This article provides a guide to eBPF application development. As the title suggests, the content is focused on eBPF 201 concepts rather than providing yet another eBPF 101-level article that describes what eBPF technology is. We provide a short introduction, but primarily focus on the next set of concepts and best practices for development teams that need to deploy production eBPF applications. We will explore the programming languages and toolchains that make BPF applications deployable and maintainable across multiple kernel versions and environments.
eBPF 101 : A brief recap
BPF/eBPF is an operating system kernel technology made up of a lightweight sandboxed virtual machine and a suite of helper functions. In this article, we focus on eBPF in the context of the Linux kernel, although it is also available on and being developed for other OS platforms such as Windows and FreeBSD.
This technology makes it possible to run user-provided programs inside the kernel to extend the kernel's capabilities. The verifier checks BPF programs before they get loaded into the kernel to ensure they cannot compromise kernel reliability. The programs get JITted to native instructions, so they are efficient enough to be executed inline in the most performance-demanding situations, such as network packet processing.
The overall benefit is to provide programmability and extensibility to the OS kernel in a manner that is safe, more flexible, and rapid to develop than developing kernel modules or direct enhancements to the main kernel functionality itself.
The diagram in Figure 1 shows an overview of the BPF virtual machine in the Linux kernel, the hook points where BPF programs can be attached, and the various maps and helpers available to BPF programs.
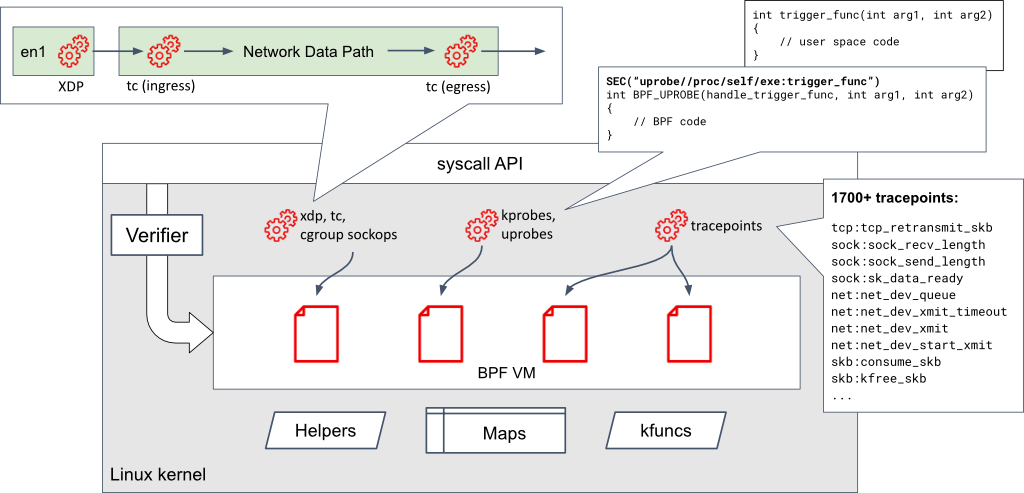
If you are new to eBPF, A thorough introduction to eBPF will provide a good foundation before reading the rest of this article.
Technology maturity
BPF has come a long way from the early days when it was introduced to Linux kernel as a packet filtering engine (Figure 2). Over the past decade, the eBPF VM has become a general-purpose execution engine supported by the Clang toolchain, with program types and helper functions for many different use cases. More recently, the focus has been on developer and operational user experience, supported by BTF, CO-RE, and libbpf.

BPF features have been introduced across many kernels from 3.15 to the latest 6.x release. It can be hard to figure out what feature set is available in any given kernel release. The BCC project maintains a useful list of BPF Features by Linux kernel version, which can help you identify feature availability in a given Linux kernel.
eBPF application development FAQ
Here are some common questions that developers ask when learning about BPF application development. In this article, we attempt to provide some answers to these questions while noting that the space is still evolving across the board, and some of this will change in future.
Q: What options do we have for programming languages and development tooling for eBPF-based applications, and what are the pros and cons of each?
A: This is addressed later in this article in the section Choosing your eBPF application stack.
