CPU and network speed have increased significantly in the last decade, as well as memory and disk sizes. But still one of the possible side effects of moving from a monolithic architecture to Microservices is the increase in the service latency. Here are few quick ideas on how to fight it using Kubernetes.
It is not the network
In the recent years, networks transitioned to using protocols that are more efficient and moved from 1GBit to 10GBit and even to 25GBit limit. Applications send much smaller payloads with less verbose data formats. With all that in mind, the chances are the bottleneck in a distributed application is not in the network interactions, but somewhere else like the database. We can safely ignore the rest of this article and go back to tuning the storage system. :)
Kubernetes scheduler and service affinity
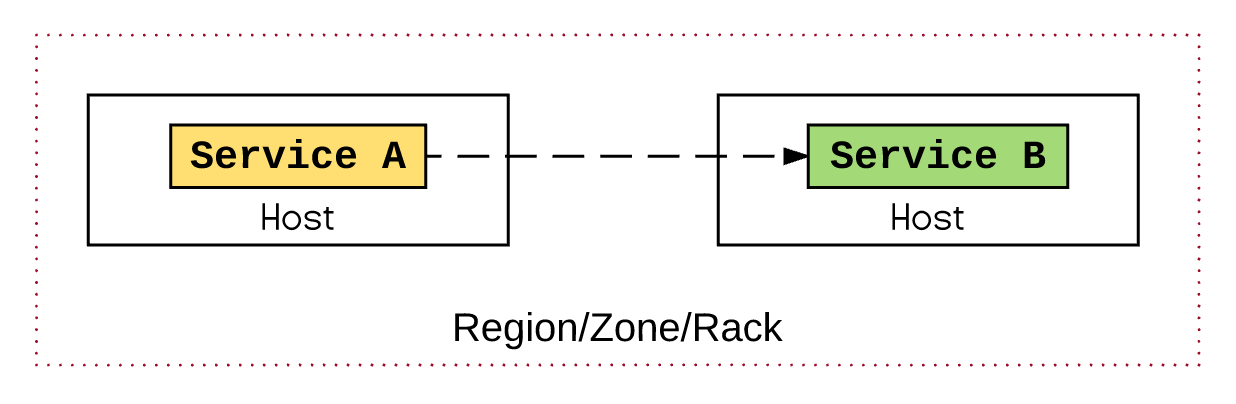
If two services (deployed as Pods in the Kubernetes world) are going to interact a lot, the first approach to reduce the network latency would be to ask politely the scheduler to place the Pods as close as possible using the node affinity feature. How close, depends on our high availability requirements (covered by anti-affinity), but it can be co-located in the same region, availability zone, rack or even on the same host.
Run services in the same Pod
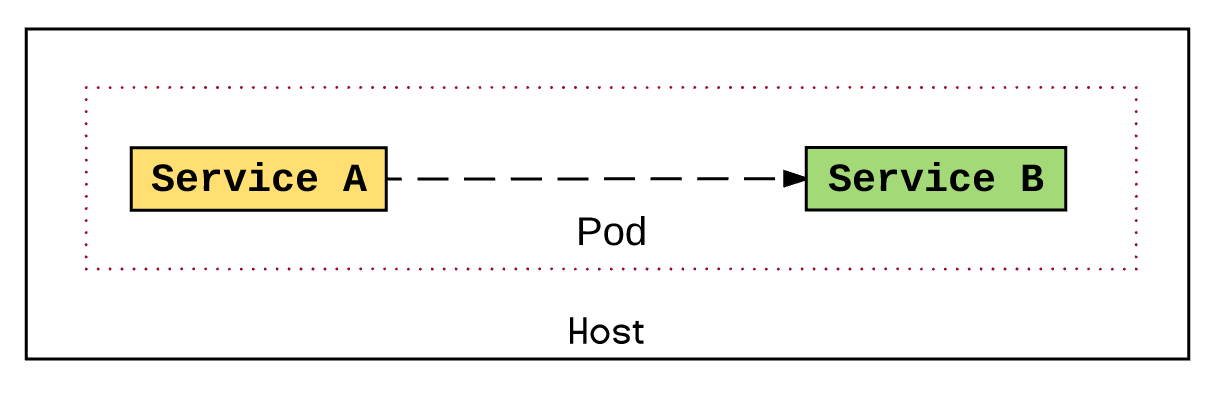
The deployment unit in Kubernetes (Pod) allows a service to be independently updated deployed and scaled. But if performance is a higher priority, we could put two services in the same Pod as long as that is a deliberate decision. Both services would still be independently developed, tested, released as containers, but they would share the same runtime lifecycle in the same deployment unit. That would allow the services to talk to each other over localhost rather than using the service layer, or use the file system, or use some other high performant IPC mechanism on the shared host, or shared memory.
