This is the second article in a three-part series about designing a microservices-oriented application (MOA) and how to adopt microservices in your organization.
Check out these informative articles in the series:
Now we'll talk about implementing microservices.
To determine how you can use microservices in your organization, it is worth looking at how the architectural style came about and how a monolith tends to evolve into an MOA. You can use this historical overview as a guide for designing an MOA. So let's start by taking a short walk down IT's memory lane.
The roots of microservices-oriented application design
Take a look at Figure 1, which illustrates a typical monolithic application. Notice that everything the application needs is within the boundary of the application. In the early days of computing, the boundary of the application was a physical computer.
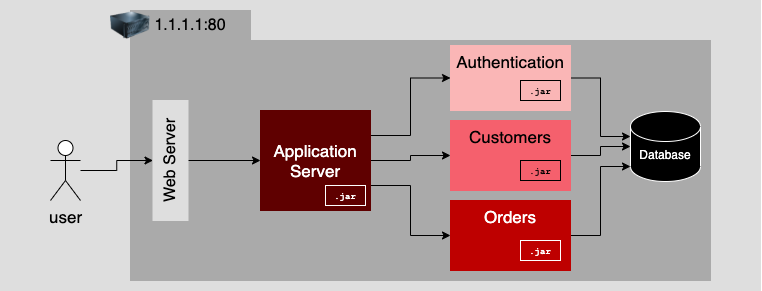
Over time, as more applications appeared on x86 machines, the database became a resource hog, eating up all the memory and compute capacity of the host machine. So architects moved the monolith's data storage mechanisms to a separate machine private to the network, as shown in Figure 2. (For what it's worth, mainframes didn't have this problem and still don't. Their drawback is that they are very expensive.)
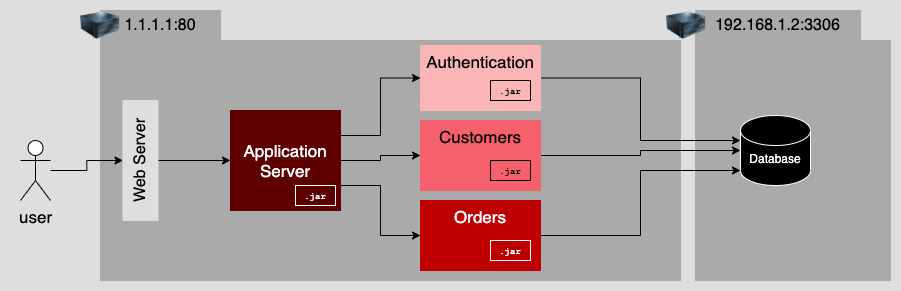
However, over time, just moving the database to its own machine wasn't enough. Similarly, the database was exhausting the host x86 machine, and the application logic started to push the limits of the host's computing capacity. So architects implemented a multiple instance design in which many computers hosting identical business logic were put behind a load balancer. The load balancer routed traffic optimally so as not to overpower any one machine with each computer hosting business logic stored data on a central database (Figure 3).

Replicating identical business logic across many machines had its benefits, but it also created a big problem for maintenance and upgrades. Even when everything an application needs to operate is on the same machine, as with a simple monolithic application, adding a new feature to the business logic or changing the data schema in the database is a significant chore. Yet, as difficult as an upgrade might be, it can be accommodated during an overnight maintenance window. Making a change to an application running in a replicated architecture is an entirely different undertaking, one that has all the makings of a nightmare.
Refer back to Figure 3. See all those components and all the connections those components have to the database? When it's time to implement an update to the Orders component, for example, not only does the Orders component on each machine need to be updated safely but the database might need to be changed too. This means that the entire application needs to be taken offline, updated, tested, and then, if everything goes well, be brought back online. If the business prohibits the application from going offline, the upgrade will require an enormously complex, time-consuming juggling act that could go wrong at any time.
So it turns out that replicating the monolithic application is not the solution to scaling that developers had hoped for. That is why they finally turned to microservices.
Creating a microservices-oriented application
A microservices-oriented application (MOA) addresses the shortcomings inherent in the monolithic application design. As described earlier, monolithic applications are hard to maintain and upgrade. Due to the tight coupling implicit in a monolithic application's construction, even making a small change can create unforeseen problems that can cascade throughout the application stack.
