Editor's note: Raffaele Spazzoli is an Architect with Red Hat Consulting's PaaS and DevOps Practice. This blog post reflects his experience working for Key Bank prior to joining Red Hat.
A recount of the journey from three-months, to one-week release cycle-time.
This is the journey of KeyBank, a super-regional bank, from quarterly deployments to production to weekly deployments to production. In the process we adopted all open source software migrating from WebSphere to Tomcat and adopting OpenShift as our private Linux container cloud platform. We did this in the context of the digital channel modernization project, arguably the most important project for the bank during that period of time.
The scope of the digital channel modernization project was to migrate a 15-year old Java web app that was servlet-based, developed on a homegrown MVC framework and running on Java 1.6 and WebSphere 7.x to a more modern web experience and to create a new mobile web app.
This web app had grown more expensive to maintain and to meet our SLAs. It was the quintessential monolith app. Our architectural objective was to create an API layer to separate the presentation logic (web or mobile) from the business logic --- what lay ahead was an effort to completely modernize the continuous integration and deployment process.
At the outset we were on a quarterly release schedule. The release process was expensive and painful. It was very high ceremony release process (there was an Excel spreadsheet with about 70 manual steps), done during the weekend, in hopes that the system was back online for regular business processing by Monday morning. That was the type of confidence we had, it didn't feel right and it didn’t make me proud.
So, I did some research on how the bigs (Google, Amazon, Facebook etc..) were managing their releases and I was lucky enough to be sent to a conference where Netflix was presenting their approach. It turned out that these organizations were two or three orders of magnitude better than us on any release related metric (frequency, cost, code-complete to code-in-production time).
I decided to challenge our delivery organization to move from quarterly releases to weekly releases. Frankly that challenge was not taken too seriously, but that objective stuck in my mind. I thought that weekly releases were reasonable for the digital channel of a bank. Not the ridiculous speed of the Silicon Valley start-ups and yet fast enough to not leave room for meetings, manual testing, manual release steps. In other words, fast enough to force change.
My role in the project was to be the solution architect. So I pushed a new architecture with a fully stateless REST service layer and two front-ends: an AngularsJs based web app and an Ionic framework-based mobile app (based mostly on the same code as the web app).
At this point our plan was still to run this new app on WebSphere, so I started asking our Ops team for a series of changes.
I asked for an update of the JDK (from version 6 to version 7). I needed a more recent JDK to be able to write REST services leveraging JAX-RS.At first Ops was reluctant, then when the team realized that the JDK currently in use was going to be in end of life soon, they started the work to enable the new JDK. The process took about 6 months.
I asked to be able to use Liberty as the application server. WebSphere had a very slow startup time on the developer laptops. The startup time was anywhere between 5 and 10 minutes and we needed something more agile and fast given the big endeavor we were about to start. I was answered that we could use Liberty on our laptops, but the only production supported application server was going to be WebSphere. So, that is what we did with a very uncomfortable feeling around it because intuitively we knew that production parity was important to “going faster”, otherwise too many bugs show up when changing major elements of the stack in the higher environments (IT, QA, Production).
I asked for a distributed cache tool. I needed a distributed cache tool because I wanted our service layer to be completely stateless (and session-less) and we needed a cache for efficiency reasons. I was answered that there wasn't an officially supported distributed cache platform available, one day maybe there would have been one.
These episodes (and others not mentioned) got me thinking, we clearly were doing it wrong. The dev team was not able to voice their needs the right way, the ops team was probably too worried about keeping the lights on and maintaining the status quo and I, in between, as the solution architect was probably not able to moderate the conversation and lead it in a productive way.
I felt I needed to completely change the model and get rid of the maze of service requests that was used by the delivery team to get infrastructure delivered by the ops team. At one point a study was done by another team which had to stand-up a completely new infrastructure and they concluded that they had to fill about four hundreds requests.
I felt the delivery team should have been able to self provision its own infrastructure. I concluded we needed a private cloud infrastructure. So, I set out doing my own research to see what was the best tool available.
At the same time a small ops team had just solved some very nasty and long standing networking issues and was given the next difficult nut to crack which was building a private cloud at KeyBank.
We teamed up, and, based on our research, we decided that Kubernetes was the best container-based private cloud platform available. It didn’t make sense for us to go with a VM-based cloud platform because we could see that containers were technologically better than VMs.
