MirrorMaker is a tool from the Apache Kafka project designed for replicating and streaming data between Kafka clusters with enhanced efficiency, scalability, and fault tolerance.
The first version of MirrorMaker relied on Kafka consumer and producer pairs, with the consumers reading data from the source Kafka cluster and the producer writing data to the target Kafka cluster. This was great for streaming data between Kafka clusters, but had obvious limitations, such as static configurations or the impossibility of synchronization of consumer offsets.
The second major release of MirrorMaker (MirrorMaker 2.0) is more mature and complete than the initial one. This article will demystify Kafka mirroring by explaining the architecture, use cases, and core concepts of MirrorMaker 2.
Benefits of MirrorMaker 2
The new MirrorMaker, completely redesigned and built on top of the Kafka Connect framework, provides the following significant improvements:
- Dynamic configuration changes support
- Bidirectional capabilities
- Better performance
- Advanced features, like filtering and renaming
- Consumer offset synchronization
Use cases
There are various use cases for MirrorMaker 2, but the most common are as follows:
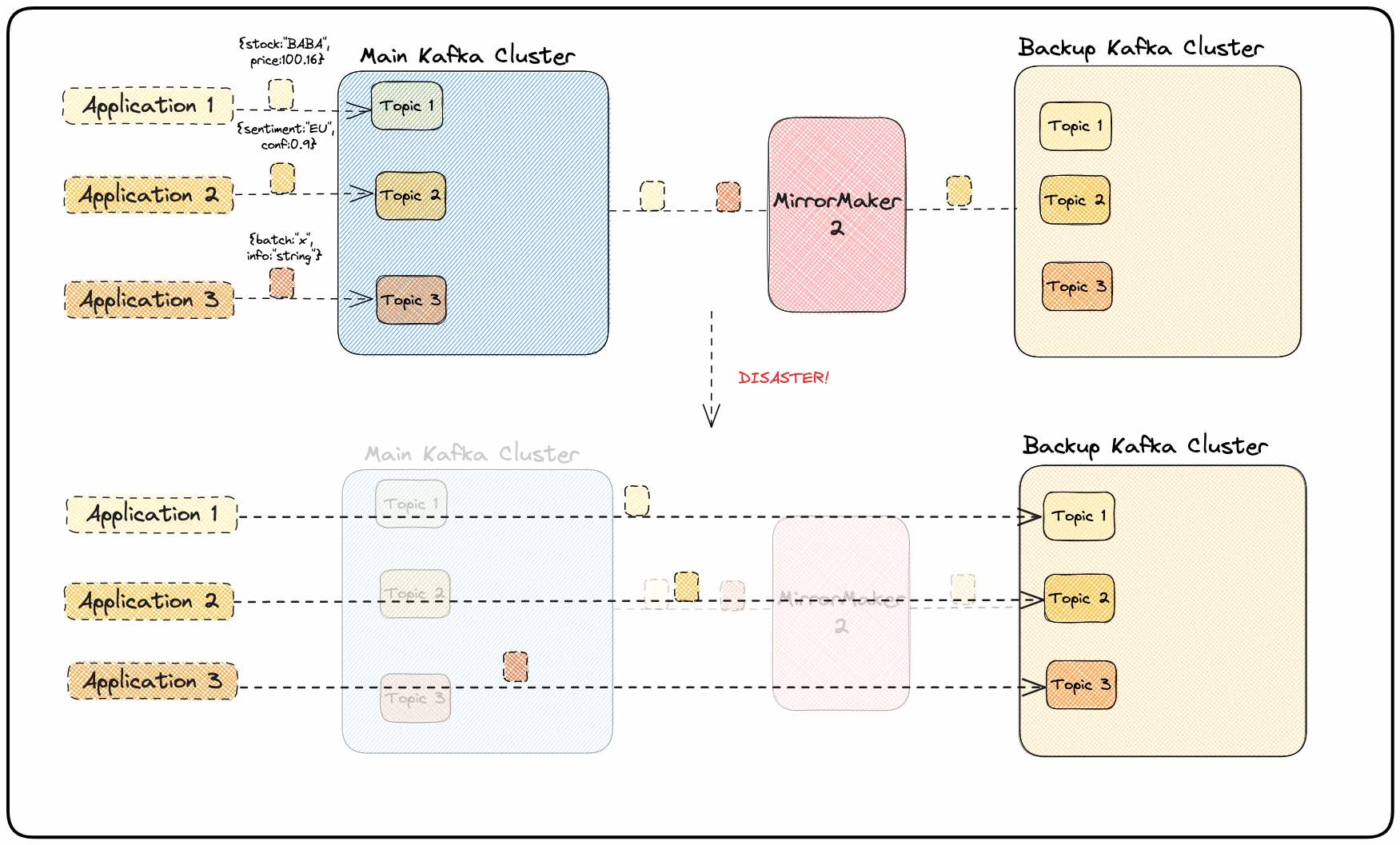
- Disaster recovery: In this case, data is continuously replicated from one Kafka cluster to another in a way that ensures a backup cluster can take over if the primary cluster experiences a failure or disaster. The backup Kafka cluster acts as a standby or secondary cluster that is kept in sync with the primary Kafka cluster using MirrorMaker 2. This allows applications teams to implement a failover mechanism which consists in switching their application configuration to use the backup cluster. Therefore, clients can continue producing and consuming data from the backup cluster at the same point they left off in the primary cluster, minimizing data loss and the impact on applications. This MirrorMaker 2 use case is illustrated in Figure 1.
