Cloud-native environment architecture can be challenging to understand. To help make sense of it for application developers and software/system architects, I will attempt to explain the various parts and how they work together. Toward this end, I find it helpful to think about the architecture in four separate layers: application software development, service scaling, application network, and container orchestration platform.
In this article, I will describe the first technology layer: application software development. I drew the following diagram to make these concepts easier to visualize.
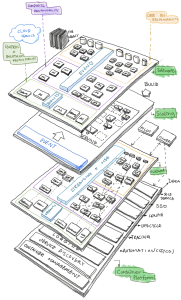
Container native or cloud-native application development is often referred to as a common greenfield system, where applications are broken down into microservices. Each microservice tends to have its own source of data, be independent from the others, and also be deployed in a distributed way.
The benefit of such implementation makes applications ever more agile and polyglot, isolating problems, and making the codebase smaller and supposedly easier to maintain. If I tell were to you that this means life will be good from now on, I would be lying.
To achieve the benefit of an agile, truly scalable, automated container/cloud-native system, a lot of thought needs to go into considering factors like applications, platforms, and personas, including:
- Using the right technology for the scenario
- Complex solutions can sometimes be overkill
- Using the wrong solution in the wrong place can cause displaced responsibility
- Domain-driven design with continuous integration
- Async events or API
- How to integrate with existing brownfield applications
The diagram shows a rough overview of how various elements of container/cloud-native system work together, and I hope it also helps you decide when or whether to introduce a particular piece of technology.
To make more sense for application developers and software/system architects, I deliberately divided the architecture into four planes. Each plane itself can be broken into much more detail. It consists of many pieces of technologies, and these are abstracted based on the fundamental functionality they bring to the cloud-native application environment.
Application software development layer
The application software development layer is about modeling domains, how microservices are defined, how they should be deployed, and the software patterns applied in the system that can help to develop a loosely coupled and continuously evolving system. It’s also about the communication technology and patterns between applications.
Service scaling — Knative
Scaling to zero when the application is not in use will allow resource optimization. This layer takes the characteristic of cloud computing to the fullest, but not all services need it.
Application network — Service mesh
This is a very common architecture functionality in the distributed microservices environment. Having this layer allows better and more uniform control over the communication between microservices and better observability, too. DevOps can use this layer to apply common security, failure recovery, rollout policies, etc., as well as setting customized ones. This layer takes away much redundant work for developers.
Container orchestration platform — Red Hat OpenShift
This is the foundation of cloud-native environment architecture. It provides basic and essential capabilities, such as container orchestration, service discovery, CI/CD automation, logging, etc.
Domain-driven design and Agile Integration
Domain-driven design (DDD) principles apply to the way we develop applications in cloud-native world, by allowing better communication between business users and developers, modeling objects according to the domain, and setting boundaries to segment the complex business requirement. An important aspect of DDD is continuous integration.
Agile Integration evolved from the basic concept of microservices and DDD. In software development other than modeling the business logic, many other factors also need to be taken into account. Agile integration on top of DDD helps you better define not only the model and the boundaries but also how they should be separated by different functional concerns and how they can be physically deployed. There are three main responsibilities for agile integration:
- Core — The majority of the microservice that implements business logic or domain capability belongs to this category. They are a good example of typical small simple microservices that are lightweight in both runtime and how it communicates to each other.
- Composite — Setting the right granularity of the service, handling transactions, orchestrating, and transforming data for various types of events are all handled here. Aggregation and separation of data and events are done in this category. This acts as the simple stateless pipe that directs the events from one point to another in the desired and suitable format and sometimes needs to be the gateway to external SaaS, brownfield application or even services outside the bounded context.
- Control and dispatch — If the system only interacts with a handful of external systems, you may not need this category. This category allows you to have more insight and meaningful business control over the services your system provides. It's a place to hide the constant bothersome customization from external client requests that require quick and ad hoc changes. Facade pattern applies in this category.
Applying the above principles will allow you to:
- Capture the model and entities from the business requirement.
- Set the boundaries between business domains.
- Categorize the nature of the code and separate it into independent, separate, deployable microservice instances.
Another important fundamental problem is the communication between these microservices. I believe the communication backbone of these microservices should mostly be event-driven and asynchronous, so the distribution of data can be loosely coupled, and the system will become reactive. A drawback is that this type of design can make transactions rather complicated, but this can be overcome by implementing techniques like event sourcing. For communication between boundaries or external clients/partners, I strongly suggest using API simply because:
- Most of these processes are in the form of request and reply, which is the natural default behavior of REST API.
- Contract definition and repository management technology are more mature in the API space.
Next time, I will talk about different types of data in the events and how to handle them, as well as how to achieve data consistency in the cloud-native application environment. I'll also look at all the other layers in my cloud-native application overview: service scaling, application network, and container orchestration platform.
Last updated: July 12, 2019