As a consulting architect at Red Hat, I've had the privilege of working on legions of customer projects. Every customer brings their own challenges but I've found some commonalities. One thing most customers want to know is how to coordinate writes to more than one system of record. Answering this question typically involves a long explanation of dual writes, distributed transactions, modern alternatives, and the possible failure scenarios and drawbacks of each approach. Typically, this is the moment when a customer realizes that splitting a monolithic application into microservices is a long and complicated journey, and usually requires tradeoffs.
Rather than go down the rabbit hole of discussing transactions in-depth, this article summarizes the main approaches and patterns for coordinating writes to multiple resources. I’m aware that you might have good or bad past experiences with one or more of these approaches. But in practice, in the right context and with the right constraints, all of these methods work fine. Tech leads are responsible for choosing the best approach for their context.
Note: If you are interested in dual writes, watch my Red Hat Summit 2021 session, where I covered dual write challenges in depth. You can also skim through the slides from my presentation. Currently, I am involved with Red Hat OpenShift Streams for Apache Kafka, a fully managed Apache Kafka service. It takes less than a minute to start and is completely free during the trial period. Give it a try and help us shape it with your early feedback. If you have questions or comments about this article, hit me on Twitter @bibryam and let’s get started.
The dual write problem
The single indicator that you may have a dual write problem is the need to write to more than one system of record predictably. This requirement might not be obvious and it can express itself in different ways in the distributed systems design process. For example:
- You have chosen the best tools for each job and now you have to update a NoSQL database, a search index, and a cache as part of a single business transaction.
- The service you have designed has to update its database and also send a notification to another service about the change.
- You have business transactions that span multiple services boundaries.
- You may have to implement service operations as idempotent because consumers have to retry failed invocations.
For this article, we'll use a single example scenario to evaluate the various approaches to handling dual writes in distributed transactions. Our scenario is a client application that invokes a microservice on a mutating operation. Service A has to update its database, but it also has to call Service B on a write operation, as illustrated in Figure 1. The actual type of the database, the protocol of the service-to-service interactions, is irrelevant for our discussion as the problem remains the same.

A small but critical clarification explains why there are no simple solutions to this problem. If Service A writes to its database and then sends a notification to a queue for Service B (let’s call it a local-commit-then-publish approach), there is still a chance the application won't work reliably. While Service A writes to its database and then sends the message to a queue, there is a small probability of the application crashing after the commit to the database and before the second operation, which would leave the system in an inconsistent state. If the message is sent before writing to the database (let’s call this approach publish-then-local-commit), there is a possibility of database write failing or timing issues where Service B receives the event before Service A has committed the change to its database. In either case, this scenario involves dual writes to a database and a queue, which is the core problem we are going to explore. In the next sections, I will discuss the various implementation approaches available today for this always-present challenge.