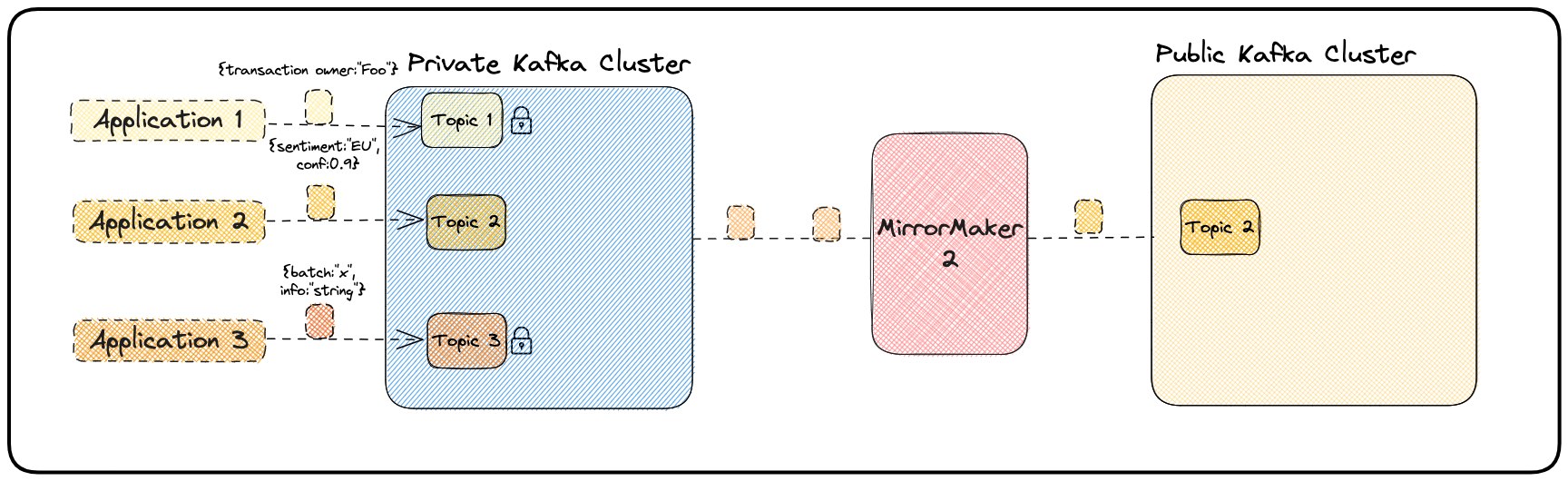
- Data isolation: This is an important aspect of data security and privacy, especially in scenarios where only a subset of data should be exposed publicly. With MirrorMaker 2, one may configure which topics should be replicated between the source (private) and target (public) clusters by specifying a list of topics or using regular expressions to define a pattern. Only the selected topics and their corresponding data will be exposed publicly, ensuring that sensitive data remains within the private cluster. This MirrorMaker 2 use case is illustrated in Figure 2.
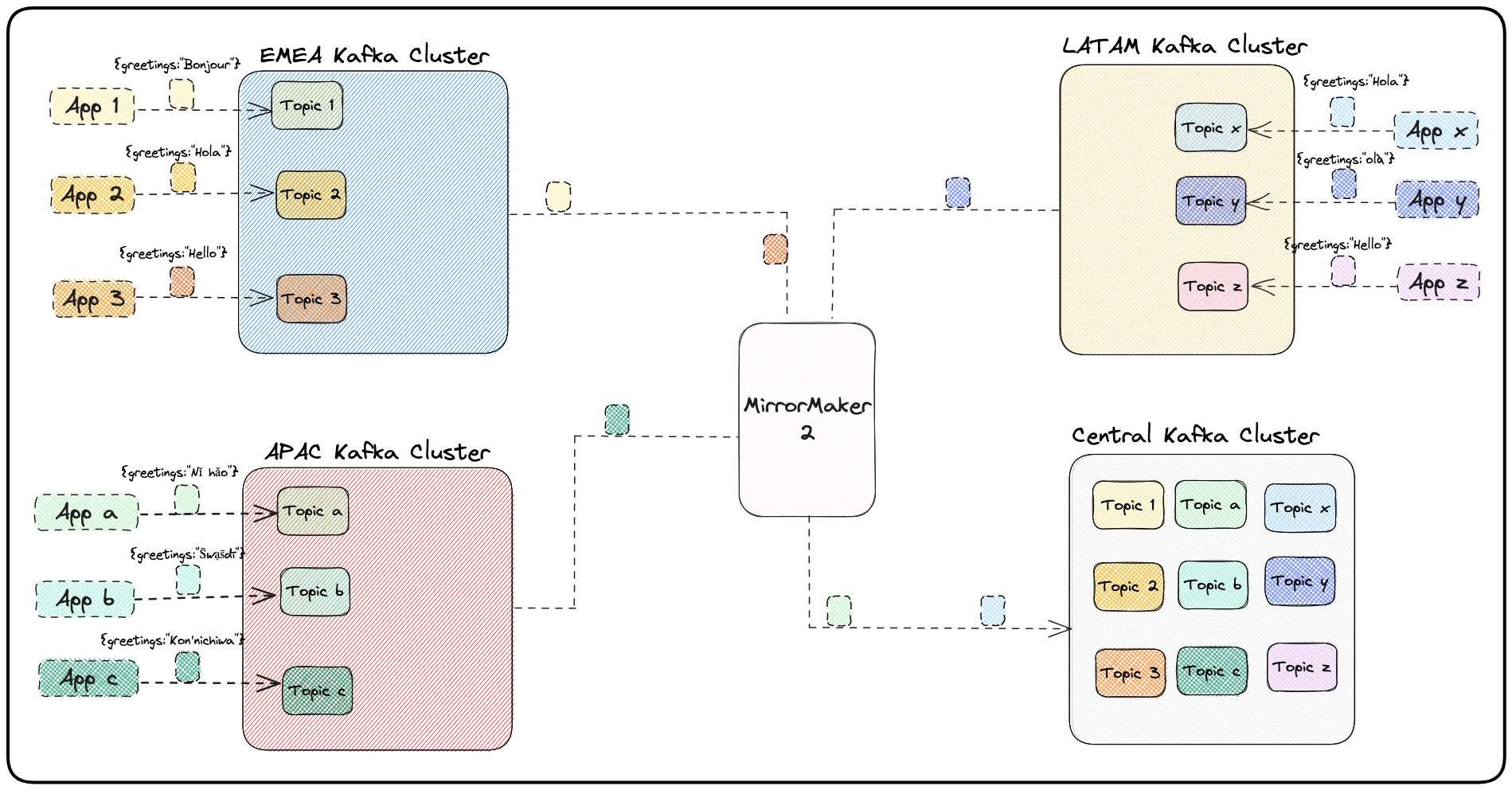
- Data aggregation: Data from multiple Kafka clusters can be replicated to an aggregation Kafka cluster. The aggregation Kafka cluster serves as a centralized location for consolidating data from all the source Kafka clusters. This cluster is specifically intended for data analytics, reporting, or other use cases that require a comprehensive view of the data from all source clusters. This MirrorMaker 2 use case is illustrated in Figure 3.
