Confidential computing enhances cloud-native security by protecting data in use, a state traditionally vulnerable even with encrypted data at rest and in transit. It leverages hardware-based security, such as secure enclaves and memory encryption, to create a trusted execution environment (TEE) for sensitive workloads. It removes reliance on host OS, hypervisor, and cloud provider trust by using hardware-based security, memory encryption, and remote attestation to ensure only verified software accesses sensitive workloads. In this article, we will share how a trusted execution cluster operator orchestrates trust across the entire cluster by automating the configuration and lifecycle management of attestation and secret distribution services.
The trusted execution cluster operator design
The trusted execution cluster operator is a Kubernetes-native operator designed to configure and manage trusted execution Kubernetes clusters deployed on machines which provide support and confidential computing capabilities, such as AMD Secure Encrypted Virtualization-Secure Nested Paging (SEV-SNP) and Intel Trust Domain Extensions (TDX). In these environments, each Kubernetes node runs entirely within a Trusted Execution Environment (TEE).
A unified kernel image (UKI) streamlines the Linux boot process by consolidating the kernel, initial ramdisk (initrd), and kernel command line into a single, signed EFI executable. This modern approach enhances security, reliability, and manageability compared to using separate boot components.
Each confidential node undergoes a first-boot attestation process where critical system components—including the firmware, bootloader, UEFI shim, and UKI —are measured and cryptographically verified. This establishes a trusted computing base (TCB) rooted in hardware. Once attestation is successful, the Trustee releases the secret LUKS key to encrypt and decrypt the node’s root disk, ensuring that persistent storage remains protected even if a physical or virtual infrastructure is compromised.
The Trustee is a set of components which form the trust and key management backbone of a trusted execution cluster. It includes:
- The key broker service (KBS) responsible for facilitating remote attestation and secret delivery.
- The attestation service to verify the TEE evidence.
- The reference values providers.
The trustee acts as the policy enforcement and validation authority, verifying the quote (a cryptographically signed attestation report) sent by the TEE.
While the Trustee service is responsible for performing attestation and validating quotes from each node’s Trusted Execution Environment (TEE), the operator provides a cluster-wide control plane to ensure that this process is scalable and policy-driven. Specifically, the operator:
- Configures certificates for Trustee: Automates the provisioning and rotation of cryptographic certificates required for Trustee for https.
- Calculates reference measurements: Derives and maintains the expected “golden” measurements (hashes of firmware, bootloader, kernel, and other trusted components) that nodes must match during attestation.
- Manages secrets and resource policies: Generates cryptographic materials (i.e., LUKS disk encryption keys or container runtime secrets) for each node, enforcing strict resource-level access controls and ensuring it delivers secrets only to verified environments.
- Generates attestation policies: Creates and updates the attestation policies that define acceptable node configurations and integrity baselines, enabling dynamic policy updates as the trusted software stack evolves.
Remote attestation flow
Finally, we will look into the attestation flow, examining its implementation through Ignition, a new Clevis pin, and the interaction between the operator and Trustee. We will also analyze the policy and how the Trustee assesses a node's TCB to determine its trustworthiness and ultimately deliver the LUKS key.
The components involved in attestation are:
- Ignition: A first-boot provisioning tool that configures a machine the very first time it starts.
- Clevis pin: A pluggable framework for automated decryption.
- Trustee server: The central remote attestation framework that verifies trust evidence.
- Trustee attester: The component on each node that collects evidence and performs remote attestation.
- Trusted execution cluster operator: The Kubernetes operator responsible for configuring the Trustee server and managing attestation and resource policies.
- Registration service: Part of the operator that serves node-specific ignition configs and registers nodes before attestation.
When a node boots for the first time, it starts with an initial Ignition configuration. This configuration includes a merge directive that tells the node to fetch a remote ignition file from the registration server. Unlike the initial config, the remote ignition contains a unique UUID (Universally Unique Identifier) assigned to that node.
Fetching this remote ignition acts as the registration phase and the registration server asynchronously creates a new Machine object associated with the node’s UUID.
The remote ignition also contains the clevis pin configuration. Once applied, clevis triggers attestation by invoking the Trustee Attester, which contacts the Trustee Server. The server validates the node’s evidence and, if successful, provides the LUKS key needed to set up the disk encryption. Clevis, then, writes this information into the LUKS header and secures the disk.
Meanwhile, the operator monitors for new machine objects. When it sees one, it generates a new secret, registers it with the Trustee, and updates the attestation and resource policy with UUID-specific rules.
