Integration testing is still an important step in a CI/CD pipeline even when you are developing container-native applications. Integration tests tend to be very resource-intensive workloads that run for a limited time.
I wanted to explore how integration testing technologies and tools could leverage a container orchestrator (such as Red Hat OpenShift) to run faster and more-dynamic tests, while at the same time using resources more effectively.
In this post, you will learn how to build behavior-driven development (BDD) integration tests using Cucumber, Protractor, and Selenium and how to run them in OpenShift using Zalenium.
The code for the example of this article can be found on GitHub in redhat-cop/container-pipelinesh.
BDD testing
I like to use BDD testing when developing integration tests.
The reason I like this approach is that it allows the Business Analysts (BAs), not the developers, to define the integration tests. With BDD, it is possible to create a development process where requirements and integration test definitions are ready at the same time and are created by the BA team.
This approach is much better than traditional approaches, such as the one shown in the diagram below, where integration tests are created by the Quality Assurance (QA) team after the development of the business capabilities is completed.
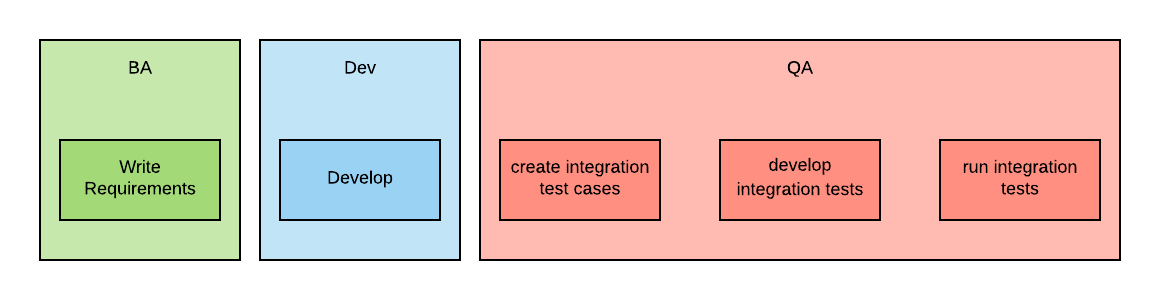
With BDD, the process looks more like the following:
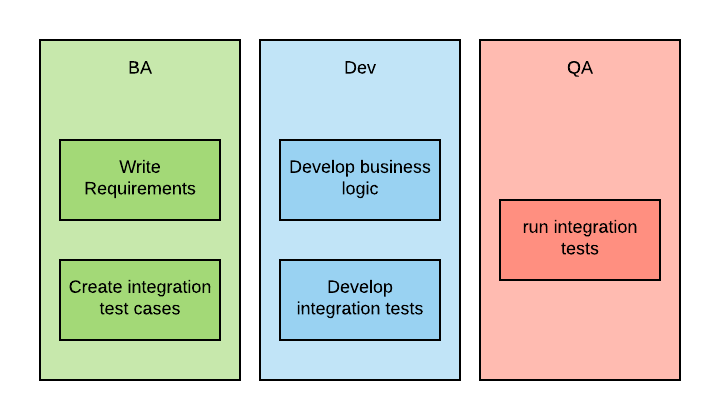
And each iteration typically takes a shorter time.
BAs can write integration tests definitions because in BDD, integration test cases are expressed in Gherkin, which is a computer language that is very similar to natural language. The main keywords that Gerkin has are Given, When, and Then, and every statement in Gherkin must start with one of them.
Here is an example:
Given the user navigated to the login page
When the user enters username and password
When username and password are correct
Then the system logs them in
A popular runtime that is able to interpret Gherkin tests is Cucumber. When using Cucumber, a developer is required to implement some functions so that each Gherkin statement can be executed. Cucumber has bindings with many languages. It is recommended, but not mandatory, to write the tests in the same language as the application being tested.
Test technology stack
The application that we are going to test is the TodoMVC web app in its AngularJS implementation. AngularJS is a very popular framework for writing single-page applications (SPAs).
Because AngularJS is in JavaScript, we are going to use Cumcumber.js, the Cucumber binding for JavaScript.
To emulate the user interaction with the browser, we are going to use Selenium. Selenium is a process that can spin up browsers and emulate user interaction based on commands it receives via an API.