Q: We understand eBPF concepts but have not done any kernel development so far. What do we need to know about relevant parts of the kernel source code and development environment for effective eBPF application development?
A: Prior kernel development experience is not needed in order to develop eBPF-based applications. However, a good understanding of the relevant functional area within the kernel is definitely recommended. For instance, when developing a networking application, you should understand some of the kernel internals related to networking sockets, kernel packet datapaths, netfilter functionality, and so on.
Q: What do we need to be aware of when developing eBPF applications in a cross-target manner where development happens on a range of development systems and kernel versions and at the same time there is a range of target systems and platforms with the goal of portability and maintainability across all these platforms?
A: This is covered later in this article in the section eBPF application cross-development, portability, CO-RE, and kernel API stability.
Q: What are some real-world operational models for distributing eBPF programs and concurrent installation of programs from multiple vendors into a single system?
A: At the time of writing, this is an emerging area of development. Currently, eBPF programs are commonly packaged as integral and non-separable sub-components within a larger project such as Cilium or Pixie. Combining and installing multiple such independent eBPF-based applications can result in inconsistent or erroneous behavior, especially if there is overlap in the eBPF attachment points used (as was illustrated in a recent case).
Newer projects such as libxdp and bpfd are in the process of adding functionality to address such operational issues. We expect to cover those projects in more detail in a future article.
Q: What is the upstream core eBPF development model, and how can we track upcoming eBPF functionality that is still under development?
A: New eBPF kernel infrastructure and functionality is developed in the "bpf-next" git repository of the Linux kernel and eventually merged into the main Linux repository to be released as part of official Linux kernel releases. The process is described in more detail in the BPF development FAQ.
Additionally, kernel BPF functions are increasingly being added as kfuncs (kernel functions). They provide an API that eBPF applications can call but one that is less stable than the set of kernel BPF helper functions, which are considered to be part of the kernel ABI. The in-use kfunc APIs will be supported and maintained, but are not part of the kernel ABI.
Q: What are the software licensing requirements to be aware of when writing eBPF applications ?
A: Components of the Linux kernel eBPF runtime are GPLv2 licensed. This includes components such as the reference interpreter, verifier, JIT compilers, and BPF helpers. All kfuncs and many (but not all) BPF helpers are GPL-licensed, which means that BPF applications will typically (although not always) need to be released under a GPL-v2 compatible license. Note that the BPF verifier will not permit the loading of a BPF application without compatible license attribution. To enable some permissive downstream code re-use, applications might consider using dual licensing to additionally license their BPF applications with a permissive license such as MIT, BSD-2-Clause, and others. Refer to the Linux kernel documentation's BPF licensing guidelines for further details.
Q: Does eBPF technology facilitate or intersect with kernel data plane offload technologies?
A: Hardware offload to smart NICs for Linux kernel functions and, in particular, networking is a broad topic that covers many technologies not in the scope of this blog. A brief note for now is that you can certainly leverage eBPF technologies for hardware offload. Certain smart NICs such as the ConnectX-6 for example, have support for offloading XDP based eBPF programs from a host CPU out to a CPU on the NIC.
Choosing your eBPF application stack
When starting a new eBPF project, a development team has to decide which software stack to use for the planned applications. There are a variety of programming languages and available libraries with differing levels of maturity and feature parity with the most recent kernel BPF capabilities.
The following software stacks are common choices for eBPF applications and would be a good choice for a new project:
- User space program in C, kernel space bpf program in C
- User space program in Golang, kernel space bpf program in C
- User space program in Rust, kernel space bpf program in Rust
These application development stacks are illustrated in Figure 3.