On the other hand, MOAs are loosely coupled, some say to an extreme.
According to the previous article in this series, 5 design principles for microservices, a microservice is an entirely independent unit of computing. It has a distinct presence on the network and carries its own data. It's completely and independently responsible for its own well-being. This means that as long as changes in its public interface do not affect current consumers of the service, an MOA can be changed independently of any other microservice in the MOA.
Figure 4 illustrates an MOA that is a transformation of the monolithic application described previously. Notice that each microservice has its own IP address and port assignment. Also, notice that there is no database in the illustration. This is because, as dictated by the five principles mentioned earlier, each microservice carries its own data. How that data is carried is the concern of the particular microservice. Thus, there is no need to show the database. The only relevant public information is the communication protocol that the microservice supports and the location of the service on the network. The location is defined by its IP address and port number.
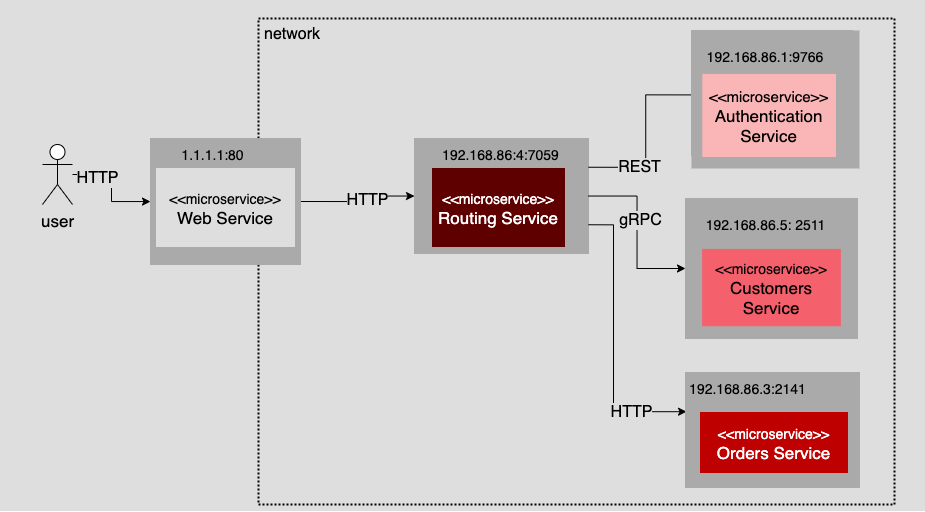
Of course, some mechanism needs to be in place to describe the public interface to the given microservice. Documenting the public interface is the responsibility of the developers creating the microservice. If the microservice uses gRPC, the interface is usually described as a .proto file. If the interface is a REST service, the description might be an OpenAPI specification file written in YAML.
The important thing to understand about implementing a microservice is that a microservice has a distinct, independent presence on the network. No situation should arise where one microservice is tightly coupled to another microservice.
All scaling activity should be internal to the microservice and opaque to the consumer. For example, when a microservice is implemented as a Kubernetes service, those consuming the service should have no idea how many pods are powering it. That is the business of the microservice. Also, operational resiliency should be ensured by the team supporting the microservice. Remember for all intents and purposes, a microservice is a standalone product and should be treated as such, even in service-level agreements.
The benefit of an MOA is that each of its microservices can change at a moment's notice without creating general havoc in the entire application. This safety requires all the microservices to be independent. Any sort of tight coupling defeats the purpose of an MOA.
Conclusion
Hopefully, this article helps you design a robust MOA. However, you should be aware of the weaknesses of microservices and the new demands they make on people and resources—the topic of the next article in this series, The disadvantages vs. benefits of microservices.
Learn more about microservices on Red Hat Developer
Check out the following resources for more tips about building and deploying microservices:
- Download chapters from the upcoming e-book Kubernetes Native Microservices with Quarkus and MicroProfile
- 5 design principles for microservices
- Application modernization patterns with Apache Kafka, Debezium, and Kubernetes
- Distributed transaction patterns for microservices compared
- An elegant way to performance test microservices on Kubernetes