Finally, we are going to use Protractor to deal with some peculiarities of emulating an SPA that is written in AngularJS. Protractor takes care of waiting to ensure that the views inside the page are correctly loaded.
Overall, our test stack will look as follows:
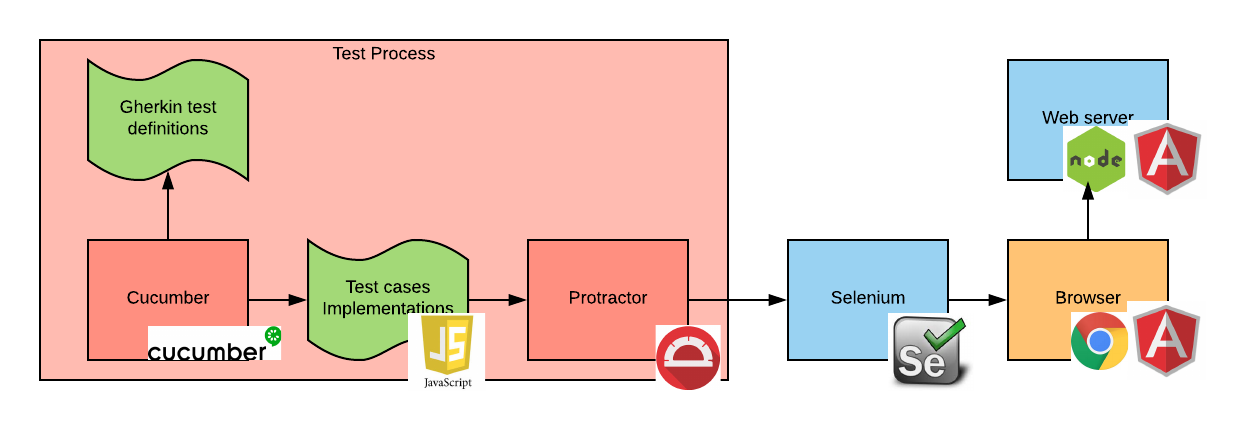
The process that the diagram tries to describe is the following:
- When the Cucumber tests are started, Cucumber reads the test definitions from the Gherkin file.
- Then it starts calling the test case implementation code.
- The test case implementation code uses Protractor to perform actions on the web page.
- When that happens, Protractor connects to the Selenium server and issues commands via the Selenium API.
- Selenium executes these commands in a browser instance.
- The browser connects to the web server(s) as needed. In our case, because we are using an SPA, the application is loaded as the first page load from the web server and then no more communication is needed.
Setting up this stack in a non-container based infrastructure is not simple, not only because of the number of processes and frameworks needed, but also because starting browsers in headless servers has been historically difficult. Fortunately for us, in a container-native world, we can easily automate all of this.
Integration test farm
Enterprises need to test their web applications with different combinations of browsers and operating systems. Usually, application owners will prioritize testing those combinations that are prevalent in the application user population. Normally, at least about half a dozen combinations are needed for each application.
Setting up different stacks and executing each of the test suite(s) sequentially on each stack is expensive in terms of resources and time.
Ideally, we would like to execute the tests in parallel.
To help solve this problem, we can use Selenium-Grid. Selenium-Grid is a solution comprising Selenium Hub, which is a request broker, and one or more nodes that can be used to execute requests.
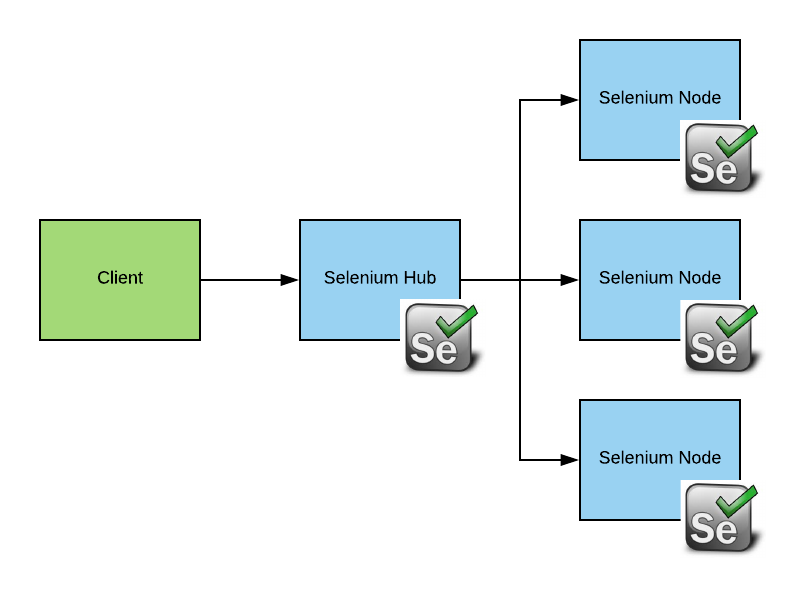
Each Selenium node, which is usually running on different server, can be set up with different combinations of browsers and OSs (these and other characteristics are called capabilities in Selenium). The Hub is smart enough to send requests that require certain capabilities to the node, which can meet them.