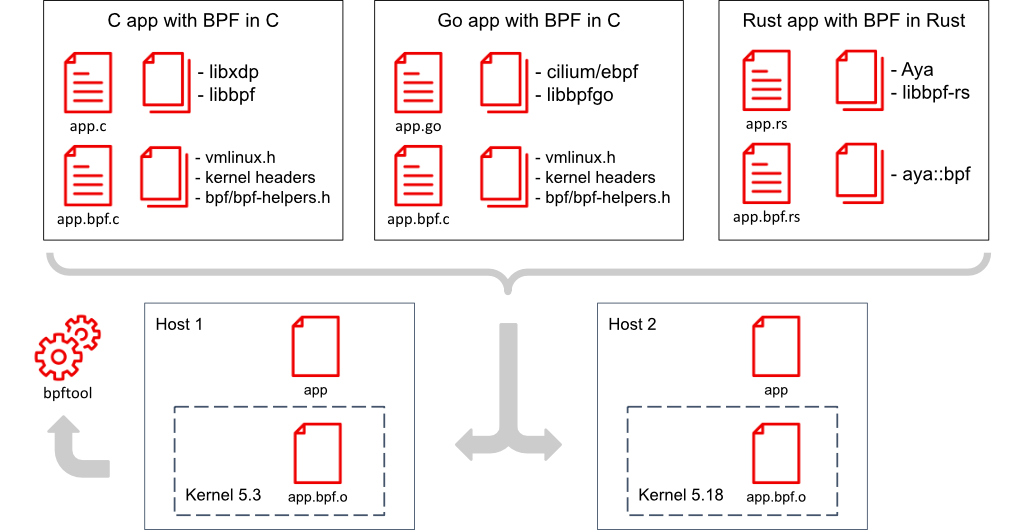
There is also a low-code option where a team can leverage available tools such as tc from iproute2, bpftool, and bpftrace to handle the user space and/or the kernel BPF program of the planned application.
A key point to note is that listing these options in this manner does not rule out mixing and matching across these and other options. For instance, you can write the kernel space eBPF program in C and a corresponding user space program in Golang or Rust, and there are often good reasons to do so. There are more options available, including writing your own custom eBPF loader via direct calls to the kernel ebpf syscall or using frameworks such as BCC. However, the options listed in this article will normally be preferable for new projects, and we limit discussion to those to illustrate some of the core concepts.
C and C with libbpf (and, optionally, libbpf-bootstrap)
This choice of software stack is typically the most fully featured and supports the latest eBPF functionality and tooling.
About libbpf
libbpf is a C library of eBPF utility functions and definitions that a user space program can use to manage kernel space eBPF programs. This application stack option is most up-to-date, is part of the upstream Linux source code repository, is aligned with the most up-to-date eBPF functionality, and is used to test new kernel eBPF functionality. Both this library and the kernel BPF code are written, reviewed, and tested together by kernel developers as part of introducing new eBPF functionality. libbpf is also the canonical implementation of the CO-RE (Compile Once Run Everywhere) functionality, which enables a significant improvement of the developer experience for providing eBPF program portability as discussed later.
In the Linux source repository, libbpf is present at tools/lib/bpf. The API documentation is available at https://libbpf.readthedocs.io/en/latest/api.html.
A mirror of libbpf is maintained separate from the kernel source, and that is the version that should be used to include in an application. This API includes several essential definitions such as prototype definitions of eBPF helper functions, user space type definitions to match with corresponding kernel types, and functions to load and attach programs and set up eBPF maps. The libbpf library achieved the version 1.0 release milestone in mid-2022 and is actively developed with version 1.2 recently released.
About libbpf-bootstrap
libbpf-bootstrap is one of the companion repos to libbpf and provides a useful set of templates and example programs that use libbpf functionality. This is a good jumping-off point for quickly writing a user space program that will work with the latest eBPF functionality. The libbpf-bootstrap repo also illustrates the use of the bpftool utility to prepare an eBPF skeleton program. A skeleton is a set of definitions of types and functions used by user space programs to easily open, load, attach, and destroy eBPF program objects.
Recommendations and takeaways
1. This is frequently a good choice of stack to use for writing eBPF applications.
In our view, this application stack is a solid option for a development team to adopt, especially if there is a need to use a C language user-space program or when there is a need for the latest and greatest eBPF functionality that might not always be available through other user-space loaders and utilities for other programming languages and tools.
As an example, at the time of writing, this was one of the only options that worked for the authors to manage, load, and attach eBPF applications that made use of new eBPF kfuncs (kernel funcs).