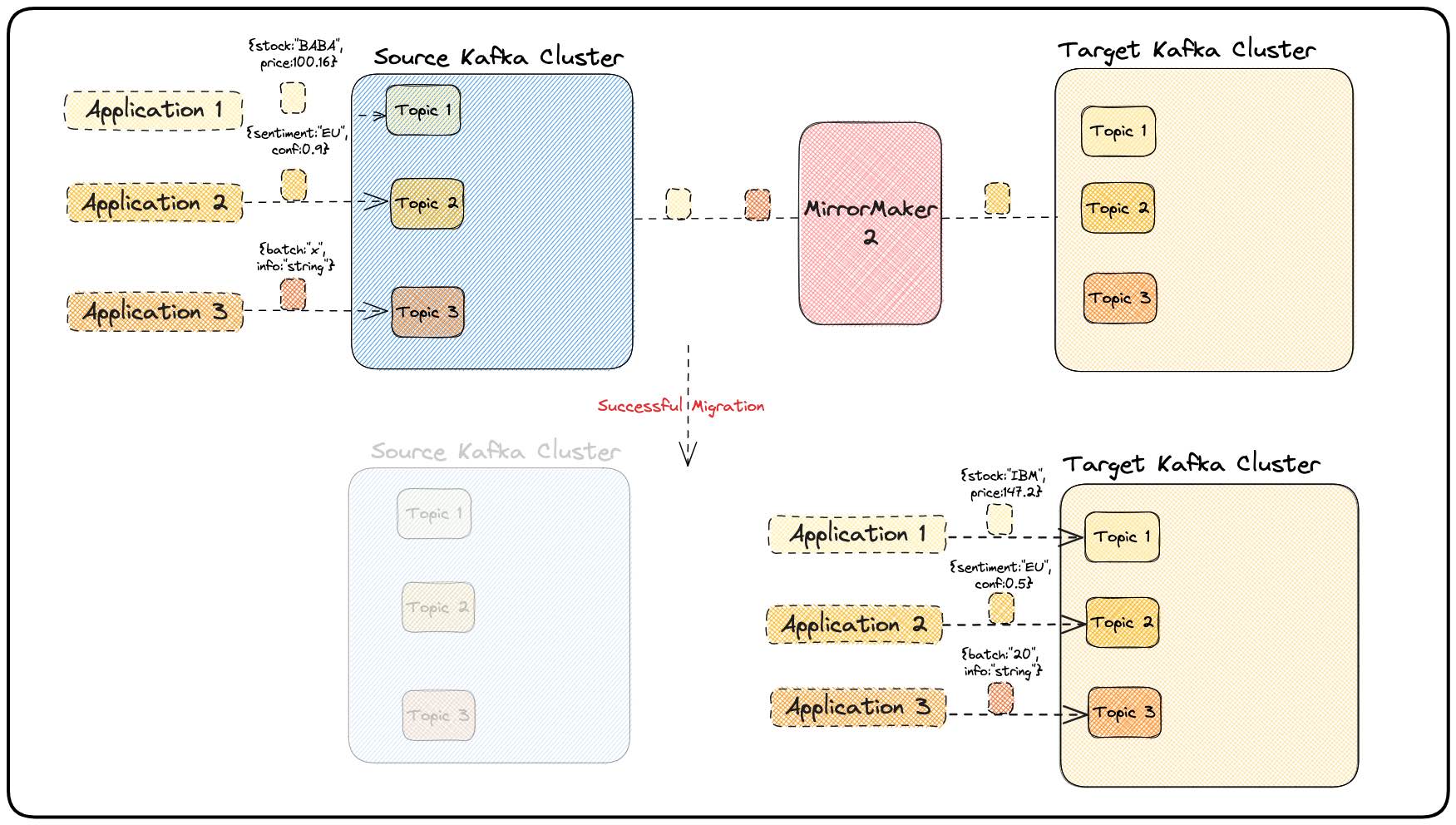
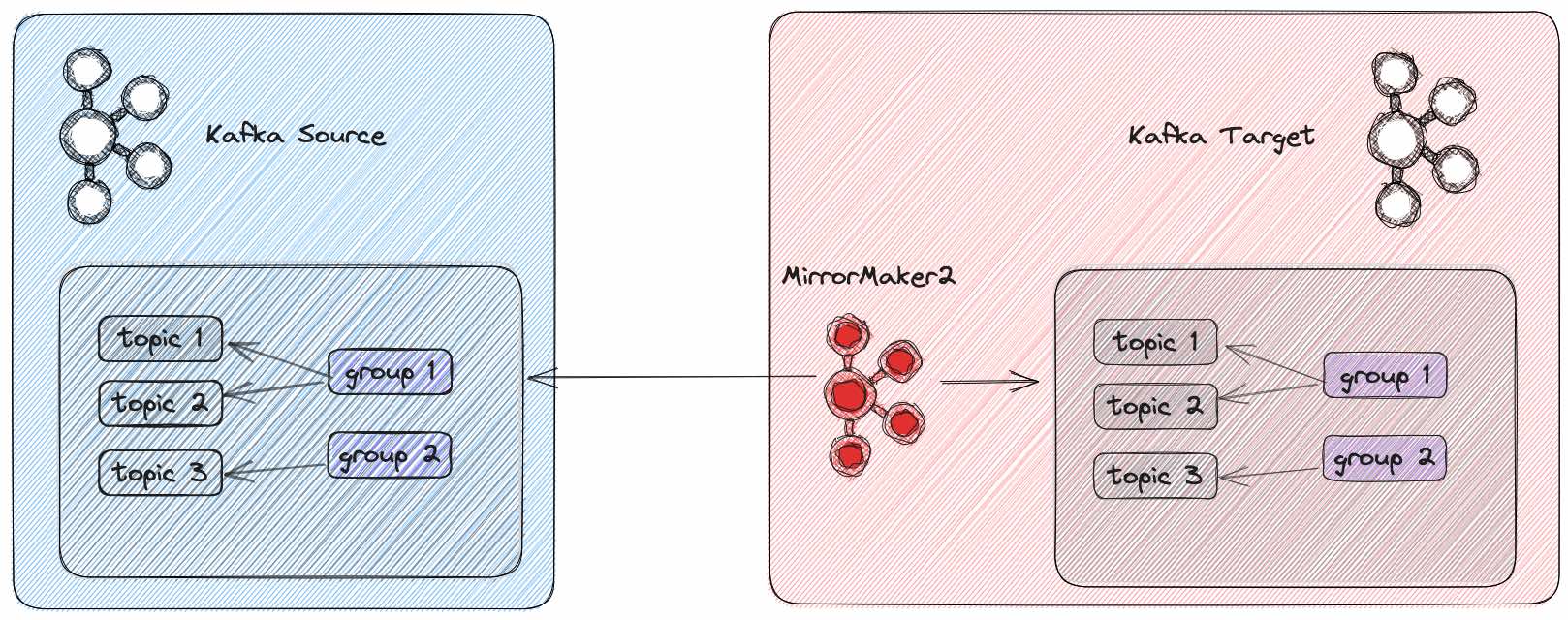
- Data migration: There are situations when data must be migrated from one Kafka distribution to another or from a Kafka cluster running in a cloud (or on-prem) to another cloud. MirrorMaker 2 can be very useful in this situation because it allows continuous streaming of data from the old cluster to the new one, while the Kafka client applications are updated and adjusted to switch to the new cluster in a defined time window. This MirrorMaker 2 use-case is illustrated in Figure 4.
MirrorMaker 2 is versatile with various use cases, but our emphasis here is on the migration scenario. The following sections, while centered on migration, can be applied to other MirrorMaker 2 scenarios with some adjustments.
Architecture components
To successfully understand how MirrorMaker 2 works, one needs to keep in mind that MirrorMaker 2 is built on top of Kafka Connect. Kafka Connect is a framework within Apache Kafka that eases the integration of Kafka with other systems. Indeed, it allows developers to stream data to Kafka from various external sources and vice versa (i.e., from Kafka to external systems). Kafka Connect operates in a scalable and fault-tolerant manner using connector plugins. MirrorMaker 2 relies on three key Kafka Connectors to perform data and offset replications. These special connectors are as follows:
- Source Connector is responsible for replicating the data between Kafka clusters.
- Checkpoint Connector is responsible for consumer groups offsets translation.
- Heartbeat Connector enables the monitoring of the health of a MirrorMaker 2 instance.
Architecture design scenarios
This section covers architecture design scenarios for the deployment of MirrorMaker 2.
Deployment location
As a best practice, MirrorMaker 2 should follow the pattern remote consume, local produce and hence should be deployed close to the target Kafka cluster (i.e., in the same network zone).
This provides the following advantages:
- Performance: Kafka producers are known to be more latency-sensitive than Kafka consumers. Hence, having the producers running in the same network as the target cluster, will make them more reliable and will also help to minimize overall replication latency.
- Flexibility: Depending on the shape of the data, MirrorMaker2’s producers can be finely tuned in order to replicate data more efficiently. Performing the tuning while the data is written over the local network could prove to be much more efficient and it would avoid network dependencies. For example, one can tune the batch size for the messages being written to the target cluster, but the network might have limitations to handle that or might be unreliable. Over the local network, there wouldn’t be such problems. More about tuning parameters will be explored in a subsequent blog.
Figure 5 exemplifies the deployment of MirrorMaker 2 leveraging remote consume, local produce pattern. The Kafka source cluster is deployed in a network zone. The Kafka target cluster is deployed in another network zone. MirrorMaker2 replicating the data unidirectionally between source and target Kafka clusters is deployed in the same network zone as the target Kafka cluster.