The modular monolith
Developing your application as a modular monolith might seem like a hack or going backward in architectural evolution, but I have seen it work fine in practice. It is not a microservices pattern but an exception to the microservices rule that can be combined cautiously with microservices. When strong write consistency is the driving requirement, more important even than the ability to deploy and scale microservices independently, then you could go with the modular monolith architecture.
Having a monolithic architecture does not imply that the system is poorly designed or bad. It does not say anything about quality. As the name suggests, it is a system designed in a modular way with exactly one deployment unit. Note that this is a purposefully designed and implemented modular monolith, which is different from an accidentally created monolith that grows over time. In a purposeful modular monolith architecture, every module follows the microservices principles. Each module encapsulates all the access to its data, but the operations are exposed and consumed as in-memory method calls.
The architecture of a modular monolith
With this approach, you have to convert both microservices (Service A and Service B) into library modules that can be deployed into a shared runtime. You then make both microservices share the same database instance. Because the services are written and deployed as libraries in a common runtime, they can participate in the same transactions. Because the modules share a database instance, you can use a local transaction to commit or rollback all changes at once. There are also differences around the deployment method because we want the modules to be deployed as libraries within a bigger deployment, and to participate in existing transactions.
Even in a monolithic architecture, there are ways to isolate the code and data. For example, you can segregate the modules into separate packages, build modules, and source code repositories, which can be owned by different teams. You can do partial data isolation by grouping tables by naming convention, schemas, database instances, or even by database servers. The diagram in Figure 2, inspired by Axel Fontaine's talk on majestic modular monoliths, illustrates the different code- and data-isolation levels in applications.
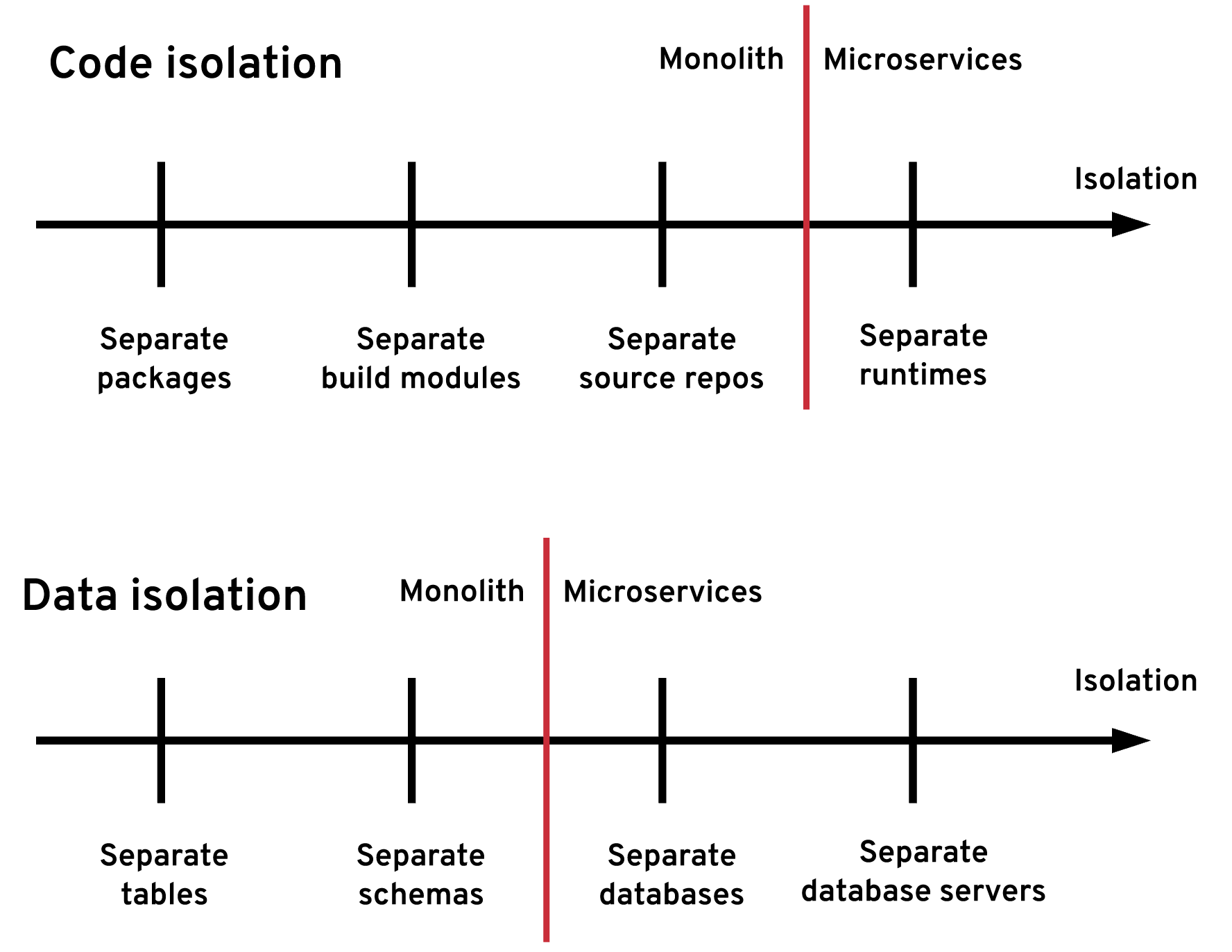
The last piece of the puzzle is to use a runtime and a wrapper service capable of consuming other modules and including them in the context of an existing transaction. All of these constraints make the modules more tightly coupled than typical microservices, but the benefit is that the wrapper service can start a transaction, invoke the library modules to update their databases, and commit or roll back the transaction as one operation, without concerns about partial failure or eventual consistency.
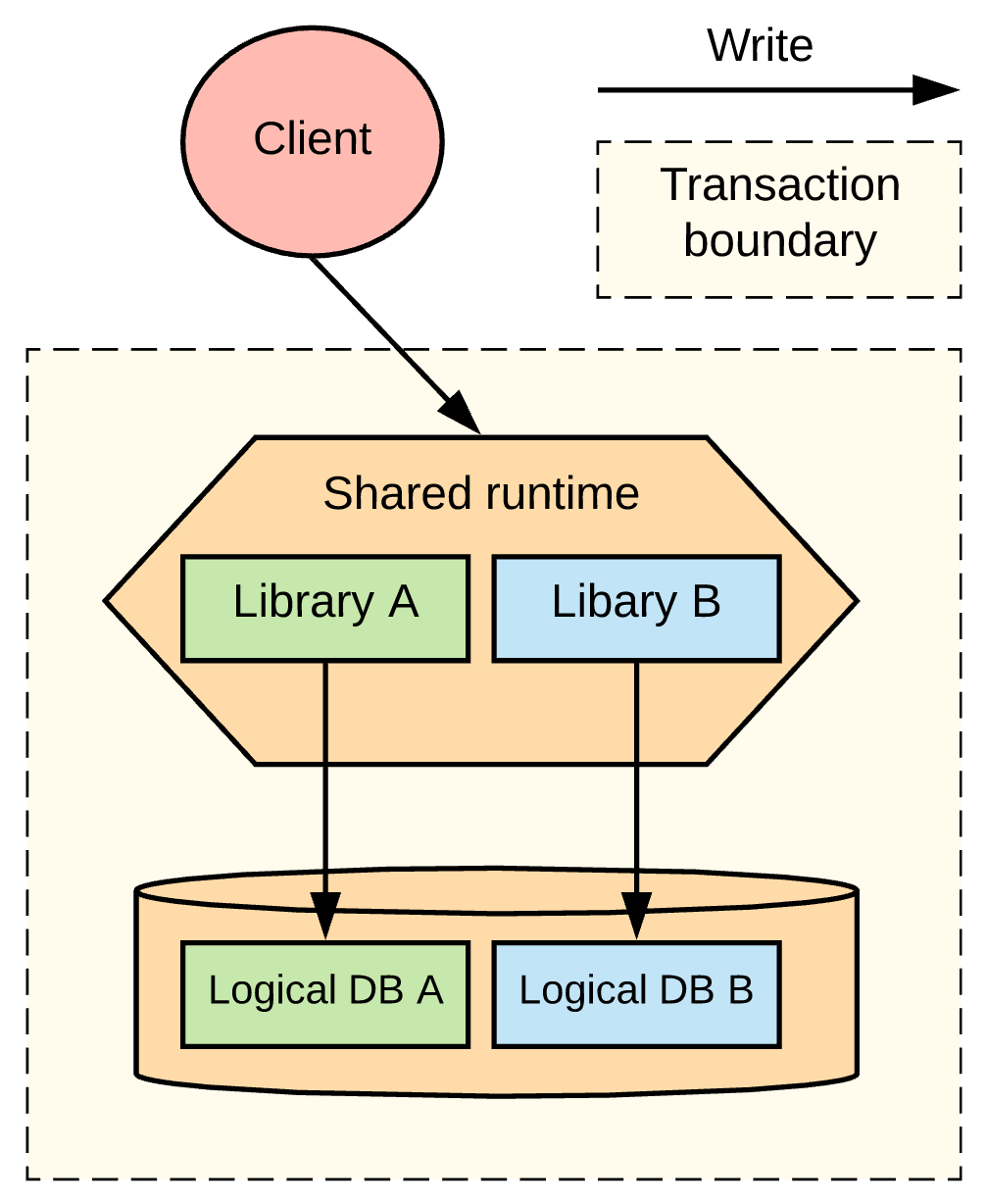
In our example, illustrated in Figure 3, we have converted Service A and Service B into libraries and deployed them into a shared runtime, or one of the services could act as the shared runtime. The tables from the databases also share a single database instance, but it is separated as a group of tables managed by the respective library services.
