Red Hat Data Grid, built on the Infinispan community project, has been a key component of the Red Hat Summit keynote demonstration for several years, and the first part of our virtual summit in April 2021 was no exception. This year, we built an online Battleship game that was deployed across three continents and hosted on Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure. If you missed the live action with Burr Sutter, you can catch the video replay on YouTube.
In this article, we’re going to take a closer look at Data Grid's role in the demonstration, explain the architecture, and break down some of the technical details behind what Burr calls “that Data Grid magic.”
Note: Visit Red Hat Summit 2021 for information and a schedule for the second part of this year's virtual summit, coming June 15 to June 16.
Leaderboard: Determining the global winners
Let’s start with the use case for the live demonstration. The purpose of the leaderboard is to track scores in real time and then calculate a global ranking of all the players. Figure 1 shows the user interface for the Battleship game.
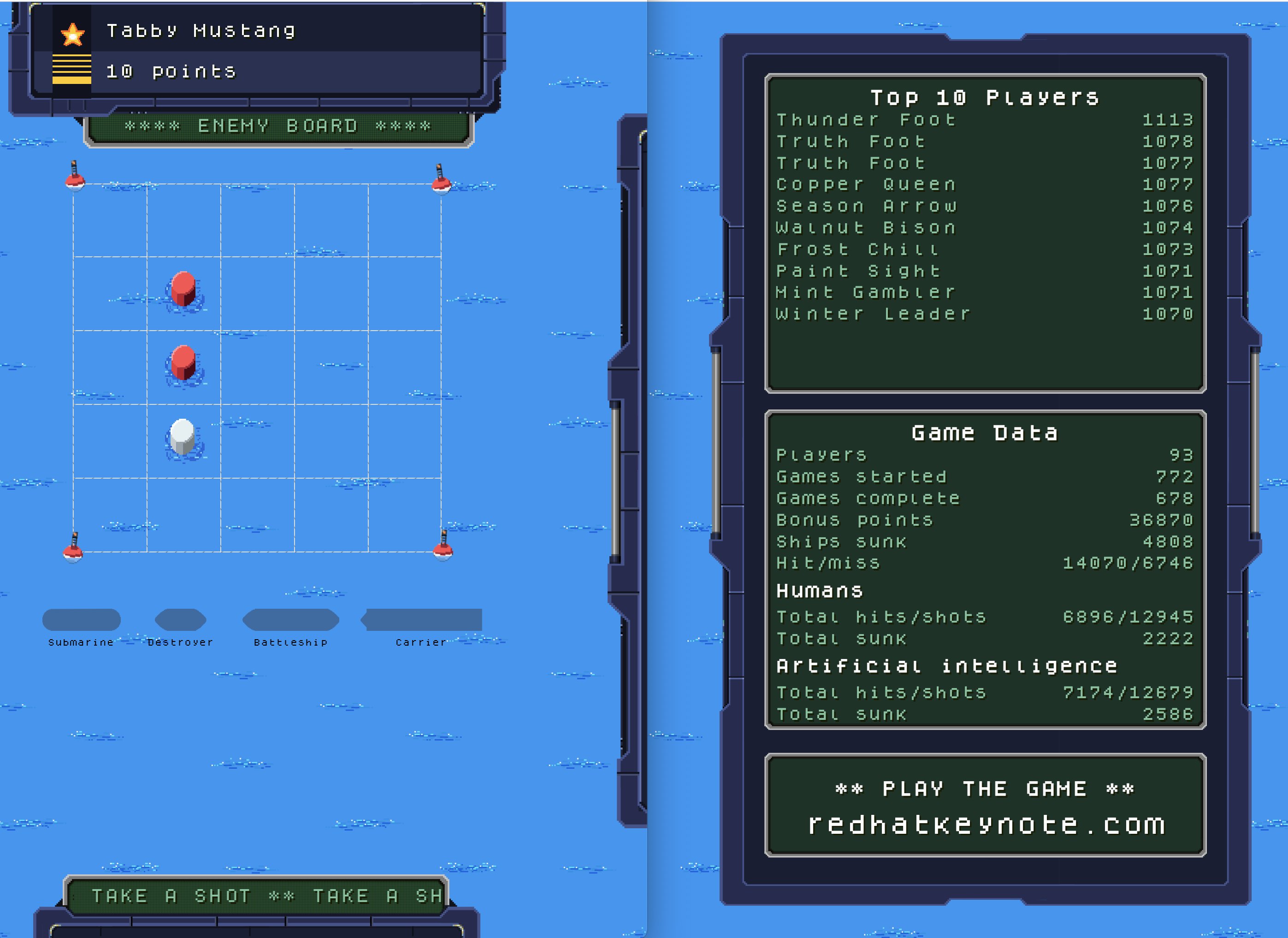
The game application and all related services were hosted on three cloud providers in different geographical regions. We used Knative Eventing (CloudEvents) functions built with Quarkus Funqy, along with a few other amazing components, to track each player's points in every match. For everything to work together, Data Grid stored all the game data (players, current game, matches being played, and so on) at each site.
However, the leaderboard represents a global ranking of players, so we needed all the player scores across each cluster to determine the overall winners.
The leaderboard's architecture
Each of the three data centers hosted a Data Grid cluster alongside a scoring service and a leaderboard service, as shown in Figure 2.

Let's take a closer look at the scoring service and leaderboard service.
The scoring service
During each match, players battled it out, trying to sink each other’s ships and score points. A separate service used Cloud Functions to calculate points according to a defined business logic. But we needed a way to collect all those points and save them in our Data Grid cluster.