2. Include libbpf and bpftool as git sub-modules in your applications repo.
We also note that developers should typically use libbpf by including it as a Git sub-module within their application program repositories. This ensures that they are always using the latest released version of libbpf instead of either the version from kernel source they might have on their development system or the version that is bundled by their Linux distribution.
3. Consider using libbpf-bootstrap as a reference repo for your application program.
In the authors' view, libbpf-bootstrap is a good repository to use as a reference for new eBPF projects or libbpf-based applications in general. It is maintained as an example of best practices when using libbpf (for instance, the use of libbpf and bpftool as Git sub-modules).
Go and C with Cilium ebpf, libbpfgo
This option is a good choice when writing the user space portion of the eBPF application in Golang. This could be the case when the user-space portion of the eBPF application is a Kubernetes Operator or CRD controller, for instance, because those are often written in Golang.
The Cilium ebpf library is a standalone pure Golang library of eBPF utilities that is independent of the rest of the Cilium project applications such as the Cilium Kubernetes CNI plug-in. libbpfgo is another such library of eBPF utility functions that a user space Golang application could use to load eBPF object files (compiled from any language), attach to various eBPF hook points, and so on.
libbpfgo uses Golang wrapper calls around the C-language libbpf library that we discussed in the prior section and hence has the benefit of likely supporting more recent core eBPF functions. The Cilium eBPF library is not a wrapper around the libbpf library and has a somewhat more diverse community behind it (than does libbpfgo), including vendors Isovalent and CloudFlare.
Rust and Rust with Aya
Aya is a pure Rust library for BPF application development that aims to have feature parity with libbpf. Similar to the Cilium eBPF library described above, Aya does not consist of wrapper functions around the C-language libbpf library. As noted previously, the program language and toolchain used for eBPF kernel programs is independent of the language and tools used for the user space program of the application. We will describe this option in a future article where we will cover the Aya and bpfd projects in detail.
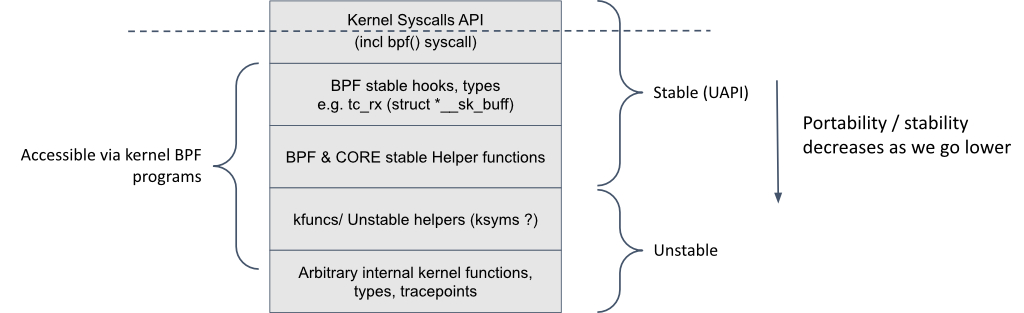
eBPF application cross-development, portability, CO-RE, and kernel API stability
Best practice eBPF application development involves designing for cross-platform development, portability, and maintainability from the start. Recent eBPF kernel enhancements such as CO-RE (Compile Once Run Everywhere) have greatly improved the developer experience in this area.
Figure 4 shows a development model that supports different development environments and different target systems. The development environment uses C with libbpf, as discussed in the previous section.