Benefits and drawbacks of the modular monolith
In some industries, it turns out the benefits of this architecture are far more important than the faster delivery and pace of change that are so highly valued at other places. Table 1 summarizes the benefits and drawbacks of the modular monolith architecture.
| Benefits | Simple transaction semantics with local transactions ensuring data consistency, read-your-writes, rollbacks, and so on. |
| Drawbacks |
|
| Examples |
|
Distributed transactions are typically the last resort, used in a variety of instances:
- When writes to disparate resources cannot be eventually consistent.
- When we have to write to heterogeneous data sources.
- When exactly-once message processing is required and we cannot refactor a system and make its operations idempotent.
- When integrating with third-party black-box systems or legacy systems that implement the two-phase commit specification.
In all of these situations, when scalability is not a concern, we might consider distributed transactions an option.
Implementing the two-phase commit architecture
The technical requirements for two-phase commit are that you need a distributed transaction manager such as Narayana and a reliable storage layer for the transaction logs. You also need DTP XA-compatible data sources with associated XA drivers that are capable of participating in distributed transactions, such as RDBMS, message brokers, and caches. If you are lucky to have the right data sources but run in a dynamic environment, such as Kubernetes, you also need an operator-like mechanism to ensure there is only a single instance of the distributed transaction manager. The transaction manager must be highly available and must always have access to the transaction log.
For implementation, you could explore a Snowdrop Recovery Controller that uses the Kubernetes StatefulSet pattern for singleton purposes and persistent volumes to store transaction logs. In this category, I also include specifications such as Web Services Atomic Transaction (WS-AtomicTransaction) for SOAP web services. What all of these technologies have in common is that they implement the XA specification and have a central transaction coordinator.
In our example, shown in Figure 4, Service A is using distributed transactions to commit all changes to its database and a message to a queue without leaving any chance for duplicates or lost messages. Similarly, Service B can use distributed transactions to consume the messages and commit to Database B in a single transaction without any duplicates. Or, Service B can choose not to use distributed transactions, but use local transactions and implement the idempotent consumer pattern. For the record, a more appropriate example for this section would be using WS-AtomicTransaction to coordinate the writes to Database A and Database A in a single transaction and avoid eventual consistency altogether. But that approach is even less common, these days, than what I've described.
Benefits and drawbacks of the two-phase commit architecture
The two-phase commit protocol offers similar guarantees to local transactions in the modular monolith approach, but with a few exceptions. Because there are two or more separate data sources involved in an atomic update, they may fail in a different manner and block the transaction. But thanks to its central coordinator, it is still easy to discover the state of the distributed system compared to the other approaches I will discuss.
Table 2 summarizes the benefits and drawbacks of this approach.
| Benefits |
|
| Drawbacks |
|
| Examples |
|
Orchestration
With a modular monolith, we use local transactions and we always know the state of the system. With distributed transactions based on the two-phase commit protocol, we also guarantee a consistent state. The only exception would be an unrecoverable failure that involved the transaction coordinator. But what if we wanted to ease the consistency requirements while still knowing the state of the overall distributed system and coordinating from a single place? In this case, we might consider an orchestration approach, where one of the services acts as the coordinator and orchestrator of the overall distributed state change. The orchestrator service has the responsibility to call other services until they reach the desired state or take corrective actions if they fail. The orchestrator uses its local database to keep track of state changes, and it is responsible for recovering any failures related to state changes.
Implementing an orchestration architecture
The most popular implementations of the orchestration technique are BPMN specification implementations such as the jBPM and Camunda projects. The need for such systems doesn’t disappear with overly distributed architectures such as microservices or serverless; on the contrary, it increases. For proof, we can look to newer stateful orchestration engines that do not follow a specification but provide similar stateful behavior, such as Netflix’s Conductor, Uber’s Cadence, and Apache's Airflow. Serverless stateful functions such as Amazon StepFunctions, Azure Durable Functions, and Azure Logic Apps are in this category, as well. There are also open source libraries that allow you to implement stateful coordination and rollback behavior such as Apache Camel’s Saga pattern implementation and the NServiceBus Saga capability. The many homegrown systems implementing the Saga pattern are also in this category.

In our example diagram, shown in Figure 5, we have Service A acting as the stateful orchestrator responsible to call Service B and recover from failures through a compensating operation if needed. The crucial characteristic of this approach is that Service A and Service B have local transaction boundaries, but Service A has the knowledge and the responsibility to orchestrate the overall interaction flow. That is why its transaction boundary touches Service B endpoints. In terms of implementation, we could set this up with synchronous interactions, as shown in the diagram, or using a message queue in between the services (in which case you could use a two-phase commit, too).
Benefits and drawbacks of orchestration
Orchestration is an eventually consistent approach that may involve retries and rollbacks to get the distribution into a consistent state. While it avoids the need for distributed transactions, orchestration requires the participating services to offer idempotent operations in case the coordinator has to retry an operation. Participating services also must offer recovery endpoints in case the coordinator decides to roll back and fix the global state. The big advantage of this approach is the ability to drive heterogeneous services that might not support distributed transactions into a consistent state by using only local transactions. The coordinator and the participating services need only local transactions, and it is always possible to discover the state of the system by asking the coordinator, even if it is in a partially consistent state. Doing that is not possible with the other approaches I will describe.
| Benefits |
|
| Drawbacks |
|
| Examples |
|
Choreography
As you've seen in the discussion so far, a single business operation can result in multiple calls among services, and it can take an indeterminate amount of time before a business transaction is processed end-to-end. To manage this, the orchestration pattern uses a centralized controller service that tells the participants what to do.
