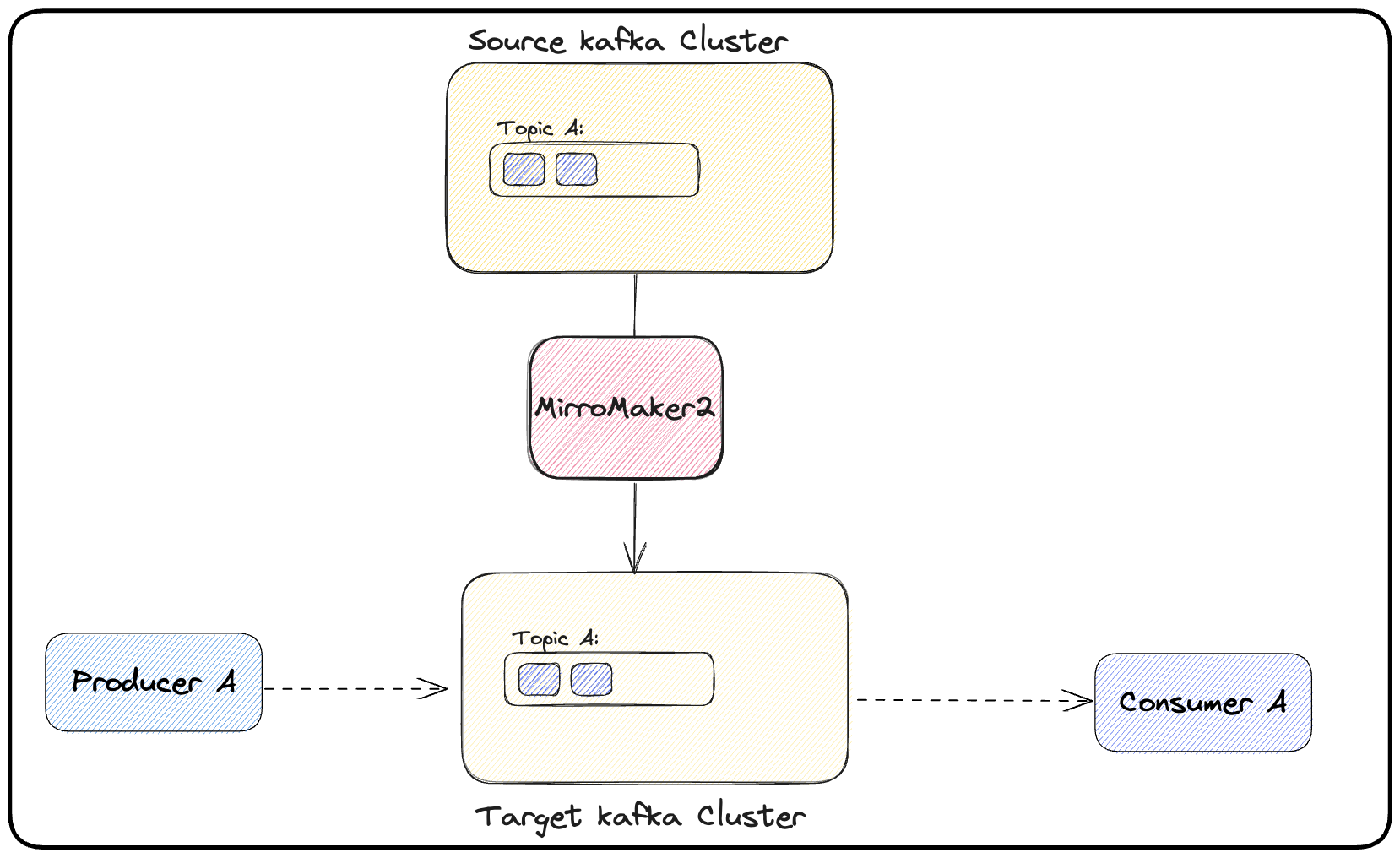
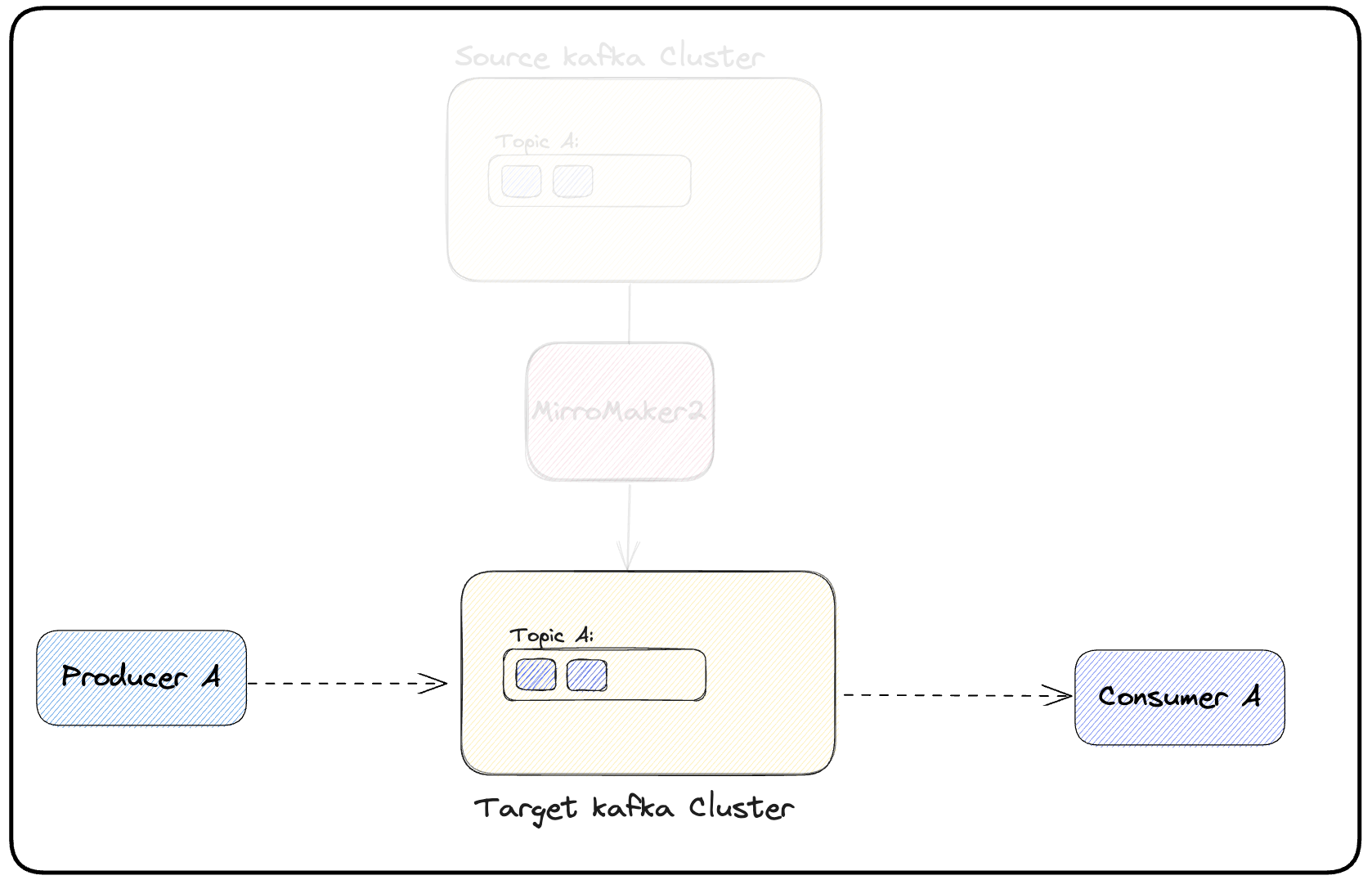
(d) Now it’s time to switch the producer. This switch should be performed in three steps: (1) first, one should stop the producer on the source cluster. (2) after the producer stops, one should wait for MirrorMaker 2 to stream all the remaining topic’s messages to the target Kafka cluster. (3) after this, the producer can be started pointing to the target Kafka cluster. Figure 4 illustrates this.
(e) If the producer works as expected after the switch, the topic(s) can be removed from the MirrorMaker list of topics requiring replication (Figure 5).
Summary
In this article, we discussed some details on how MirrorMaker 2 can be used in the context of Kafka data migration. We described the prerequisites for a MirrorMaker 2 deployment and details about various MirrorMaker 2 tuning parameters that can be very helpful for data migration. Finally, we discussed the consumer-first migration approach for Kafka clients leveraging MirrorMaker 2.
Last updated: January 5, 2024