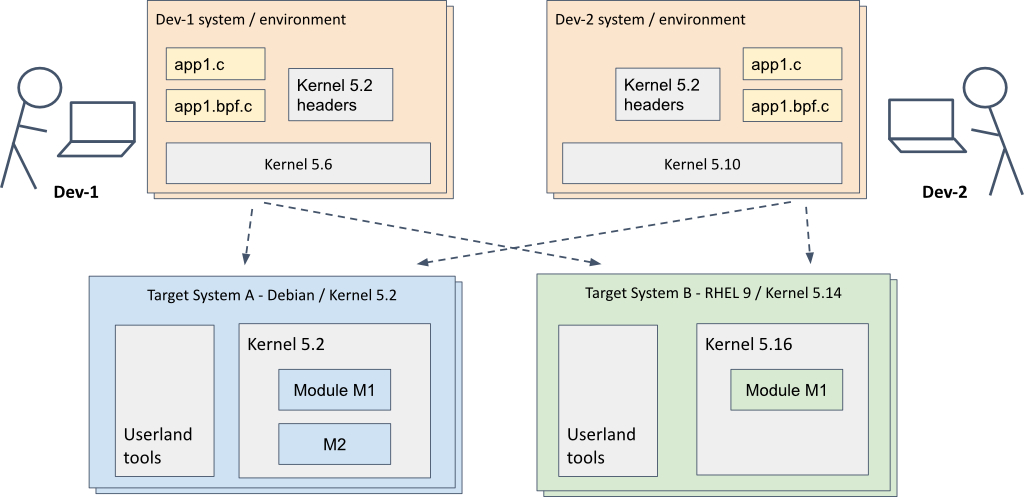
In the diagram, one developer is using a development machine that is running kernel 5.6, while another developer has kernel 5.10. The developers are each able to test on two different target systems, the first running Debian with kernel 5.2 and the second running Red Hat Enterprise Linux with the kernel upgraded to version 5.16.
Until recently, such a development model could not be used for eBPF applications, particularly those that interacted with raw kernel data types and structures that changed between kernel versions. Hence, eBPF applications had to compiled on the fly when loading on a target system (using other loader functionality such as BCC's embedded CLANG/ LLVM) in order to pick up kernel headers and type information of the actual target system kernel.
However, new eBPF infrastructure known as CO-RE (for Compile Once Run Everywhere) enables a single eBPF binary object to be loaded and run on different kernel versions without the need for recompilation or complicated workarounds. Refer to this article and its accompanying CO-RE guide for excellent details on CO-RE and best practices for developers.
Recommendations and takeaways
1. Where possible, use an eBPF loader that supports CO-RE based kernel data type relocation capability.
All 3 application stack options discussed in the prior section of this article support CO-RE. Other eBPF loader options, such as the BCC framework, do not support CO-RE at this time.
2. Use CO-RE best practices.
These include the use of compiler/Clang attributes such as __attribute__((preserve_access_index)) to ensure relocatability of kernel data types used by the eBPF program, the use of helpers such as the BPF_CORE_READ() macro to efficiently access kernel data even with multiple levels of pointer indirection and the use of CO-RE capabilities for programmatically detecting kernel versions and kernel config information to deal with more complicated kinds of kernel data type changes as described in the CO-RE guide.
3. Consider using vmlinux.h to simplify header file includes instead of kernel header files packaged in the development system.
The file vmlinux.h is a file that can be generated, via the bpftool utility, to include all data types in a kernel image. This is a convenient single header file to include from eBPF programs instead of a broad and somewhat ad hoc set of kernel header files that may differ from one developer's system to another. We recommend creating a trimmed-down version of this file with just the kernel definitions that your application actually needs. This ensures that you:
- benefit from being aligned with data types for your target kernel versions
- can take greatest advantage of CO-RE relocation
- have right-sized header files that can be more easily maintained
4. Test eBPF applications against all targeted kernel versions and relevant subsystem configurations.
Even if you follow all the CO-RE best practices, it is important to test any eBPF application with all or a wide set of kernel versions as well as variations in configuration of relevant kernel subsystems and modules in order to ensure full confidence in its portability and correctness across all targeted deployments.
5. Determine the minimum kernel version that your application needs.
It is a good idea to start by reading BPF Feature Documentation to identify the range of kernel versions that contain the features you need. For example:
- cgroup/connect4 program support was added in 4.17.
- BPF bounded loops were added in 5.3.
You then have a choice to either write your app to use only eBPF functions that are available in the kernel versions you need to support, or use BPF feature probing to detect the availability of features at runtime.
Your BPF program can check the kernel version:
#include <bpf/bpf_helpers.h>
extern int LINUX_KERNEL_VERSION __kconfig;
int probe_kernel()
{
if (LINUX_KERNEL_VERSION > KERNEL_VERSION(4, 18, 0)) {
/* we are on a supported kernel version */
} else {
/* log an error and exit gracefully */
}
...