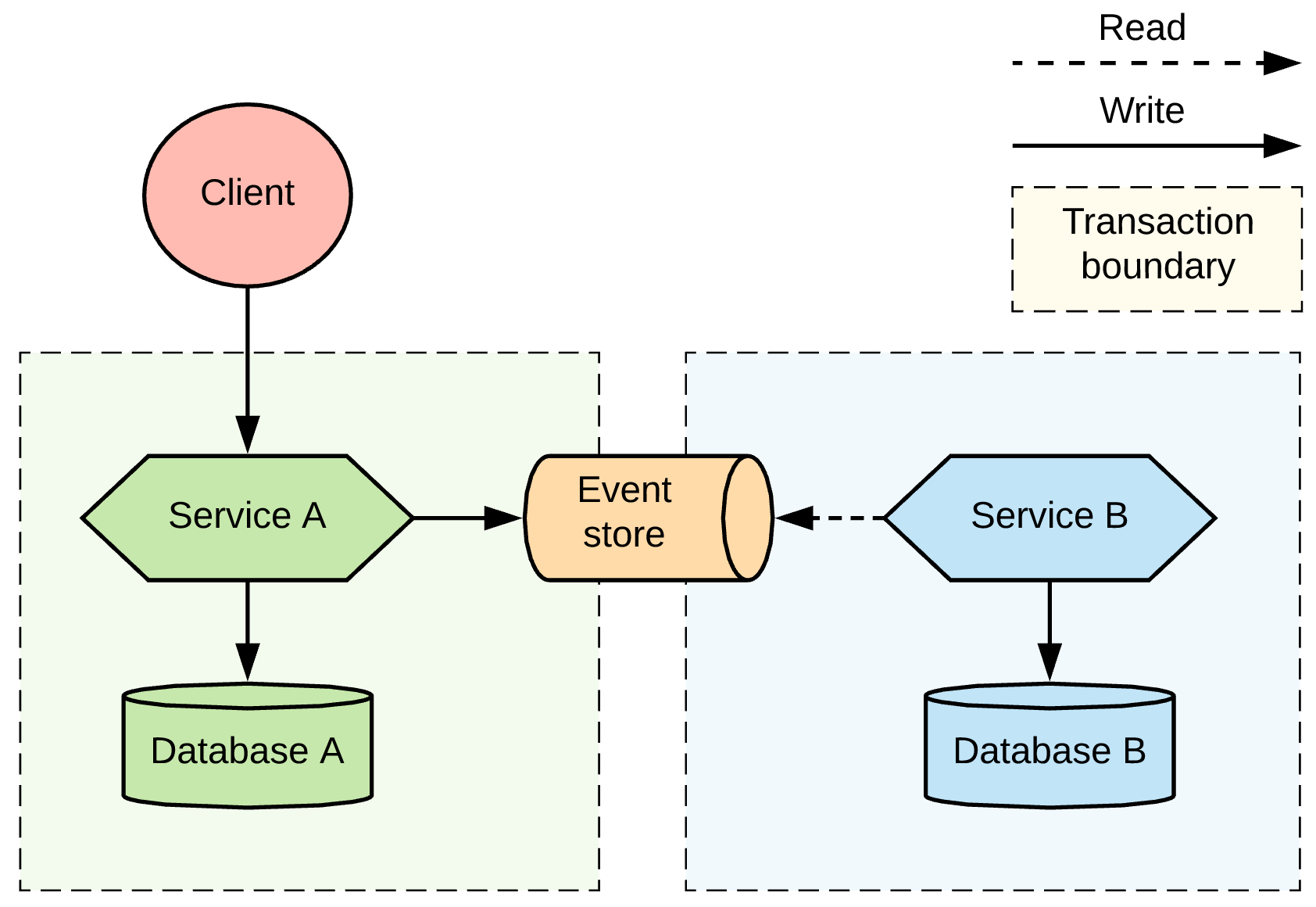
An alternative to orchestration is choreography, which is a style of service coordination where participants exchange events without a centralized point of control. With this pattern, each service performs a local transaction and publishes events that trigger local transactions in other services. Each component of the system participates in decision-making about a business transaction's workflow, instead of relying on a central point of control. Historically, the most common implementation for the choreography approach was using an asynchronous messaging layer for the service interactions. Figure 6 illustrates the basic architecture of the choreography pattern.
Choreography with a dual write
For message-based choreography to work, we need each participating service to execute a local transaction and trigger the next service by publishing a command or event to a messaging infrastructure. Similarly, other participating services have to consume a message and perform a local transaction. That in itself is a dual-write problem within a higher-level dual-write problem. When we develop a messaging layer with a dual write to implement the choreography approach, we could design it as a two-phase commit that spans a local database and a message broker. I covered that approach earlier. Alternatively, we might use a publish-then-local-commit or local-commit-then-publish pattern:
- Publish-then-local-commit: We could try to publish a message first and then commit a local transaction. While this option might sound fine, it has practical challenges. For example, very often you need to publish an ID that is generated from the local transaction commit, which won’t be available to publish. Also, the local transaction might fail, but we cannot rollback the published message. This approach lacks read-your-write semantics and it is an impractical solution for most use cases.
- Local-commit-then-publish: A slightly better approach would be to commit the local transaction first and then publish the message. This has a small probability of failure occurring after a local transaction has been committed and before publishing the message. But even in that case, you could design your services to be idempotent and retry the operation. That would mean committing the local transaction again and then publishing the message. This approach can work if you control the downstream consumers and can make them idempotent, too. It's also a pretty good implementation option overall.
Choreography without a dual write
The various ways of implementing a choreography architecture constrain every service to write only to a single data source with a local transaction, and nowhere else. Let’s see how that could work without a dual write.