The scoring service was our solution. We implemented a REST API with Quarkus and the RestEasy extension. We then added the infinispan-client extension for Quarkus to establish a connection to our players-scores cache.
Putting all this together resulted in a service that adds an entry to the players-scores cache the first time the player scores a point. For any subsequent points, the scoring service updates the entry with the delta score.
Here is the ScoringService.java implementation:
@Path("/scoring")
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
@ApplicationScoped
public class ScoringResource {
@Inject
@Remote(PlayerScore.PLAYERS_SCORES)
RemoteCache<String, PlayerScore> playersScores;
@POST
@Path("/{gameId}/{matchId}/{userId}")
public Response score(@PathParam("gameId") String gameId,
@PathParam("matchId") String matchId,
@PathParam("userId") String userId,
@QueryParam("delta") int delta,
@QueryParam("human") boolean human,
@QueryParam("timestamp") long timestamp,
@QueryParam("bonus") Boolean bonus,
@QueryParam("username") String username) {
String key = getKey(gameId, matchId, userId);
PlayerScore playerScore = playersScores.get(key);
if(playerScore == null) {
playerScore = new PlayerScore(userId, matchId, gameId, username, human, delta, timestamp, GameStatus.PLAYING, 0);
} else {
playerScore.setScore(playerScore.getScore() + delta);
playerScore.setTimestamp(timestamp);
}
playersScores.put(key, playerScore);
return Response.accepted().build();
}
Cache configuration
Our Data Grid cluster has multiple nodes, so a distributed cache provides a good tradeoff between scalability and availability. The players-scores cache supports indexing with the org.redhat.PlayerScore entity and uses the application/x-protostream media type to encode caches.
Here's the cache configuration we used:
<distributed-cache name="player-scores" statistics="true" owners="2">
<encoding>
<key media-type="application/x-protostream" />
<value media-type="application/x-protostream" />
</encoding>
<indexing enabled="true">
<indexed-entities>
<indexed-entity>org.redhat.PlayerScore</indexed-entity>
</indexed-entities>
</indexing>
</distributed-cache>
PlayersScore.java
PlayerScore.java is the class we created to provide a data model. The most important attributes for our use case are score, timestamp, and whether the player is human or AI (artificial intelligence).
