Open vSwitch has moved away from using per-vport dispatch mode to using per-CPU dispatch mode. But this mode had issues with upcall handler thread imbalance and CPU mismatch error messages. These issues were mostly found in systems with tuned CPUs.
This article explains two main fixes that my patch series applied to Open vSwitch that alleviated these issues. The first fix resulted in the ovs-vswitchd sending an array of a size that the Open vSwitch kernel module will accept and not trigger the CPU mismatch error message. The second fix added additional upcall handler threads in cases of tuned CPUs to create a more balanced workload for the upcall handler threads.
History of dispatch modes in Open vSwitch
In July 2021, my former colleague, Mark Grey, introduced per-CPU dispatch mode to Open vSwitch. This dispatch mode was made to fix issues found in the old per-vport dispatch mode. In Open vSwitch, the per-vport dispatch mode creates a netlink socket for each vport. The introduction of per-CPU dispatch mode fixed a number of issues found in per-vport mode including packet reordering and thundering herd issues.
The per-CPU dispatch mode differs from per-vport mode in that the number of netlink sockets created in the per-CPU dispatch mode is equal to the number of upcall handler threads created. And most importantly, each netlink socket maps to exactly one upcall handler thread. The idea behind per-CPU dispatch mode is to have a one-to-one correspondence between CPU, netlink socket, and upcall handler thread, as shown in the diagram in Figure 1. This idea fixed the old issues in per-vport mode.
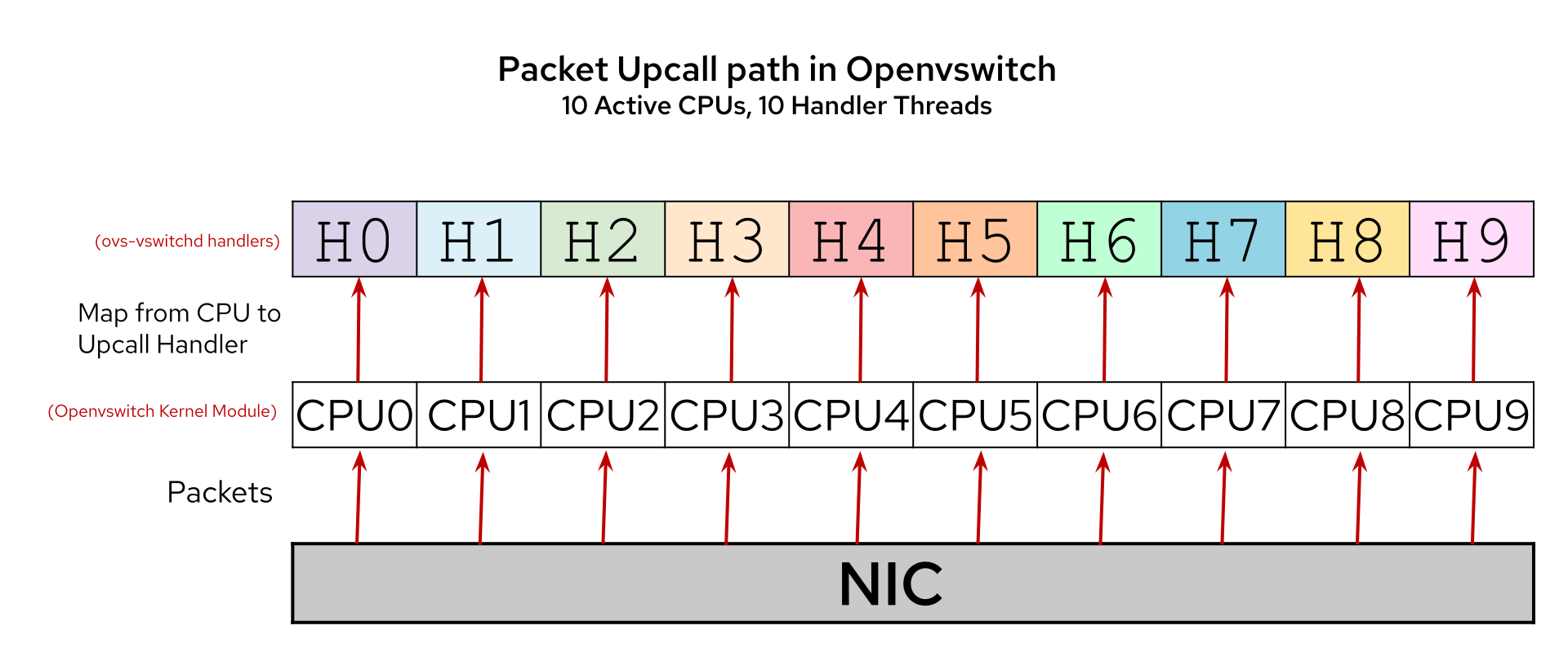
A user can determine which mode their system is running via the following command: ovs-appctl dpif-netlink/dispatch-mode. The dispatch mode defaults to per-CPU when using a kernel at least 4.18.0-328.el8.mr1064_210805_1629 and cannot be changed by the user.