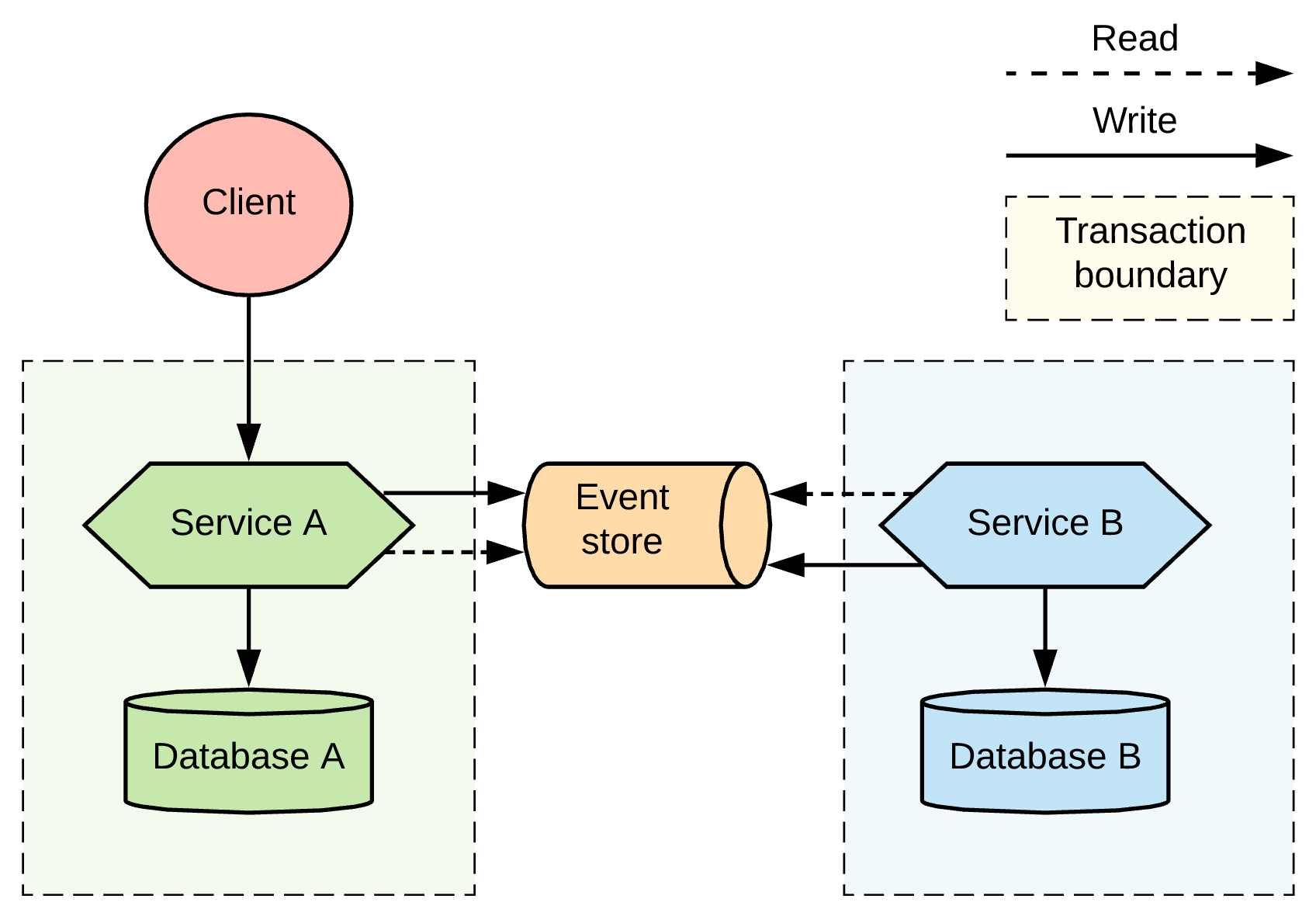
Let’s say Service A receives a request and writes it to Database A, and nowhere else. Service B periodically polls Service A and detects new changes. When it reads the change, Service B updates its own database with the change and also the index or timestamp up to which it picked up the changes. The critical part here is the fact that both services only write to their own database and commit with a local transaction. This approach, illustrated in Figure 7, can be described as service choreography, or we could describe it using the good old data pipeline terminology. The possible implementation options are more interesting.

The simplest scenario is for Service B to connect to the Service A database and read the tables owned by Service A. The industry tries to avoid that level of coupling with shared tables, however, and for a good reason: Any change in Service A's implementation and data model could break Service B. We can make a few gradual improvements to this scenario, for example by using the Outbox pattern and giving Service A a table that acts as a public interface. This table could only contain the data Service B requires, and it could be designed to be easy to query and track for changes. If that is not good enough, a further improvement would be for Service B to ask Service A for any changes through an API management layer rather than connecting directly to Database A.
Fundamentally, all of these variations suffer from the same drawback: Service B has to poll Service A continuously. Doing this can lead to unnecessary continuous load on the system or unnecessary delay in picking up the changes. Polling a microservice for changes is a hard sell, so let’s see what we can do to further improve this architecture.
Choreography with Debezium
One way to improve a choreography architecture and make it more attractive is to introduce a tool like Debezium, which we can use to perform change data capture (CDC) using Database A’s transaction log. Figure 8 illustrates this approach.
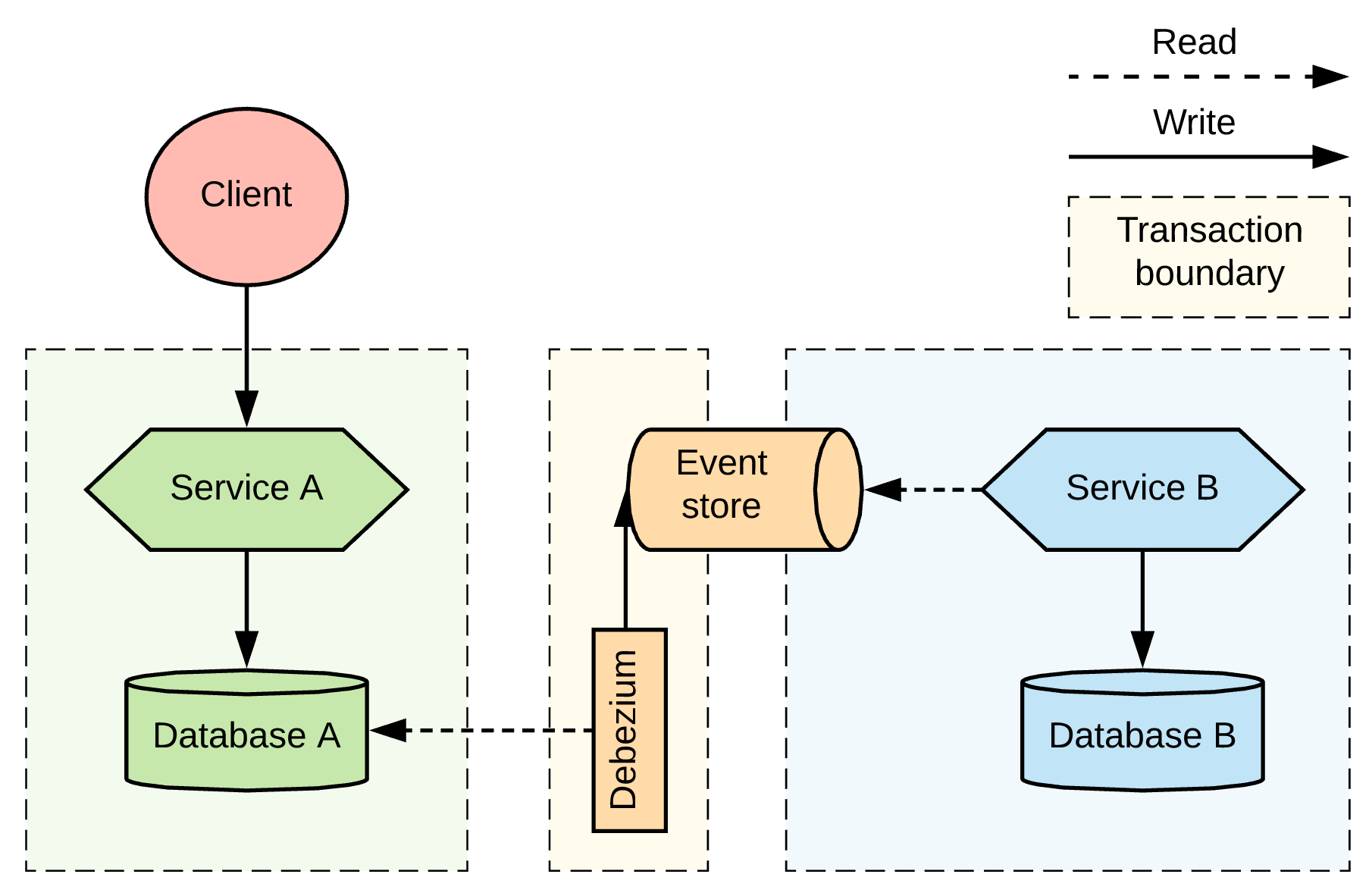
Debezium can monitor a database's transaction log, perform any necessary filtering and transformation, and deliver relevant changes into an Apache Kafka topic. This way, Service B can listen to generic events in a topic rather than polling Service A's database or APIs. Swapping database polling for streaming changes and introducing a queue between the services makes the distributed system more reliable, scalable, and opens up the possibility of introducing other consumers for new use cases. Using Debezium offers an elegant way to implement the Outbox pattern for orchestration- or choreography-based Saga pattern implementations.