The infinispan-client extension uses the ProtoStream library to generate a .proto schema file and marshaller implementation from the minimal annotations in our class.
As shown in this snippet, the @ProtoField annotation determines which POJO (plain old Java object) fields are included in the schema. @ProtoFactory recreates an instance of the POJO during deserialization. The @ProtoDoc annotation adds indexing metadata:
package com.redhat.model;
import org.infinispan.protostream.annotations.ProtoDoc;
import org.infinispan.protostream.annotations.ProtoFactory;
import org.infinispan.protostream.annotations.ProtoField;
@ProtoDoc("@Indexed")
public class PlayerScore {
private String userId;
private String matchId;
private String gameId;
private String username;
private Boolean human;
private Integer score;
private Long timestamp;
@ProtoFactory
public PlayerScore(String userId, String matchId, String gameId, String username, Boolean human, Integer score, Long timestamp) {
this.userId = userId;
this.matchId = matchId;
this.gameId = gameId;
this.username = username;
this.human = human;
this.score = score;
this.timestamp = timestamp;
}
@ProtoField(number = 1)
public String getUserId() {
return userId;
}
@ProtoField(number = 2)
public String getMatchId() {
return matchId;
}
@ProtoField(number = 3)
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)")
public String getGameId() {
return gameId;
}
@ProtoField(number = 4)
public String getUsername() {
return username;
}
@ProtoField(number = 5)
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)")
public Boolean isHuman() {
return human;
}
@ProtoField(number = 6)
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)")
@ProtoDoc("@SortableField")
public Integer getScore() {
return score;
}
@ProtoField(number = 7)
@ProtoDoc("@Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)")
@ProtoDoc("@SortableField")
public Long getTimestamp() {
return timestamp;
}
}
Now, take a look at the generated schema in player-score.proto:
syntax = "proto2";
package com.redhat;
/**
* @Indexed
*/
message PlayerScore {
/**
* @Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)
*/
optional string userId = 1;
optional string matchId = 2;
/**
* @Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)
*/
optional string gameId = 3;
optional string username = 4;
/**
* @Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)
*/
optional bool human = 5;
/**
* @Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)
* @SortableField
*/
optional int32 score = 6;
/**
* @Field(index=Index.YES, analyze = Analyze.NO, store = Store.YES)
* @SortableField
*/
optional int64 timestamp = 7;
}
Note that the process to generate the Protobuf (Protocol Buffers) schema happens on the client side. We still needed to register the generated schema with our Data Grid cluster to marshal our entries correctly. Fortunately, that was very easy because the infinispan-client extension for Quarkus did the hard work.
The leaderboard service
Once the scoring service started tracking and updating scores in our players-scores cache, we needed to get the top 10 players in real time and display them on our leaderboard.
We created a full-text query with the Ickle query language to find the top 10 players at any given time. We used the following QueryFactory to order players by score and return a maximum of 10 results:
QueryFactory queryFactory = Search.getQueryFactory(playersScores);
Query topTenQuery = queryFactory
.create("from com.redhat.PlayerScore p WHERE p.human=true ORDER BY p.score DESC, p.timestamp ASC")
.maxResults(10);
List<PlayerScore> topTen = topTenQuery.execute().list();
Note: You can view the complete code in the scoring service and leaderboard service GitHub repositories.
To get continuous results in the correct order, we used the Quarkus Scheduler extension. We then needed to continuously push the top 10 players to the leaderboard, which we were able to do with the Quarkus Websockets extension:
@ServerEndpoint("/leaderboard")
@ApplicationScoped
public class LeaderboardEndpoint {
...
private Map<String, Session> sessions = new ConcurrentHashMap<>();
...