One intentional side effect of the per-CPU dispatch mode is that now users cannot change the number of upcall handler threads via the user-configurable variable n-handler-threads in per-CPU dispatch mode. The user-configurable variable n-handler-threads only works in per-vport dispatch mode. In per-CPU dispatch mode, the number of upcall handler threads is determined by the number CPUs in which ovs-vswitchd can run on, which is largely affected by the affinity of ovs-vswitchd or the number of tuned CPUs via CPU isolation.
After merging the per-CPU dispatch mode, there were bugs (BZ#2102449, BZ#2006605), reporting that Open vSwitch kernel module threw the following error message: openvswitch: cpu_id mismatch with handler threads. These CPU mismatch error messages typically happened on systems with tuned CPUs or disabled cores.
What caused the problem?
The CPU mismatch error message originates from the fact that the Openvswitch Kernel Module expects an array with a size equal to the number of CPUs in the system as shown in the following code snippet in the Linux kernel net/openvswitch/datapath.c where handlers_array_size is the size of handlers_array and cpu_id is the CPU in which the upcall happened on the system.
if (handlers_array_size > 0 && cpu_id >= handlers_array_size) {
pr_info_ratelimited("cpu_id mismatch with handler threads");
return handlers_array[cpu_id % handlers_array_size];
}
Each index of the handlers_array corresponds to the CPU ID on which an upcall can occur and each element in the array is a netlink socket file descriptor corresponding to an upcall handler thread. The array maps upcalls that happen on a particular CPU to a corresponding upcall handler thread via the contained netlink socket file descriptor in the array. The array determines which upcall handler thread will receive the upcall.
The problem is that ovs-vswitchd was not sending an array of the expected size, and it was not sending a mapping for all CPUs. Instead, it was sending an array with a size equal to the number of upcall handler threads. As mentioned earlier, the default behavior in ovs-vswitchd is to create as many upcall handler threads as there are available CPUs for ovs-vswitchd to run on. This is not a problem when the CPU affinity of ovs-vswitchd is not set.