}
Your BPF program can also probe for individual kernel features or struct definitions:
extern bool CONFIG_LWTUNNEL_BPF __kconfig __weak;
if (CONFIG_LWTUNNEL_BPF) {
/* configure lwtunnel from BPF */
}
if (bpf_core_type_exists(struct bpf_ringbuf)) {
/* use ringbuf instead of perf buffers */
}
Architecture of a running BPF program
Figure 6 shows a view of a user space application and its embedded BPF program. The application is linked against libbpf, which does the BPF map creation and program loading on the application's behalf.
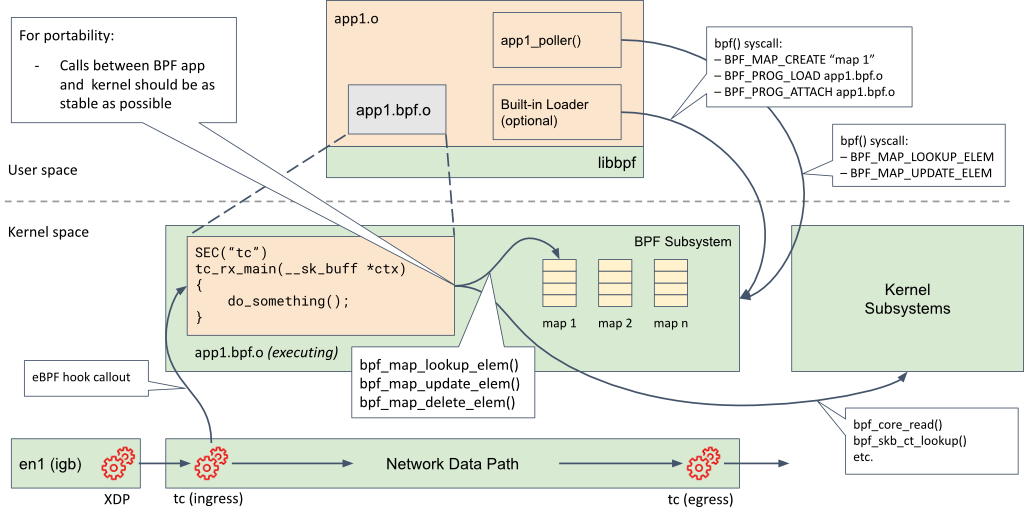
In this diagram, we see that the BPF program gets attached to the tc hook in the network data path. The user space application and the BPF program have shared access to maps that are managed by the BPF subsystem in the kernel. The BPF program also uses helper functions to access data from other kernel subsystems.
An example C application using libbpf
The topics discussed here are best demonstrated with an example application. We will use a DNS tracing utility to highlight the main points.
libbpf-bootstrap provides a good starting point for a C project that uses libbpf. Here, we have created a project for the dns-trace utility by copying the Makefile and project layout from libpf-bootstrap and adapting it to our needs:
. ├── Makefile ├── dns-trace.bpf.c # BPF code ├── dns-trace.c # User space code ├── dns-trace.h # Shared definitions ├── libbpf # libbpf git submodule └── .output ├── dns-trace.skel.h # skeleton, generated by bpftool └── vmlinux.h # all kernel type definitions, generated by bpftool
Shared definitions
The dns-trace utility has a BPF part that intercepts DNS packets and a user space part that decodes DNS messages and reports various metrics. The data captured by the BPF program is sent to the user space program as a stream of events via a BPF ring buffer. The struct dns_event is used both in the BPF and user space programs. Be careful to ensure that the type definitions can be resolved for both compilation units.
-
The user space program uses system header files, including the UAPI exported kernel types like
__u32and the libbpf headers. -
The BPF program also has access to the UAPI exported kernel types when
<bpf/bpf_helpers.h>is included but typically also has all kernel type definitions when the generated<vmlinux.h>is included.
