If you saw or heard about the multi-cloud demo at Red Hat Summit 2018, this article details how we ran Red Hat Data Grid in active-active-active mode across three cloud providers. This set up enabled us to show a fail over between cloud providers in real time with no loss of data. In addition to Red Hat Data Grid, we used Vert.x (reactive programming), OpenWhisk (serverless), and Red Hat Gluster Storage (software-defined storage.)
This year’s Red Hat Summit was quite an adventure for all of us. A trip to San Francisco is probably on the bucket list of IT geeks from all over the world. Also, we were able to meet many other Red Hatters, who work remotely for Red Hat as we do. However, the best part was that we had something important to say: “we believe in the hybrid/multi cloud" and we got to prove that live on stage.

Our keynote demo
In one of the earlier keynote demos, our hybrid cloud was provisioned live in a rack on stage with Red Hat OpenShift. It was quite impressive to see all the tools working together to make the demo succeed. Together with a group of teammates, we were responsible for creating the fourth keynote demo, which involved interesting middleware technologies such as Red Hat Data Grid, Vert.x, OpenWhisk, and Red Hat Gluster. You watch the demo online if you haven't already seen it:
What you couldn’t see is that we had a maintenance team sitting behind the scenes, observing whether everything was fine (below, Marek Posolda from the Red Hat SSO team and Galder Zamarreño from the Red Hat Data Grid team):

The demo went well, so it's time to explain how we did it.
Keynote Demo #4 Architecture
We were using three data centers (Amazon, Azure, and the on-stage rack) that were working in an active-active-active replication configuration.
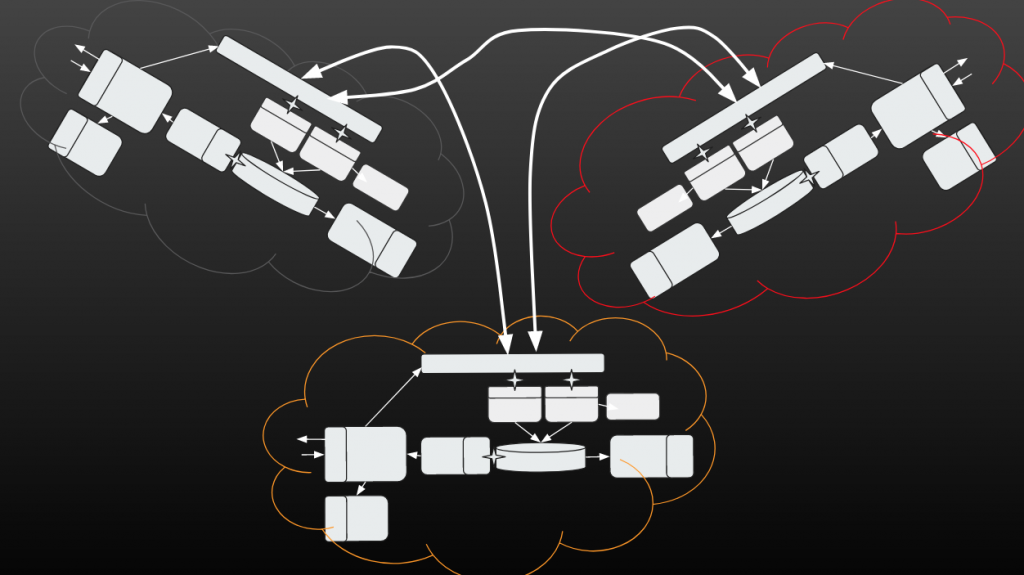
Each site was using a microservices and serverless architecture. We also used two storage layers: Gluster for storing images and Red Hat Data Grid for storing metadata (in JSON format):
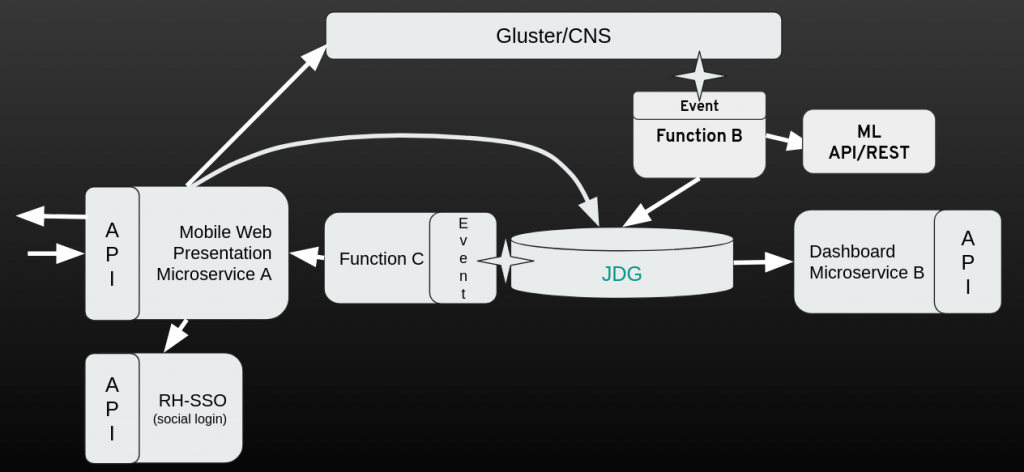
Data Grid Setup for Cross-site Replication
The active-active-active setup for Red Hat Data Grid was implemented using Cross-site replication (also known as x-site replication) feature. However, we had to slightly adjust the configuration:
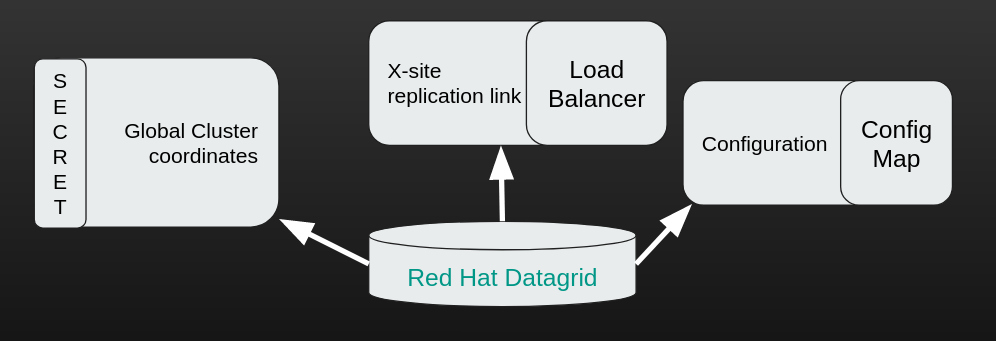
The sites communicated with each other using Red Hat OpenShift’s load balancer services. The load balancers were allocated up front and their coordinates (all three clouds) were injected into a secret, creating a so-called global cluster discovery string. The configuration XML file was put into a ConfigMap allowing us to easily update the configuration manually from the UI (if needed).
Since we strongly believe in automation, we created automated setup scripts for provisioning Red Hat Data Grid to all three clouds. The scripts can be found on our GitHub repository. We also provided a customized version of the scripts that can simulate x-site replication using three different projects. You might start the Red Hat OpenShift Container Platform local instance using the oc cluster up command and then run this provisioning script.