@OnOpen
public void onOpen(Session session) {
sessions.put(session.getId(), session);
LOGGER.info("Leaderboard service socket opened");
broadcast();
}
@Scheduled(every = "1s")
public void broadcast() {
if(sessions.isEmpty()) {
return;
}
List<PlayerScore> topTen = topTenQuery.execute().list()
sessions.values().forEach(s -> s.getAsyncRemote().sendObject(topTen.toString(), result -> {
if (result.getException() != null) {
LOGGER.error("Leaderboard service got interrupted", result.getException());
}
}));
}
@OnClose
public void onClose(Session session) {
sessions.remove(session.getId());
LOGGER.info("Leaderboard Service session has been closed");
}
@OnError
public void onError(Session session, Throwable throwable) {
sessions.remove(session.getId());
LOGGER.error("Leaderboard Service session error", throwable);
}
}
Configuring the global leaderboard across the hybrid cloud
Finally, after we had our services and Data Grid clusters set up in each region, we needed to calculate a global leaderboard of the top 10 players across Amazon Web Services, Google Cloud Platform, and Microsoft Azure.
For this, we used Data Grid's cross-site replication, as shown in Figure 3.
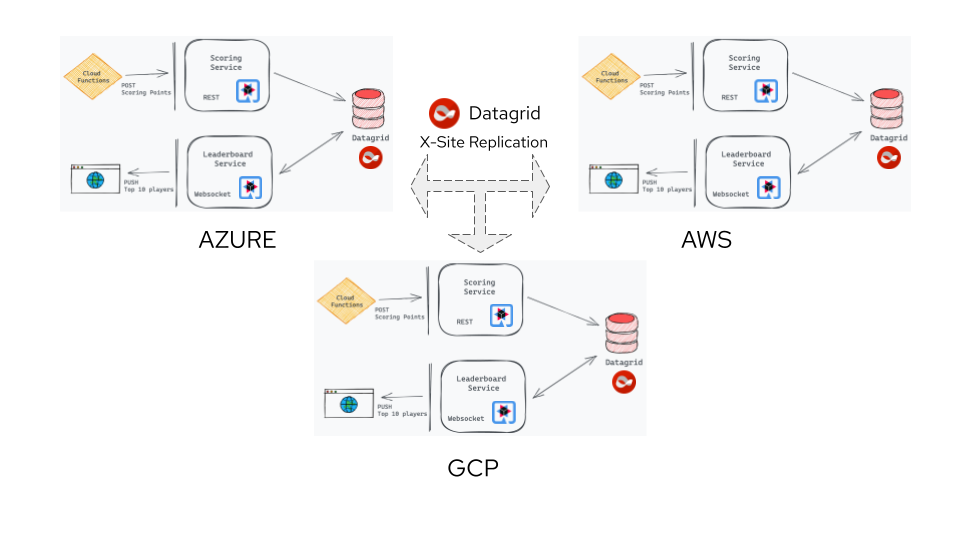
Cross-site replication
To make data available across all regions, we configured each players-score cache to asynchronously replicate data to the other Data Grid clusters. As players actively battled each other on all three data centers, the players-score cache received updates from all Data Grid clusters simultaneously.
Here is the cache configuration on Azure:
<distributed-cache name="players-score" ...>
<!-- index and encoding configuration. -->
<backups>
<backup site="AWS" strategy="ASYNC" enabled="true">
<take-offline min-wait="60000" after-failures="3" />
</backup>
<backup site="GCP" strategy="ASYNC" enabled="true">
<take-offline min-wait="60000" after-failures="3" />
</backup>
</backups>
</distributed-cache>
Conclusion
In this article, we’ve explained how we built a system with Data Grid and Quarkus extensions to create a global ranking of game players across a hybrid cloud deployment. See Building cloud-native applications with AI/ML for a recap of Burr Sutter's live demonstration at Red Hat Summit 2021 in April.
We hope the demonstration and this article inspire you to use Red Hat Data Grid or the Infinispan project for your own use cases.
Last updated: November 6, 2023