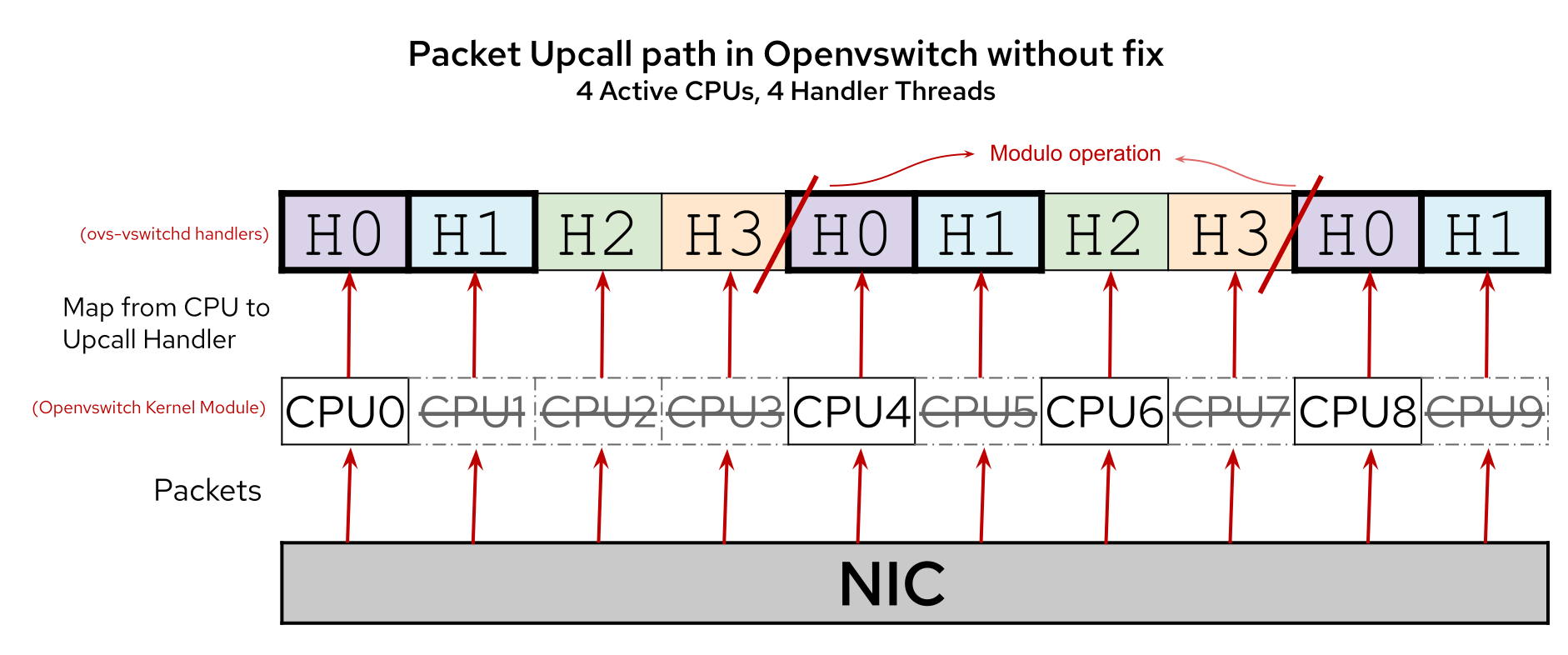
However, it is a problem when the CPUs are tuned or disabled, or the affinity of ovs-vswitchd is changed. The default behavior is to create as many upcall handler threads as there are available CPUs for ovs-vswitchd to run on, but if we have tuned or disabled CPUs the number of upcall handler threads will be less than the total number of CPUs. We would hit the condition cpu_id >= handlers_array_size when the system receives an upcall on a CPU ID that is larger or equal than handlers_array_size causing the CPU mismatch error message (Figure 2).
The CPU mismatch impact
The most visible impact is the CPU mismatch error message. But there are other more severe issues that can occur. One of them is overloading upcall handler threads while simultaneously starving others in the case of fixed Receive Packet Steering (RPS), powered off CPUs, or unplugged CPUs, which will be discussed later. This can happen as a side effect of the Open vSwitch kernel module using a modulo operation (shown in the previous code snippet) on the array when there is a CPU mismatch. In essence, some upcall handler threads get all the workload, while others are always on standby. This is an obvious misuse of CPU utilization.
There is also an issue of not having enough upcall handler threads to service the upcalls. Isolated CPU cores can still receive packets even if the core is isolated, and can still trigger an upcall. We still need upcall handler threads to service upcalls triggered by isolated CPUs. We cannot just create as many upcall handler threads as there are non-isolated CPUs because we would underperform in cases with high upcall usage across non-isolated and isolated CPUs. So we should ideally increase the number of upcall handler threads in CPU isolation cases to create a more balanced workload.