Now, let’s have a look at all the configuration bits and explore how they work together (you may check them using the local provisioning script). Let’s start with the global cluster discovery secret:
https://gist.github.com/slaskawi/91ff7aff0584f5ebb52b3a2314db46ef
The DISCOVERY string is specific to TCPPING, which was used for global cluster discovery. The next parameter is EXT_ADDR, which represents the load balancer's public IP address. The JGroups communication toolkit needs to bind the global cluster transport to that particular address. SITE describes the local site: is it Amazon or Azure or is it the private (on-stage rack) one?
The next piece of the puzzle is configuration. The full XML file can be found here. In this blog post, we will focus only on the crucial bits:
https://gist.github.com/slaskawi/54a7b231d69cf0f953e38baa14f3f368
The local cluster (inside a single data center) discovers all other members using the KUBE_PING protocol. All the messages are forwarded to other sites using the RELAY2 protocol. The value of jboss.relay.site is injected into environmental variables using the Downward API from the jdg-app secret. The last interesting bit is that max_site_masters is set to 1000. Since we do not know how many instances there are behind the load balancers, we need to ensure that each one of them can act as a site master and forward all the traffic to the other site.
The next stack is defined for the RELAY protocol:
https://gist.github.com/slaskawi/7483ef2915bf53e2cf2abad080c5f5ab
Starting from the TCP protocol, we need to ensure that we bind into the load balancer public address. That’s why all of the load balancers have to be provisioned up front. Again, we inject this variable from the jdg-app secret. Another interesting piece is TCPPING, where we use the global cluster discovery string (from the jdg-app secret). The FD_ALL timeout is set to a quite high number, since we would like to tolerate short site downtimes.
https://gist.github.com/slaskawi/35c57399c89168e60dbcd2a96bc8baf9
Each site configured all three sites as async backups. This allows achieving an active-active-active kind of setup.
Final Thoughts
An active-active-active setup is a very interesting approach for handling a large amount of globally routed traffic. However, a few things need to be considered before implementing it:
- Do not write the same key from different data centers. If you do, you may get into trouble very quickly due to network delays.
- When the site goes down and comes back up again, you must trigger a state transfer to synchronize it. This is a manual task, but we are working hard to making it fully transparent.
- Make sure your application can tolerate asynchronous replication. Cross-site replication with synchronous caches might be problematic.
We learned a lot about globally load-balanced setups during the demo work. Discovering new use cases was quite fun and we believe we know how to make Red Hat Data Grid even better for these kinds of scenarios.
Have fun with the cross-site replication and see you at the next Summit!
The Red Hat Data Grid Team