A side-effect of this approach is that it introduces the possibility of Service B receiving duplicate messages. This can be addressed by implementing the service as idempotent, either at the business logic level or with a technical deduplicator (with something like Apache ActiveMQ Artemis’s duplicate message detection or Apache Camel's idempotent consumer pattern).
Choreography with event sourcing
Event sourcing is another implementation of the service choreography approach. With this pattern, the state of an entity is stored as a sequence of state-changing events. When there is a new update, rather than updating the entity's state, a new event is appended to the list of events. Appending new events to an event store is an atomic operation done in a local transaction. The beauty of this approach, shown in Figure 9, is that the event store also behaves like a message queue for other services to consume updates.
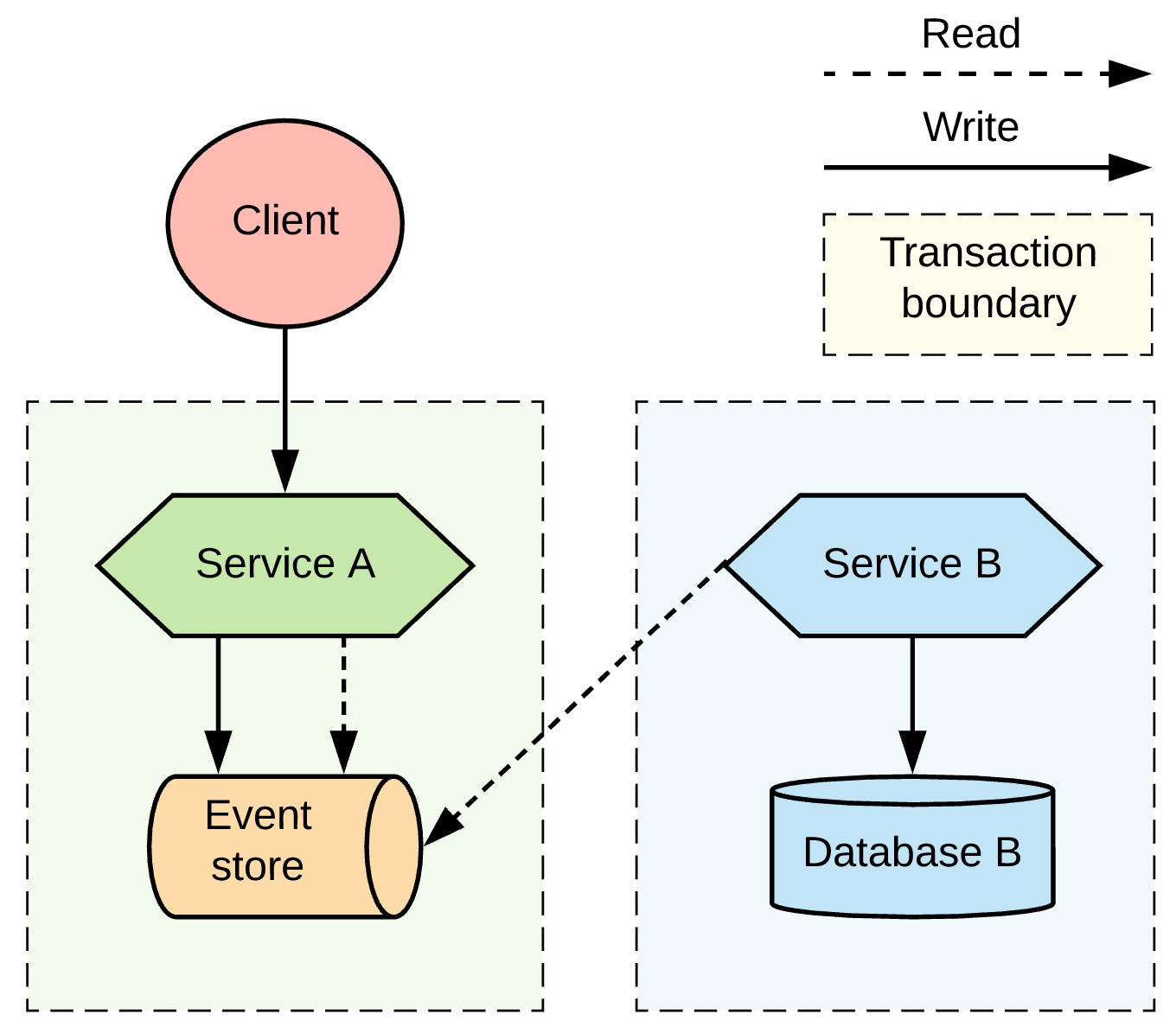
Our example, when converted to use event sourcing, would store client requests in an append-only event store. Service A can reconstruct its current state by replaying the events. The event store also needs to allow Service B to subscribe to the same update events. With this mechanism, Service A uses its storage layer also as the communication layer with other services. While this mechanism is very neat and solves the problem of reliably publishing events whenever the state change occurs, it introduces a new programming style unfamiliar to many developers and additional complexity around state reconstruction and message compaction, which require specialized data stores.