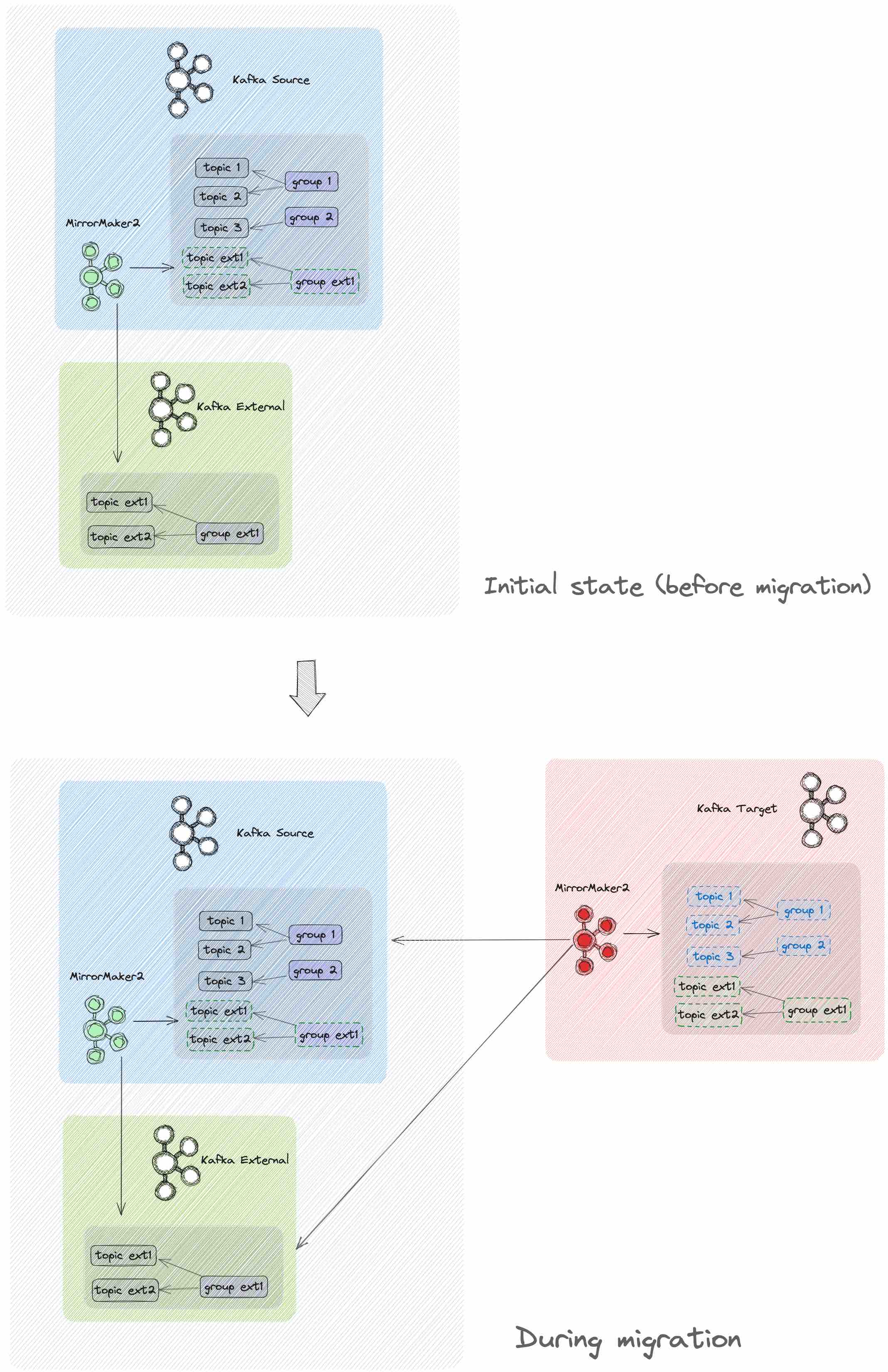
This pattern (with MirrorMaker 2 deployed close to the target) would also be the better choice when MirrorMaker 2 needs to replicate data from multiple source clusters. This is the case for a data aggregation scenario, but this is also valid for migration use cases. We have seen in our projects situations that in the initial scenario before the migration, the existing (source) Kafka cluster had a setup in which a different Kafka cluster was already replicating data to it. Hence, during the migration, the MirrorMaker 2 instance we set up needed to replicate data from two source clusters.
Figure 6 illustrates such a scenario. Before migration, there is a MirrorMaker 2 deployment that replicates the topicExt1, topicExt2, and groupExt from a Kafka external cluster to the Kafka source cluster. In the source Kafka cluster, there are three more topics (topic1, topic2, and topic3) and two more consumer groups (group1 and group2. During the migration, a new MirrorMaker 2 deployment is configured to replicate (1) the data (topic1, topic2, topic3) and the consumer groups (group1 and group2) from source Kafka cluster to the target Kafka cluster and (2) the data (topicExt) and the consumer groups (groupExt) from external Kafka cluster to the target Kafka cluster.
Considering these points, for most of the use cases MirrorMaker 2 deployed close to the target is the better choice. However, there might be situations when deploying MirrorMaker 2 near the source might be the optimal solution. One example could be when there are certain limitations to deploying MirrorMaker 2 in the target Kafka infrastructure while considering the network between the source and the target is very reliable and the bandwidth limit is not an issue.
So the architectural decision will ultimately depend on the specific use cases, network infrastructure, and other requirements.