Figure 2 shows a system configured with four active CPUs for ovs-vswitchd to use, but it only created four upcall handler threads. Two of these upcall handler threads (H0, H1) have to service three CPUs each while the other two upcall handler threads (H2, H3) only have to service two CPUs.
2 Solutions to improve CPU performance
The fix is two-fold. First, create an array that’s big enough to not trigger the CPU mismatch error message. How we go about deciding how big to create the array is not as straightforward as one would think. Count the total number of CPUs regardless of if they are active or not. That would work, but not on all systems. Some systems have noncontinuous CPU Core IDs. For example, the largest CPU core ID in a particular system is CPU9, but this system only has four CPUs (Figure 3).
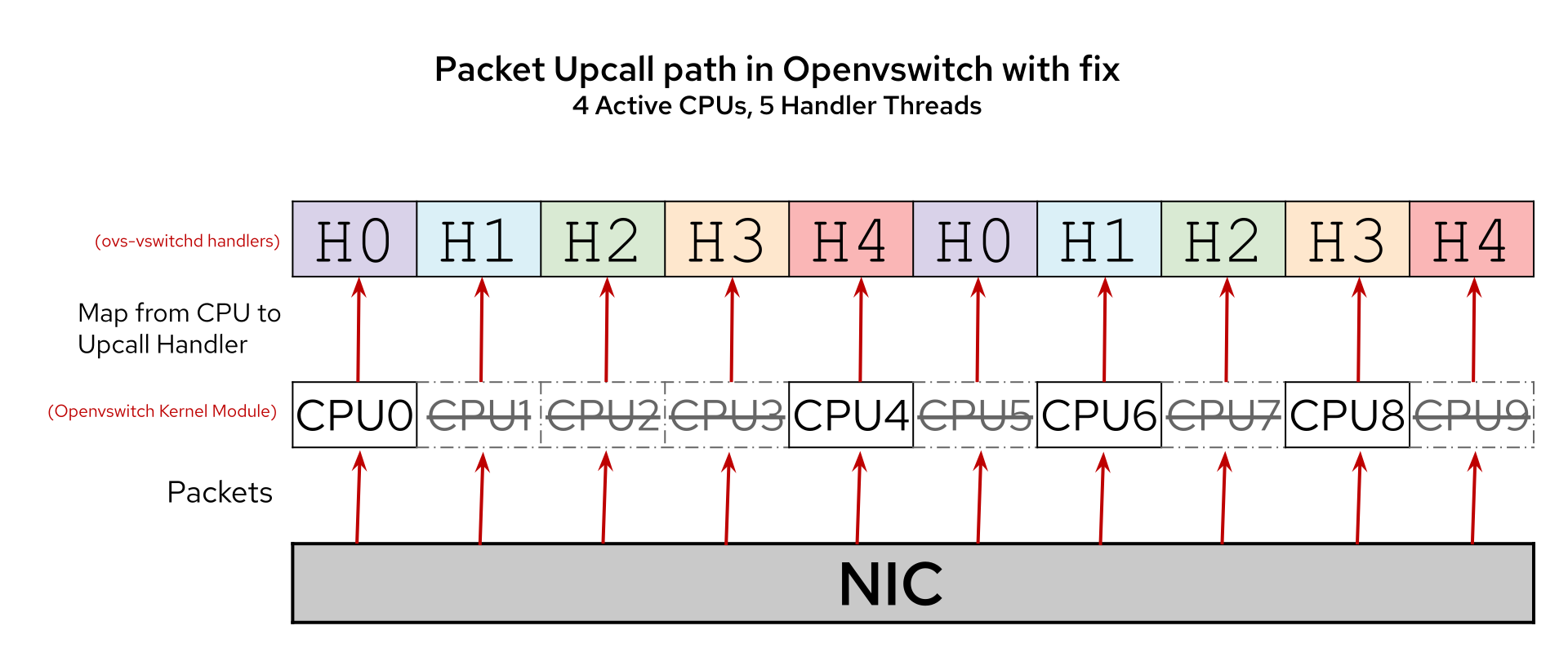
If ovs-vswitchd sent an array of size 4 to the Open vSwitch kernel module and the system gets an upcall on CPU9, it would still throw a CPU mismatch error message, as previously explained.