Installing and managing Selenium-Grid clusters is relatively complex—so much so, that an entire market was created to offer this service. Some of the main players of this market are SauceLabs and BrowserStack.
Container-native integration tests
Ideally, we would like to be able to create a Selenium-Grid cluster with nodes that offer the right capabilities for our tests and run the tests with a high degree of parallelism. Then, once the tests are done, we'd destroy all of this infrastructure. This basically means re-creating on premises some of the services that are offered by integration test farm service providers.
I think the technology is still maturing in this space, and I found a very promising open source project that does some of what we need: Zalenium.
Zalenium runs a modified Hub that is able to create nodes on demand and destroy them when they are not needed anymore. Currently, Zalenium supports only Chrome and Firefox on Linux. With the advent of Windows nodes for Kubernetes, it is conceivable to enhance it to support also Explorer and Edge on Windows.
If we put together all of our technology stack, it would look as follows:
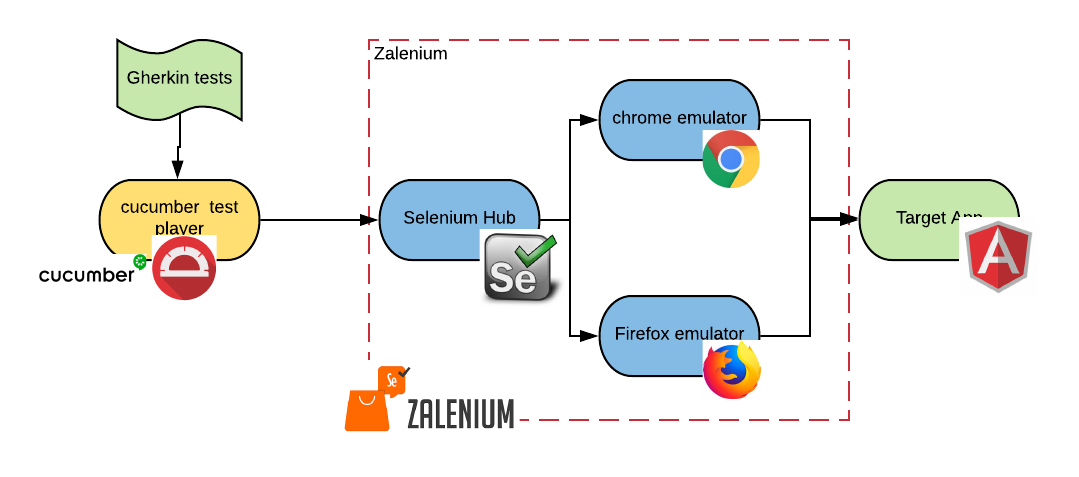
Each of the ovals in this diagram is going to be a different pod in Kubernetes. The test player pods and the emulator pods are ephemeral and will be destroyed at the end of the test.
Running the integration tests in a CI/CD pipeline
I created a simple pipeline in Jenkins to shows how this type of integration test can be integrated with the rest of the release management process. The pipeline looks as follows:

Your pipelines may differ, but you should still be able to reuse the integration tests step without too much refactoring.