The synchronization point is the attestation itself. It only succeeds when the attestation policy and the resource policy include the correct UUID rules, and the corresponding secret is available in Trustee. Figure 1 illustrates this flow.
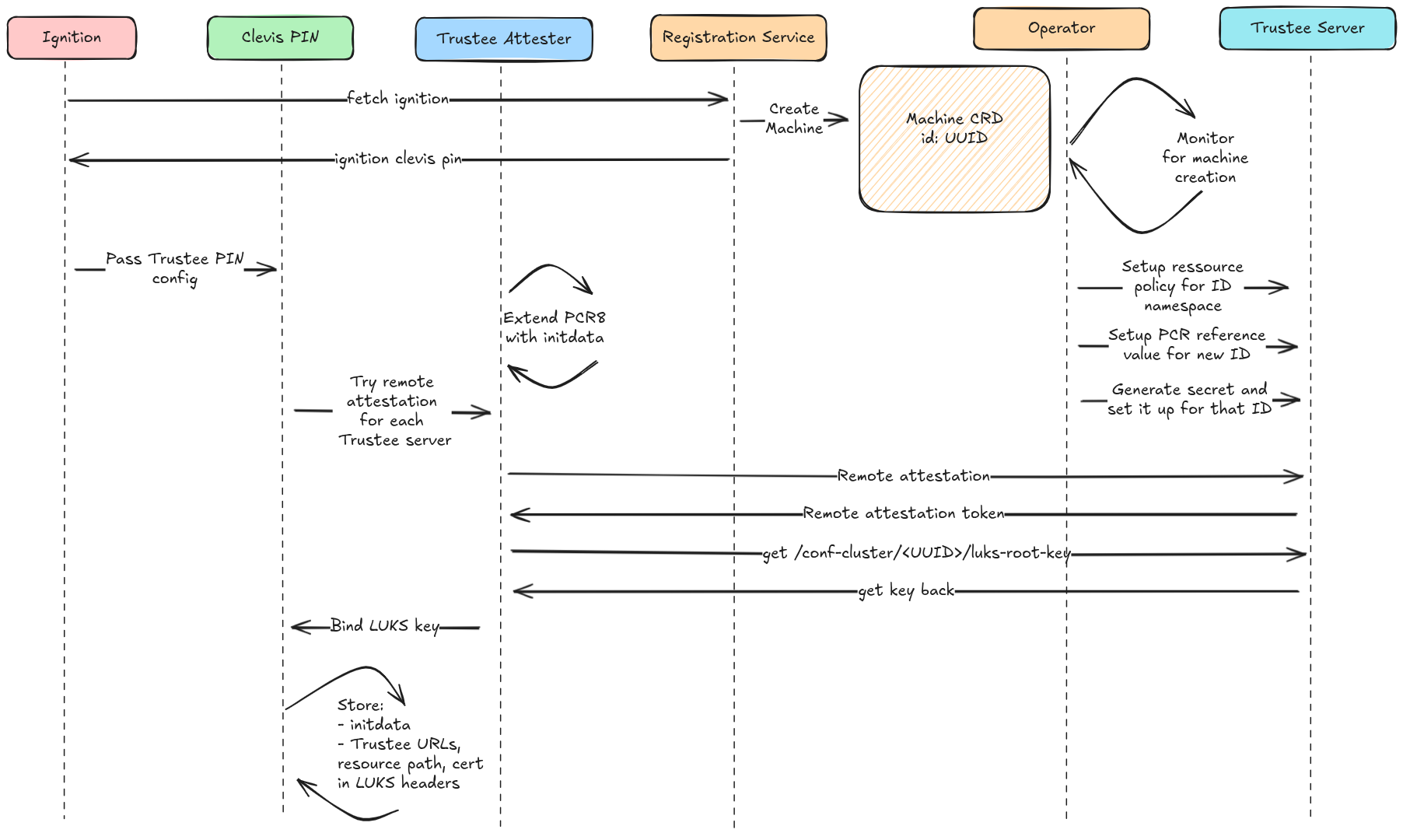
Next, let's examine the operator's configuration and the setup of its various node components.
Operator configuration
The TrustedExecutionClusterScustom resource definition (CRD) is the primary resource for configuring the operator. Its main role is to centralize configuration for attestation, secret distribution, and integration with services, such as the key broker service (KBS) and reference value provisioning service (RVPS).
The CRD, namespaced and versioned under trusted-execution-clusters.io/v1alpha1, exposes a single spec field, containing:
- trusteeImage: The image containing the trustee server which acts as attestation server.
- pcrsComputeImage: The image containing the library for computing the PCRs reference values.
- registerServerImage: The image containing the registration service with ignition.