Instead, ovs-vswitchd sends the OVS kernel module an array of size:
size = MAX(count_total_cores(), largest_cpu_id + 1)
The count_total_cores would be the total number of CPUs, and largest_cpu_id is the largest CPU in the system. In the previous example, this would be size 4 and CPU9 (don’t forget to add +1) respectively, then pick the largest of the two numbers. This guarantees that the ovs-vswitchd sends the size the Open vSwitch kernel module expects. This prevents the CPU mismatch error message. The reason this works is because the Openvswitch Kernel Module side gets the upcall from CPU9 and checks to see if CPU9 is less than the array size 10 the ovs-vswitchd sent. Since 9 is less than 10, we do not trigger the mismatch. If ovs-vswitchd had sent an array of size 4, we would have triggered a CPU mismatch. This is the complete fix.
Secondly, we decided to go one step forward and try to create a more fair distribution of upcalls amongst the upcall handler threads by increasing the number of upcall handler threads. An upcall can happen on any CPU, even on CPUs that are isolated. Normally, ovs-vswitchd does not have isolated CPUs. In this case, ovs-vswitchd creates as many upcall handler threads as there are CPUs.
But in the case that we have isolated CPUs ovs-vswitchd would normally create as many upcall handler threads as there are non-isolated CPUs. This can be an issue because ovs-vswitchd still need upcall handler threads to service the upcalls that happen on isolated CPUs.
This is where the additional upcall handler threads come in. Having additional upcall handler threads provides the system with a more fair distribution of upcall workload amongst isolated and non-isolated CPUs. This also improves the imbalance of overloading some upcall handler threads that are found in fixed Receive Packet Steering (RPS), powered off CPUs, or unplugged CPUs. But it does not completely fix it. It helps because the more threads, the more the likely that each actually active CPU gets a unique upcall handler thread and reduces the amount of workload per thread.
The formula for deciding the number of upcall handler threads is as follows:
handlers_n = min(next_prime(active_cores+1), total_cores)
Where next_prime(argument) is a function that returns the argument if argument is a prime number or the next prime after argument. This guarantees that ovs-vswitchd has additional upcall handler threads in the case that the system has CPU isolation, but not exceed the maximum number of CPUs. The ovs-vswitchd fills in the array in a round-robin fashion where ovs-vswitchd rotates the upcall handler threads. ovs-vswitchd also uses the modulo operator to restart counting from the first upcall handler thread.
I took all the above suggestions and got a patch series merged into Open vSwitch upstream that fixes the Upcall Handler Thread mapping. In Figure 3, we have a system with my patch series applied with ten CPUs, but only four of them are actually available for ovs-vswitchd to use. In this example, ovs-vswitchd creates five upcall handler threads based on the previous equation when using active_cores = 4, total_cores = 10. Also, each upcall handler threads get the same number of CPUs they need to service.
Caveats
This implementation is not a perfect solution. There are many edge cases that this implementation does not address. But we have found that this implementation is the most balanced solution. A better implementation might dynamically change which handlers serve which CPUs according to the RPS scheme used by the NIC for the most optimized performance, but that comes at additional computational overhead.
This implementation is not aware of which CPUs are non-existent or plugged in, which means that there could be cases where you could overload handlers while starving others. This is true in cases of non-existing CPUs or hot-swappable CPUs.
Related works
My colleague, Adrián Moreno Zapata, built on top of my work and got a patch series merged that allows for a dynamic number of upcall handler threads when the number of CPUs change during ovs-vswitchd run time. The number of CPUs can change for many reasons during run time, including CPUs being hot-plugged, switched on or off, or affinity mask of ovs-vswitchd changing. Another colleague, Eelco Chaudron took a deep dive into the world of revalidator threads.
Last updated: July 21, 2023