Benefits and drawbacks of choreography
Regardless of the mechanism used to retrieve data changes, the choreography approach decouples writes, allows independent service scalability, and improves overall system resiliency. The downside of this approach is that the flow of decision-making is decentralized and it is hard to discover the globally distributed state. Discovering the state of a request requires querying multiple data sources which can be challenging with a large number of services. Table 4 summarizes the benefits and drawbacks of this approach.
| Benefits |
|
| Drawbacks |
|
| Examples |
|
Parallel pipelines
With the choreography pattern, there is no central place to query the state of the system, but there is a sequence of services that propagates the state through the distributed system. Choreography creates a sequential pipeline of processing services, so we know that when a message reaches a certain step of the overall process, it has passed all the previous steps. What if we could loosen this constraint and process all the steps independently? In this scenario, Service B could process a request regardless of whether Service A had processed it or not.
With parallel pipelines, we add a router service that accepts requests and forwards them to Service A and Service B through a message broker in a single local transaction. From this step onward, as shown in Figure 10, both services can process the requests independently and in parallel.
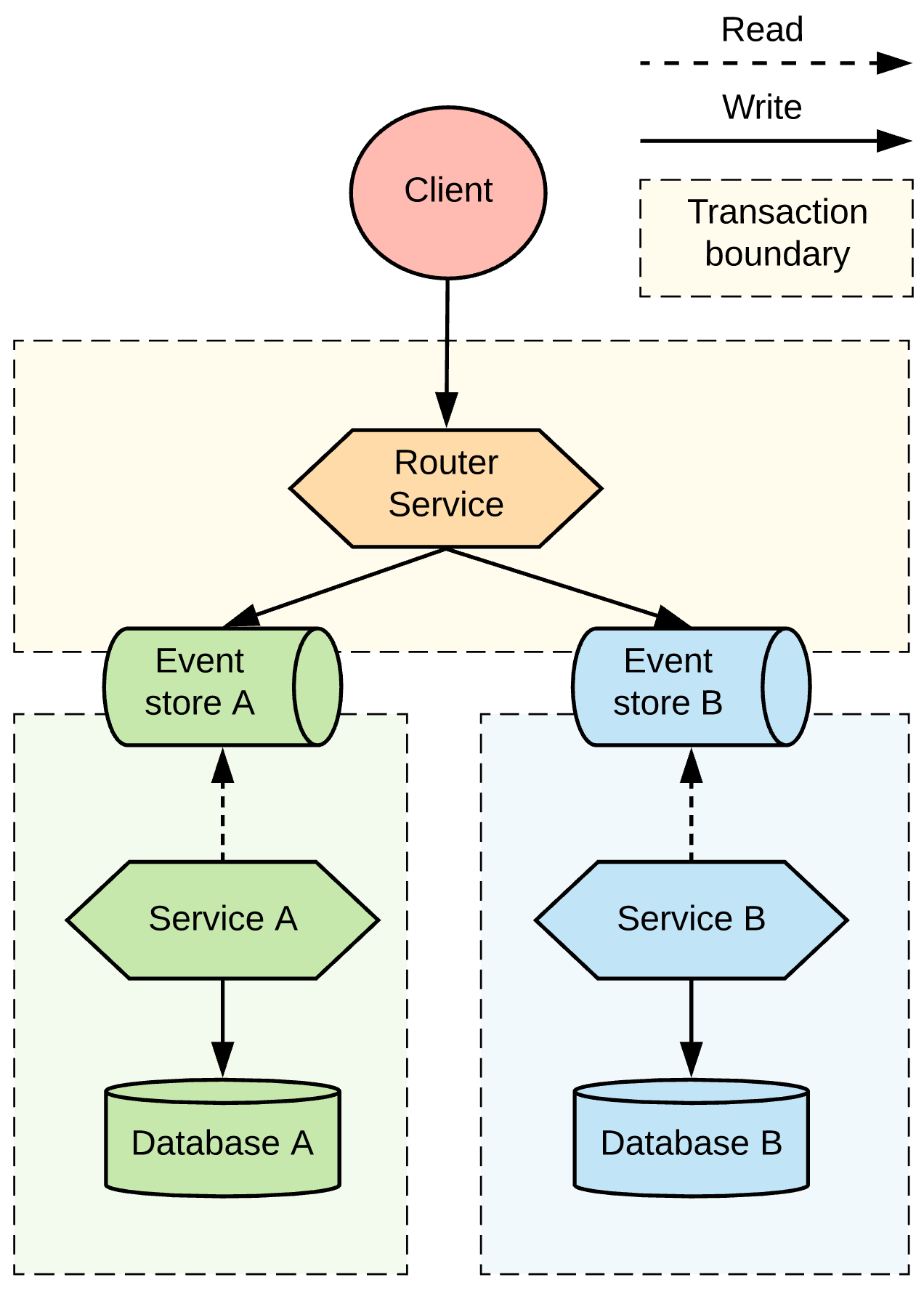
While this pattern is very simple to implement, it is only applicable to situations where there is no temporal binding between the services. For example, Service B should be able to process the request regardless of whether Service A has processed the same request. Also, this approach requires an additional router service or the client being aware of both Service A and B for targeting the messages.
Listen to yourself
There is a lighter alternative to this approach, known as the Listen to yourself pattern, where one of the services also acts as the router. With this alternative approach, when Service A receives a request, it would not write to its database but would instead publish the request into the messaging system, where it is targeted to Service B, and to itself. Figure 11 illustrates this pattern.