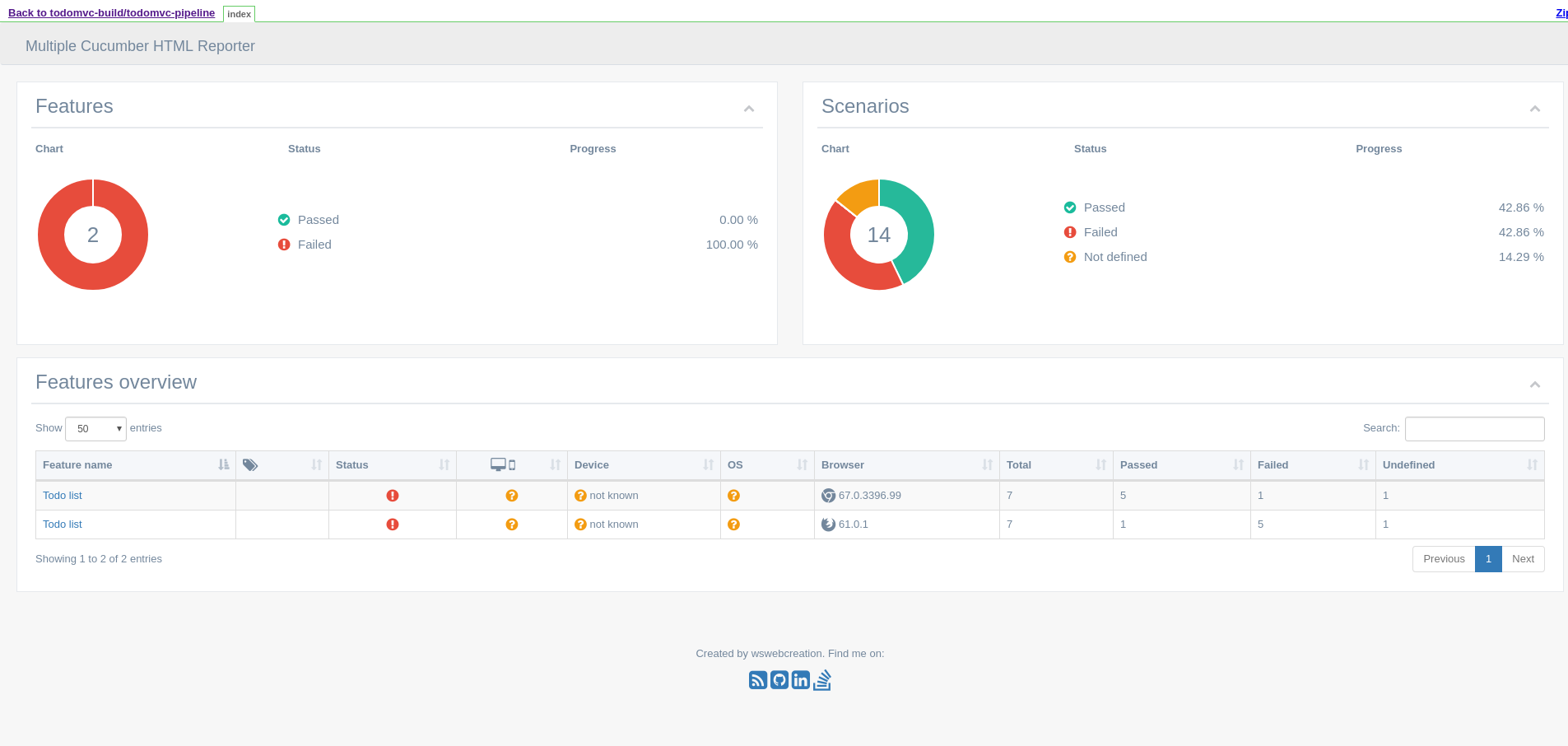
Because most of the pods are ephemeral, one important task of the pipeline is to collect the test results. Jenkins has its own way of doing that with the archive and publishHTML primitives.
This is the kind of report that you can expect from a test run (notice that the tests have been run for two browsers):
Conclusion
In this article, we have seen how complex it can be to set up an end-to-end integration test infrastructure and that the process can be simplified by using an infrastructure-as-code approach. We have also seen that running integration tests for multiple combinations of OSs and browsers can waste resources and time, and that a container orchestrator and ephemeral workloads can help mitigate that.
I think there is an opportunity for more-mature tools in the space of container native-integration testing. Yet it is possible today to run integration tests in a container platform and take advantage of a container-native approach.
When you are developing container-native applications, try using this container-native approach in your CI/CD pipeline to see if it can streamline your integration testing.
Last updated: March 26, 2023