- registerServerPort: The port for the registration service.
- publicTrusteeAddr: The address at which the trustee service is exposed and reachable by the nodes joining the cluster.
apiVersion: trusted-execution-clusters.io/v1alpha1
kind: TrustedExecutionCluster
metadata:
name: trusted-execution-cluster
namespace: trusted-execution-clusters
spec:
pcrsComputeImage: quay.io/trusted-execution-clusters/compute-pcrs:latest
registerServerImage: quay.io/trusted-execution-clusters/registration-server:latest
trusteeImage: quay.io/trusted-execution-clusters/key-broker-service:latest
publicTrusteeAddr: kbs-serviceNode components
The first boot is about provisioning and initial encryption of the root disk, while the second and all subsequent boots are about decryption for regular access. Both processes use attestation to ensure a trusted state and retrieve the LUKS key.
Clevis is a framework for automatically decrypting encrypted volumes at boot time, it comes with several built-in "pins," which are plugins for different decryption methods, but it also allows custom pins.
Ignition already supports the clevis framework and the pin specifications are included in the ignition configuration. During the initial boot, ignition executes the Clevis encryption command, binding it to the volume. Subsequently, on each boot, the Clevis pin performs the decryption of the disk.
As part of the trusted execution cluster deployments and Trustee, a new Clevis Pin for Trustee integrates seamlessly with Ignition to unlock the root disk. The new Pin initiates the attestation process. Upon successful attestation, it establishes a connection with the Trustee service, providing an attestation token to securely retrieve the required LUKS key. This LUKS key is then used by the Clevis pin to generate a JSON Web Token (JWT), which incorporates essential metadata that will be stored in the disk's LUKS header. Finally, the JWT encrypts the root disk, facilitating a hands-off, secure, and automated provisioning workflow.
The Trustee pin configuration includes:
- A list of the attestation servers.
- The path to retrieve the secret, consisting of three elements. The first and third elements are constant, while the second element, which is the node's UUID, changes for each node.
- The initdata are the extra data used to extend PCR 8 and included in the attestation report. This will distinguish the TCB for every node by including the UUID in the PCR measurements.
{
"servers": [
{
"url": "<attestation server url>",
"cert": ""
}
],
"path": "<repository>/<UUID>/<tag>",
"initdata": "{"uuid": "<UUID>"}"
}Attestation components
Remote attestation is the process of proving whether you can trust a system’s TCB. Each component and policy in the flow plays a role in deciding that trust and ultimately whether to release a secret.
The attestation policy specifies how Trustee verifies node integrity. The policy rules are written in the Rego language from the Open Policy Agent (OPA) project. The policy evaluates three main claims:
- Executables ensure runtime memory only contains verified executables, scripts, and files by checking the hashes of the PCR registers.
- Configuration confirms platform-level settings like SMT, TSME, ABI versions, and configuration.
- Hardware evaluates the hardware specification; but for now, this isn’t used on our policy.
A node's TEE measures bootloader, firmware, and kernel, storing measurements in TPM PCRs. The operator compares these against trusted values, granting access to secrets only if they match.
PCRs (Platform Configuration Registers) are append-only hash registers inside the TPM. They record the integrity of critical system components during boot. Currently in our policy, we focus on:
- PCR 4: Measures the components of the boot chain (shim, bootloader, UKI and UKI addons).
- PCR 7: Records platform configuration for secure boot.
- PCR 8: Includes the initdata used to configure the system.
- PCR 11: Tracks extended measurements for components of the UKI.
Attestation Rego policy:
default executables := 33 # unrecognized executables
default hardware := 97 # unrecognized hardware/firmware
default configuration := 36 # missing configuration elements
pcr8 = expected_pcrs8[input.initdata.uuid]
# Azure vTPM SNP evaluation
executables := 3 if {
input.azsnpvtpm.tpm.pcr4 in data.reference.snp_pcr04
input.azsnpvtpm.tpm.pcr7 in data.reference.snp_pcr07
input.azsnpvtpm.tpm.pcr11 in data.reference.snp_pcr11
input.azsnpvtpm.tpm.pcr8 == pcr8
}
hardware := 2 if {
input.azsnpvtpm.reported_tcb_bootloader in data.reference.tcb_bootloader
input.azsnpvtpm.reported_tcb_microcode in data.reference.tcb_microcode
}
configuration := 2 if {
input.azsnpvtpm.platform_smt_enabled in data.reference.smt_enabled
input.azsnpvtpm.policy_abi_major in data.reference.abi_major
}This attestation policy only takes into account Azure SNP TPM quote for sake of simplicity. However, you can append additional TEEs to the policy to support various environments and cloud providers.