We looked for professional support for Kubernetes and we saw in Red Hat and its OpenShift platform a very credible proposal.
The events that followed happened at a very fast pace. After engaging with Red Hat, we were in production preview in 4 months and production with the first wave of customers in 7 months.
We migrated the application from WebSphere to Tomcat, we swapped out the REST engine moving from Wink to the more popular Jersey (which we couldn't make work in WebSphere) and we added Hystrix, implementing the circuit breaker pattern as part of our availability strategy. We used Redis for our distributed cache implementation.
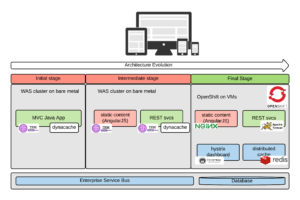
But the technical piece is always the easiest one. Our objective was still to enable weekly releases and the principles we wanted to follow to get there were: self provisioning of infrastructure and immutable infrastructure.
In order to achieve our objectives we needed to define the ownership and support models for applications deployed in OpenShift. In fact, if the development team can self-service their own infrastructure the question was: who was going to support it? Looking at what Google, Netflix, Spotify do, we pushed a model where the delivery team was responsible of the infrastructure they required (essentially what they put in their containers) and the ops team had the task to keep OpenShift available (obviously OpenShift needs to be more available than anything that runs on it, which means a lot of nines for a bank). To make sure that ownership was clear, we decided to put the OpenShift configuration files for a given project together with the rest of the project source code.
We also needed to automate everything via a continuous delivery pipeline.
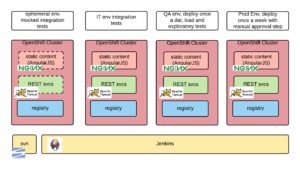
We built a pipeline in Jenkins with the following logic:
- Every ten minutes the source code repository would be polled and if there was any change we would trigger an new build.
- The build would run unit tests and anything else needed to create the docker image of our project. This docker image is never changed from now on. This is one of the points where our immutable infrastructure approach emerges.
- The next step was to run a series of integration tests on each layer of the solution in isolation. By isolation I mean that outbound dependencies were mocked. This allowed us to run a series of test independently of the availability on the downstream dependencies and of the quality of the test data. These tests were run in an ephemeral environment (something relatively easy to do in OpenShift).
- The following step was to run a series of integration tests in the IT environment.
- Once a day we would deploy the last successful build in the QA environment. This environment was used for manual exploratory tests and manual (for now) load tests.
- The last step was to deploy once a week in production-preview. This step required manual approval.
Putting something in production required several approval steps at KeyBank. These took the form of meetings in which people were presenting what was going to be deployed and senior leaders would sign-off on the release. This process didn’t work for us, there was just not enough time to have three of those meetings every week (yes, there were three different committees that needed to be convinced of the sanity of the release). We were able to change the process and agree that if a release was only impacting components inside OpenShift then we were automatically approved to release.
The last piece that we needed was full coverage of our automated regression test suite. We soon realized through a few painful mistakes that we could not accelerate to weekly releases unless we had full regression test coverage. In fact the manual test team could just not be fast enough to retest everything every week.
We built our testing framework using some of the Behavioral Driven Development (BDD) principles. We choose Cucumber as our BDD tool. The nice thing about Cucumber is that it allows you to write test cases in natural language (English or other). We decided to take advantage of that and ask the business analyst team to write the test cases. By doing that we were able to parallelize the development of the business code and the development of the test code, as opposed to before when the two were sequential and therefore the tests (either manual or automatic) were always testing an old version of the code. We used Selenium to test several combinations of browser and OSes for the browser app and Appium to test several combinations of mobile devices and OSes for the mobile app.
Conclusions
Now at KeyBank the confidence in our release process has greatly increased and we are able to release on Thursday morning, every week. Using Rolling deployment, one of OpenShift out of the box features, we are able to do zero downtime releases, which was a long standing request for which we had never found a good solution before.
We have also enabled autoscaling. We deeply tested this feature during our load tests and we now know that our system (or at least the tiers of it that are deployed in OpenShift) will react to load spikes by scaling horizontally to the correct number of instances necessary to manage the current load.
This is considered a remarkable success story inside the bank and the next steps will be to replicate the same process for other projects, moving more and more workloads to OpenShift.
Last updated: March 17, 2023