One versus multiple deployments
For a migration scenario, there are certain design decisions that need to be made in terms of how MirrorMaker should be deployed. One of the important decisions to make is how many MirrorMaker 2 deployments (Kafka Connect clusters) will be required: a single and larger deployment that will handle the migration of all topics or multiple smaller deployments, each handling a specific group of applications.
In general, a single deployment would cover most of the use cases. An architecture using a single deployment of MirrorMaker will look like Figure 5.
However, there are situations when multiple deployments of MirrorMaker would make sense, for example:
- Replication efficiency: Specific topics might contain messages with a format or a size that may replicate more efficiently (i.e., improved throughput) with different MirrorMaker 2 tuning parameters than others. For example, message size or compression type might be some of these tuning parameters.
- Avoid using a single-point-of-failure. If for whatever reason, MirrorMaker is having issues during replication, this may affect all the topics in the course of migration. Having multiple MirrorMaker deployments, each handling a group of applications, will isolate potential migration issues.
When choosing multiple MirrorMaker deployments, then consider the following factors:
- Some internal MirrorMaker 2 topics created on source or target Kafka clusters, like offset.storage, config.storage, status.storage, or mm2-offset-sync need to be unique.
- All the consumer groups that require migration must be identified and mapped to a group of applications based on the topics they consume. Then they only need to be synced in the same MirrorMaker 2 deployment as the group of applications. However, if the consumer groups are consuming from topics from different groups of applications whose topics are replicated through different MirrorMaker 2 deployments, then they would require syncing by more MirrorMaker 2 deployments.
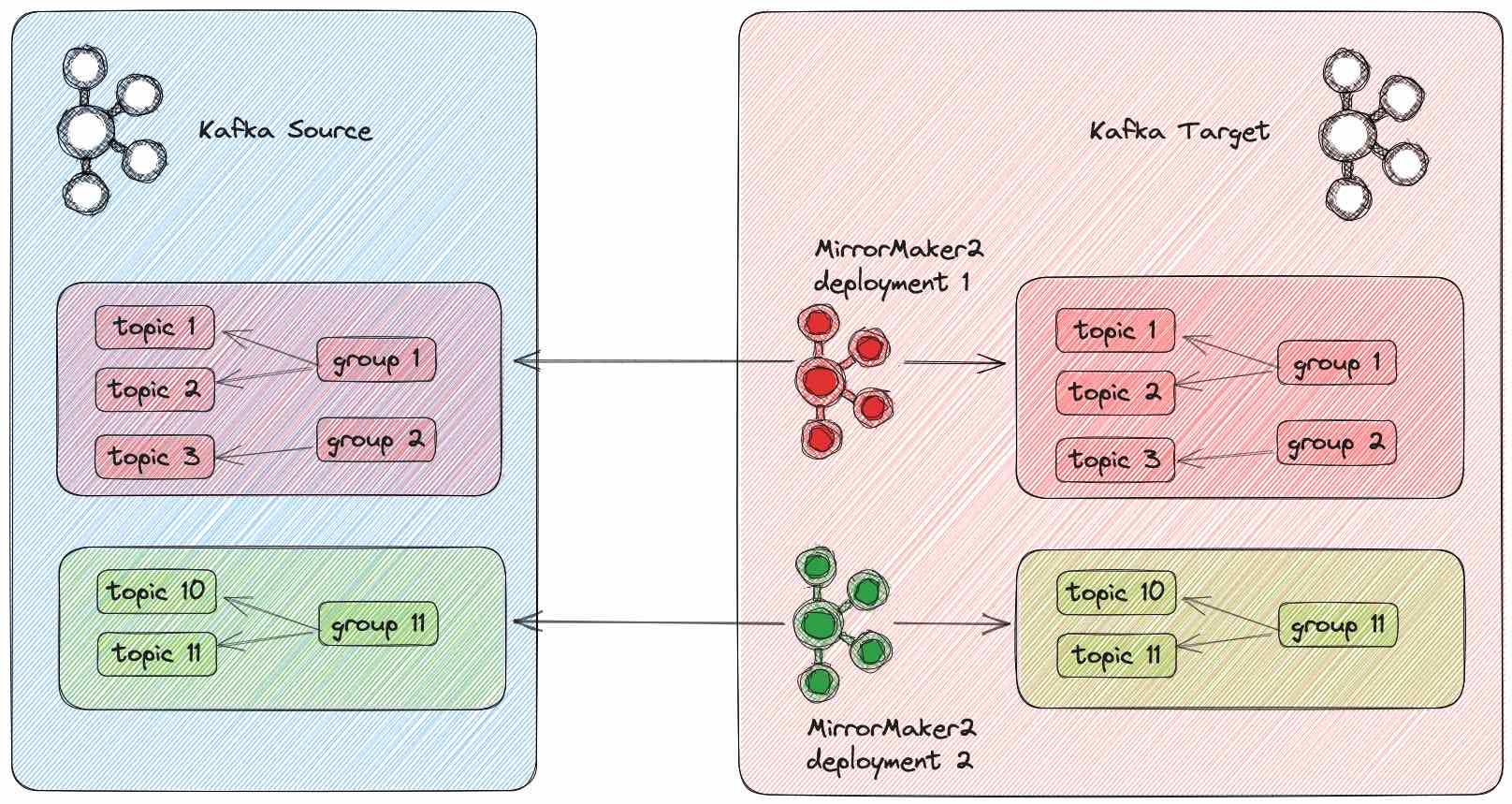
Figure 7 demonstrates an architecture using multiple MirrorMaker 2 deployments. There are two Kafka clusters: the source Kafka cluster and the target Kafka cluster. There are two MirrorMaker2 deployments as well. Both of them are deployed on the same network area as the Kafka target cluster. The first deployment will replicate topic 1, topic 2 and topic 3, as well as group 1 and group 2. The second deployment will replicate topic 10 and topic 11, as well as group 11.