Run services in the same process
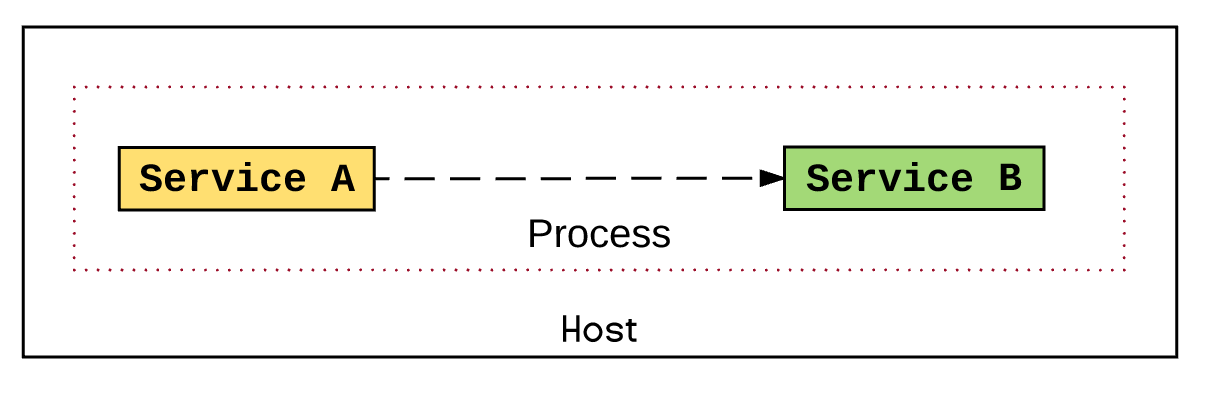
If co-locating two services on the same host are not good enough, we could have a hybrid between microservices and monolith by sharing the same process for multiple services. That means we are back to a monolith, but we could still use some of the principles of Microservices, allow development time independence, and make a compromise in favor of performance on rare occasions.
We could develop and release two services independently by two different teams, but place them in the same container and share the runtime.
For example, in the Java world that would be placing two .jar files in the same Tomcat, WildFly, or Karaf server. At runtime, the services can find each other and interact using a public static field that is accessible from any application in the same JVM. This same approach is used in Apache Camel direct component, which allows synchronous in-memory interaction of Camel routes from different .jar files by sharing the same JVM.
Other areas to explore
If none of the above approaches seems like a good idea, maybe you are exploring in the wrong direction. It might be better to explore whether using some alternative approaches such using a cache, data compression, HTTP/2, or something else might help for the overall application performance.

About the author:
Bilgin Ibryam is a member of Apache Software Foundation, integration architect at Red Hat, a software craftsman, and blogger. He is an open source fanatic, passionate about distributed systems, messaging and application integration. He is the author of Camel Design Patterns & Kubernetes Patterns books. Follow @bibryam for future blog posts on related topics.
Download this Kubernetes cheat sheet for automating deployment, scaling and operations.