Any structs that will included into both compilation units need to use the UAPI exported kernel types and avoid the kernel's internal type definitions.
struct dns_event {
__u64 duration;
char ifname[IFNAMSIZ];
__u32 srcip;
__u32 dstip;
__u16 length;
unsigned char payload[MAXMSG];
__u16 id;
__u16 flags;
};
Accessing kernel data structures
The BPF program attaches to the net_dev_queue kernel tracepoint to intercept all packets sent or received by any program running on the host. The tracepoint context includes a pointer to the struct sk_buff that holds the packet data. We are only interested in accessing thesk_buff->data and sk_buff->len fields so we can use CO-RE to access them. The BPF program defines its own private version of struct sk_buff that contains only the fields we need. The struct is annotated with the preserve_access_index attribute so that the CO-RE relocation can happen when the BPF program gets loaded.
struct sk_buff {
unsigned char *data;
unsigned int len;
} __attribute__((preserve_access_index));
struct trace_event_raw_net_dev_template {
struct sk_buff *skbaddr;
} __attribute__((preserve_access_index));
This project-local struct sk_buff definition makes it clear to a program maintainer what subset of the struct we actually need. The C code uses the BPF_CORE_READ() macro to access the struct sk_buff fields, again to enable CO-RE relocation to the running kernel when the BPF program gets loaded.
SEC("tracepoint/net/net_dev_queue")
int trace_net_packets(struct trace_event_raw_net_dev_template *ctx) {
unsigned char *data = BPF_CORE_READ(ctx, skbaddr, data);
unsigned int len = BPF_CORE_READ(ctx, skbaddr, len);
do_trace(data, len);
return BPF_OK;
}
The user space application
The user space application uses libbpf via a generated skeleton for BPF program loading and accessing the maps defined in the BPF program. The skeleton is generated by bpftool gen skeleton in the project Makefile. The skeleton is derived from the BPF program, so all maps should be defined in the BPF C code and then referenced via skeleton accessors in the user space code.
The generated skeleton provides functions for loading the BPF code and attaching the BPF programs:
/* Load and verify BPF object file */
skel = dns_trace_bpf__open();
if (!skel) {
fprintf(stderr, "Failed to open and load BPF skeleton\n");
return 1;
}
/* Load & verify BPF programs */
err = dns_trace_bpf__load(skel);
if (err) {
fprintf(stderr, "Failed to load and verify BPF skeleton\n");
goto cleanup;
}
/* Attach tracepoints */
err = dns_trace_bpf__attach(skel);
if (err) {
fprintf(stderr, "Failed to attach BPF skeleton\n");
goto cleanup;
}
Very little code is required to set up and poll a BPF ring buffer from the user space program:
struct ring_buffer* ringbuf =
ring_buffer__new(bpf_map__fd(skel->maps.dns_events), process_event, NULL, NULL);
while (!exiting) {
ring_buffer__poll(ringbuf, 100);
}
The application receives events from the BPF program's ring buffer, using the struct dns_event definition that is shared with the BPF program.
eBPF documentation landscape
There is a lot of documentation available for the BPF subsystem and supporting libraries, but it is spread across various different locations. Here are some helpful links to the most useful documents.
- eBPF Foundation: eBPF Documentation
- Kernel docs: BPF Documentation, BPF Maps, Program Types, BPF kfuncs
- Man pages: bpf-helpers, bpftool
- Library docs: libbpf, libxdp, Aya, Cilium ebpf
- Reference blogs: BPF CO-RE Reference Guide
- Examples: libbpf-bootstrap, Practical BPF Examples
Note that there is no single definitive guide to BPF and that there is still a lot of unwritten knowledge.
eBPF terminology
- BTF: BPF Type Format is a compact encoding for storing type information about the Linux kernel or BPF programs. It is used to enable BPF program portability using BPF CO-RE.
- CO-RE: BPF CO-RE (Compile Once - Run Everywhere) makes it possible to write portable BPF applications that can run on multiple kernel versions without modification or recompilation for the target machine.
- The Kernel User-space API (UAPI): The UAPI is the interface between the Kernel and user-space, made up of syscalls, header files, sysfs, procfs, BPF helpers, etc.