Introduction
Customers demand predictable and scalable performance from their virtualization platform. We will demonstrate how OpenShift Virtualization provides robust performance for demanding production workloads like databases. Many customers are seeking virtualization alternatives without sacrificing performance. You can run and manage these workloads at scale in VMs on OpenShift.
This study proves database throughput in VMs on OpenShift with “out-of-the-box” defaults approaches bare metal performance, without any tuning required.
We evaluated a common open source database which is packaged, shipped and supported by Red Hat Enterprise Linux, MariaDB. For other specific workload requirements, we recommend further tuning to optimize performance. More information is available in the OpenShift Virtualization Tuning & Scale Guide.
Testing Environment
Database throughput scaling is influenced by a combination of system performance, resource contention points, as well as any virtualization of the I/O path. When utilizing faster storage devices, such as local NVMe disks, we can focus more on pure virtualization performance, which is not limited by slower physical disk bottlenecks.
The following scaling examples were measured in the Red Hat performance lab using a Single Node OpenShift topology with out of the box defaults to measure throughput scalability. Exact throughput that can be achieved is highly dependent on the available system resources and the backing storage class performance. Instead of focusing on the specific throughput values achieved, these examples showcase VM performance in relation to the same workload running in a pod on OpenShift, representing the native baremetal system.
System Details
The system under test ran the full OpenShift 4.14 cluster components and is the host hypervisor for VMs. The hardware configured: 64 Xeon cores, 512 GB memory, 2 x 3 TB NVMe striped as a single LVMCluster. See Appendix 1 for full details.
Workload Overview
HammerDB is the benchmarking tool to drive database load testing to MariaDB, with a focus on the aggregate TPM (Transactions Per Min) throughput value that can be achieved by scaling up the total number of “instances”. The client-server pair was contained within the same instance to drive each database load.
The pods and Linux VMs were configured to request 8 GiB of memory and the VMs were defined with 16 vcpus, otherwise using default template settings. Note that pod memory was not limited while VM memory usage is defined by the guest memory size, each database instance was configured to use 4GiB.
Scaling Study
For this scaling study, a “medium” user load (i.e. thread count) of 40 was chosen to represent a meaningful workload. HammerDB is a synthetic benchmark tool where user counts do not represent max capacity as each user enters transactions as fast as possible with zero sleep delay. The main goal was to validate that VM performance approaches what the hardware is capable of.
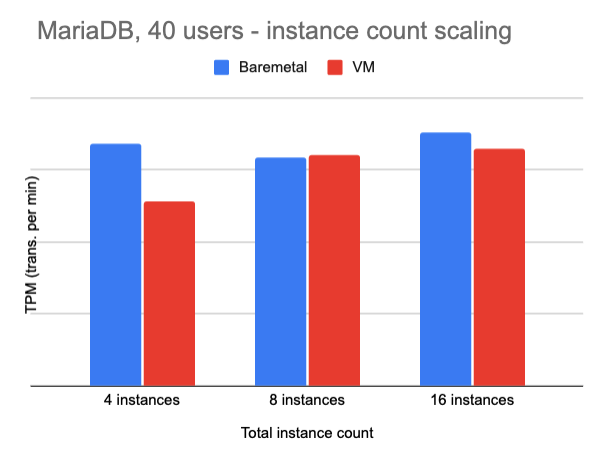
MariaDB throughput scales to bare metal performance as the total number of instances is scaled up from 4, to 8, to 16 instances. In more common production environments with multiple database instances, OpenShift efficiently shares resources as the workload increases.
On such a large server, the total system was under utilized at 4 total instances, the VMs achieved 80% of bare metal performance in that case.
Summary
OpenShift demonstrates strong out of the box VM performance for demanding workloads like databases. VM throughput scales to the native hardware capabilities without any special tuning. To further improve performance, workload-specific tuning is available to optimize performance of databases and other business critical workloads.
Our team continually tests different aspects of VM performance on OpenShift, be sure to keep an eye out for more updates in the future around higher VM density with memory overcommit, more in-depth database tuning coverage, VM live migration, and more! Also check out our Red Hat Performance and Scale Engineering page for more updates.
Appendix 1 - System configuration
Full system details:
- CPU - Intel(R) Xeon(R) Gold 6430 x 2
- 64 cores x 2 threads, 128 total CPUs
- Memory - 512 GiB RAM
- Storage
- 250 GB SATA (system drive)
- 2x Dell Enterprise NVMe P5620 (3.2 TB)
- configured as RAID0 (striped) with:
mdadm --create --level=0 --raid-devices=2 /dev/md0 /dev/nvme1n1 /dev/nvme0n1 - LVM operator was configured to consume this striped device and pods and VMs requested PVCs from the LVM StorageClass
- configured as RAID0 (striped) with:
These tests targeted local storage to focus on virtualized performance without the extra complexity of a network-based storage solution. For the results discussed here, the LVM operator was configured to provide the default StorageClass. Note: the OpenShift server and all operators were running version 4.14.