Manual versus automated topic creation
By default, MirrorMaker 2 will create the topics it needs to replicate from the allow-list into the target cluster. However, when MirrorMaker 2 creates those topics, not all their configurations will be preserved.
Instead, MirrorMaker 2 will use the defaults for the target cluster. One of the most important settings that is not preserved is the min.insync.replicas. Having this set with a different value on the new Kafka cluster, might have serious consequences in terms of high-availability for that topic.
To ensure that all the topics that are being migrated have the same settings as on the source cluster, the recommended approach is to create those topics manually. If using Strimzi or AMQ streams, an easy way to achieve this is to create Strimzi KafkaTopic custom resources. The Kafka CLI tool can also be used for this purpose.
MirrorMaker 2 internal topics
As briefly mentioned in the previous section, MirrorMaker 2 creates several topics to track its state. Except for the mm2-offset-sync topic, all of MirrorMaker 2 internal topics are created into the target Kafka cluster. The mm2-offset-sync is created by default on the source Kafka cluster. But since Kafka 3.0.0, it is possible to deploy it on the target cluster, as described in this article.
Next, let’s explore these MirrorMaker 2 internal topics in more detail.
| MirrorMaker Internal Topics | Description |
| mm2-offset-sync.<target-cluster-name>.internal | This topic is used to track the synchronization of messages between source and target clusters for the topics that are configured to be replicated. Each message in this internal topic contains information about the data topics, partitions, the offset on source and the offset on target. The Source Connector writes to this topic, while the Checkpoint Connector reads from it. |
| <source-cluster-name>.checkpoints.internal | This topic contains information about the last committed offset in the source and target clusters for replicated topics and consumer groups. This topic is controlled by the Checkpoint Connector. |
| mirrormaker2-cluster-offsets (configurable name) | This topic stores the MirrorMaker2 connectors’ offsets, i.e. Source Connector and Checkpoint Connector The name of this topic can be configured using offset.storage.topic MirrorMaker2’s configuration parameter. |
| mirrormaker2-cluster-configs (configurable name) | This topic stores the MirrorMaker2 connectors’ configurations. The name of this topic can be configured using config.storage.topic MirrorMaker2’s configuration parameter. |
| mirrormaker2-cluster-status (configurable name) | This topic stores the MirrorMaker2 connectors’ status. The name of this topic can be configured using status.storage.topic MirrorMaker2’s configuration parameter. |
Now, let’s have a deeper look at the content of some of these internal topics.
Topic: mm2-offset-syncs.<target-cluster>.internal
To check the content of this topic, use the kafka-console-consumer CLI tool with the OffsetSyncFormatter. In this example, the offset information about a data topic called topic-name will be checked.
# kafka-console-consumer.sh --formatter "org.apache.kafka.connect.mirror.formatters.OffsetSyncFormatter" --bootstrap-server kafka-target:9092 --from-beginning --topic mm2-offset-syncs.prod-target.internal --consumer.config source.conf|grep topic-name
Result:
OffsetSync{topicPartition=topic-name-0, upstreamOffset=3650017, downstreamOffset=3397099}
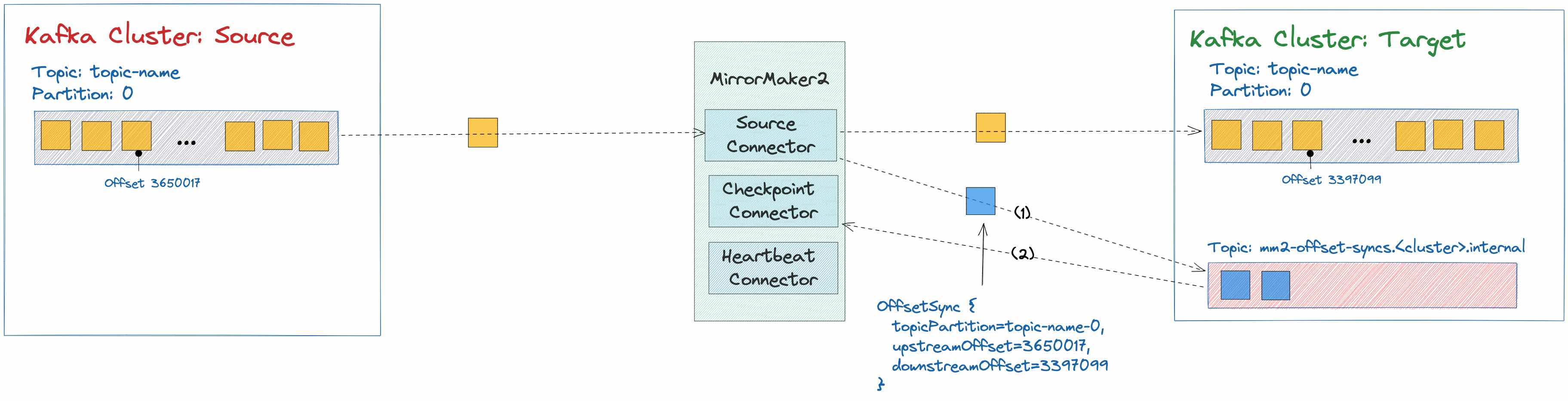
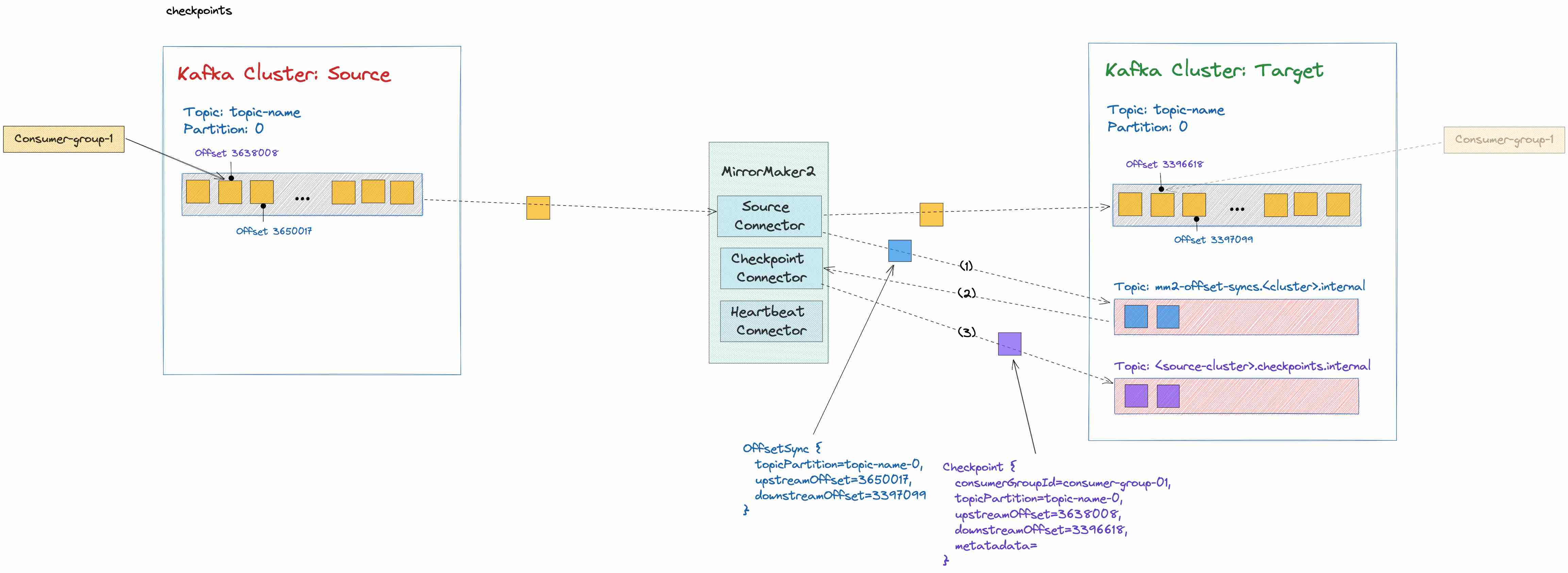
Figure 8 illustrates how MirrorMaker 2 leverages the mm2-offset-syncs.<target-cluster>.internal topic to synchronize messages between source and target cluster. MirrorMaker2 replicates topic-name from the source to the target Kafka cluster through the Source Connector. The Source Connector also writes offset information to the mm2-offset-syncs.<target-cluster>.internal topic. Then the Checkpoint Connector reads this to translate consumer group offsets.
Topic: <source-cluster>.checkpoints.internal
To check the content of this topic, use the kafka-console-consumer CLI tool again, but this time with the CheckpointFormatter.
# kafka-console-consumer.sh --formatter "org.apache.kafka.connect.mirror.formatters.CheckpointFormatter" --bootstrap-server kafka-target:9092 --from-beginning --topic prod-source.checkpoints.internal --consumer.config target.conf|grep topic-name
Result:
Checkpoint{consumerGroupId=consumer-group-01, topicPartition=topic-name-0, upstreamOffset=3638008, downstreamOffset=3396618, metatadata=}
Figure 9 illustrates how MirrorMaker 2 leverages the <source-cluster>.checkpoints.internal topic to perform consumer groups offsets translation. MirrorMaker 2 replicates topic name from source to the target Kafka cluster through the Source Connector. The Source Connector also writes offset information to the mm2-offset-syncs.<target-cluster>.internal topic. Then the Checkpoint Connector reads from mm2-offset-syncs.<target-cluster>.internal topic, performs consumer groups offsets translation, and writes translation information to the <source-cluster>.checkpoints.internal topic.
Topic: mirrormaker2-cluster-offsets
Remember, this topic is used by the Source Connector for tracking the position of the last transferred message for specific data topics and partitions. Let’s explore its content and grep only Source Connector messages. Let’s also filter only the messages the Source Connector produced about a topic named topic-name. Again, you can use the kafka-console-consumer CLI tool.
# kafka-console-consumer.sh --bootstrap-server=kafka-target:9092 --topic mirrormaker2-cluster-offsets --consumer.config target.conf --from-beginning --property print.key=true | grep MirrorSourceConnector | grep -i "topic-name"
Result:
["prod-source->prod-target.MirrorSourceConnector",{"cluster":"prod-source","partition":0,"topic":"topic-name"}]{"offset":59}
In this example, the last message transferred by the Source Connector to the target cluster for the topic-name and partition-0 is at offset 58 (on the source cluster).
Summary
In this article, we introduced Kafka MirrorMaker 2 as a tool for replicating data between Kafka clusters. We have explored MirrorMaker 2 use cases, architecture, and design scenario. We also took a deep dive into some of its internal components.
This is the first part of our series about MirrorMaker 2. In the next article, we will focus more on migration use cases and explore how MirrorMaker 2 can be deployed and fine-tuned to achieve optimal performance.
Last updated: October 25, 2024