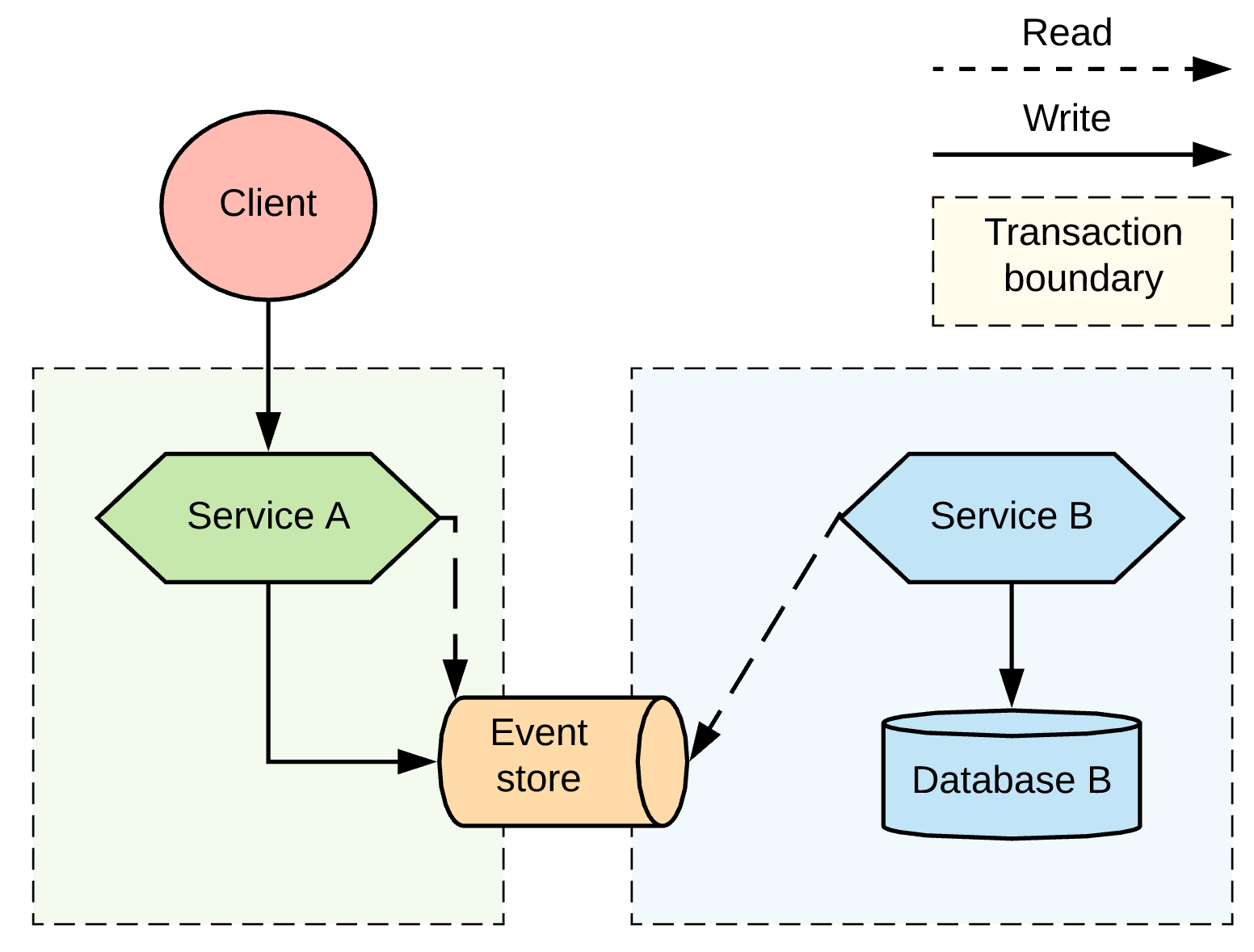
The reason for not writing to the database is to avoid dual writes. Once a message is in the messaging system, the message goes to Service B, and also it goes to back Service A in a completely separate transaction context. With that twist of the processing flow, Service A, and Service B can independently process the request and write to their respective databases.
Benefits and drawbacks of parallel pipelines
Table 5 summarizes the benefits and drawbacks of using parallel pipelines.
| Benefits | Simple, scalable architecture for parallel processing. |
| Drawbacks | Requires temporal dismantling; hard to reason about the global system state. |
| Examples | Apache Camel’s multicast and splitter with parallel processing. |
How to choose a distributed transactions strategy
As you might have already guessed from this article, there is no right or wrong pattern for handling distributed transactions in a microservices architecture. Every pattern has its pros and cons. Each pattern solves some problems while generating others in turn. The chart in Figure 12 offers a short summary of the main characteristics of the dual write patterns I've discussed.

Whatever approach you choose, you will need to explain and document the motivation behind the decision and the long-lasting architectural consequences of your choice. You will also need to get support from the teams that will implement and maintain the system in the long term. I like to organize and evaluate the approaches described in this article based on their data consistency and scalability attributes, as shown in Figure 13.

As a good starting point, we could evaluate the various approaches from the most scalable and highly available to the least scalable and available ones.
High: Parallel pipelines and choreography
If your steps are temporarily decoupled, then it could make sense to run them in a parallel pipelines method. The chances are you can apply this pattern for certain parts of the system, but not for all of them. Next, assuming there is a temporal coupling between the processing steps, and certain operations and services have to happen before others, you might consider the choreography approach. Using service choreography, it is possible to create a scalable, event-driven architecture where messages flow from service to service through a decentralized orchestration process. In this case, Outbox pattern implementations with Debezium and Apache Kafka (such as Red Hat OpenShift Streams for Apache Kafka) are particularly interesting and gaining traction.
Medium: Orchestration and two-phase commit
If choreography is not a good fit, and you need a central point that is responsible for coordination and decision making, then you would consider orchestration. This is a popular architecture, with standard-based and custom open source implementations available. While a standard-based implementation may force you to use certain transaction semantics, a custom orchestration implementation allows you to make a trade-off between the desired data consistency and scalability.
Low: Modular monolith
If you are going further left in the spectrum, most likely you have a very strong need for data consistency and you are ready to pay for it with significant tradeoffs. In this case, distributed transactions through two-phase commits will work with certain data sources, but they are difficult to implement reliably on dynamic cloud environments designed for scalability and high availability. In that case, you can go all the way to the good old modular monolith approach, accompanied by practices learned from the microservices movement. This approach ensures the highest data consistency but at the price of runtime and data source coupling.
Conclusion
In a sizable distributed system with tens of services, there won’t be a single approach that works for all, but a few of these combined and applied for different contexts. You might have a few services deployed on a shared runtime for exceptional requirements around data consistency. You might choose a two-phase commit for integration with a legacy system that supports JTA. You might orchestrate a complex business process, and also use choreography and parallel processing for the rest of the services. In the end, it doesn't matter what strategy you pick; what matters is choosing a strategy deliberately for the right reasons, and executing it.
Last updated: October 18, 2023