A key detail is that each PCR value in the policy is actually a list of valid measurements, not a single value. This is important because a cluster may run multiple versions of the operating system, and each version will produce different PCR hashes. By allowing a list of acceptable values, the policy can validate nodes across updates.
In this design, we use PCR 8 to extend measurements of the initdata. Since the initdata is unique for every node, each one produces a different PCR 8 value. To keep track of this uniqueness, the policy embeds the node’s UUID in the initdata and uses it as an index. This ensures that you can identify each node individually and match it with its corresponding attestation and policy.
Reference values calculation
Attestation policy statements, such as input.azsnpvtpm.tpm.pcr4 in data.reference.snp_pcr04, require reference values to be useful. Before a node's first attestation request, the operator computes these values from the operating system’s bootable container image. This means that using bootable container images is mandatory, which is also the default on OpenShift.
Updates to the nodes in the cluster incur new bootable images. If such a container image has the org.coreos.pcrs label set, the operator will use the PCR values specified in it to provide the reference values. Doing so prevents the download of the image onto the operator’s node. You can compute these values at the image creation stage using the compute-pcrs library. If this label is not set, the operator instead uses compute-pcrs to compute the expected PCR values given the image's boot chain components (shim, bootloader, kernel) and updated initdata.
With future support for unified kernel image (UKI) in Red Hat Enterprise Linux CoreOS bootable containers images, the PCR4 measurements are extended to not only cover the kernel, but also the initrd and the kernel command line.
Resource policy
The resource policy acts as the gatekeeper, ensuring that only nodes presenting the right evidence and having the right properties are authorized to receive sensitive material.
For example, this snippet expresses a simple resource policy:
package policy
import rego.v1
default allow := false
uuid := split(input.resource_path, "/")[1]
allow if {
input["submods"]["cpu0"]["ear.status"] == "affirming"
input["submods"]["cpu0"]["ear.veraison.annotated-evidence"]["tpm"]
input.initdata.uuid = uuid
}In this resource policy, access is granted only if these three conditions are met: the attestation evidence must report an affirming state, the cpu includes the TPM in the attestation report, and the UUID embedded in the initdata must match the UUID of the requested secret. Just like the attestation policy, the resource policy relies on the UUID to uniquely identify the requesting node. This ensures that secrets are released only to the specific node they were provisioned for, preventing any other node from using the same evidence to obtain them.
Future steps
The design presented here represents the first iteration of a trusted execution cluster. While it establishes the basic trust flow and integration between attestation, ignition, and Trustee, we have planned several refinements for upcoming versions. You can follow the latest updates in the operator repository.
The following sections describe a few areas of ongoing work we will explore in future articles.
Node bootstrapping
The bootstrap node initiates the cluster, deploying the control plane and critical components using ignition for OS provisioning and initial manifests. Unlike other nodes, it relies on an external Trustee service for initial attestation and secrets to validate its TEE and begin onboarding. Once verified, it deploys the operator and propagates policies/secrets to subsequent nodes.
Cluster API and node lifecycle management
Cluster API (CAPI) is a Kubernetes project that provides declarative APIs for provisioning and managing machines across different cloud providers. In the current design, the machine object used for trusted execution clusters is completely decoupled from the CAPI machine object that represents the actual machine. Aligning these two will simplify node lifecycle management.
The initial design only considers the moment when a machine registers itself, but nodes naturally go through other lifecycle events. For example, a node might be deleted. In that case, the operator must detect the deletion, remove the associated secret, and update the corresponding policies to keep the cluster state consistent and secure. It should also be possible for administrators to revoke previously allowed bootable images to prohibit vulnerable ones.
Protecting the ignition configuration
In the current design, the registration service exposes an open endpoint that any node can contact to request its ignition configuration. This also introduces security risks because untrusted nodes could pollute the policy set or consume secrets unnecessarily.
To address this, we can strengthen the registration phase with an additional attestation step. Before receiving its UUID-specific ignition configuration, a node must first attest with its general TCB state (evidence about the platform and firmware, but without the UUID). Only after this baseline attestation succeeds is the registration service allowed to release the ignition configuration containing the node’s UUID. This ensures that only nodes presenting a valid TCB are able to register and proceed to full attestation and secret provisioning.
Targeting Trustee raw TPM attester/verifier and GCP
The operator currently relies on Azure virtual TPM for attestation, specifically using its trustee attester and verifier. The next release of the operator will expand this capability by incorporating generic vTPM support, enabling its application across various cloud providers that offer confidential VMs equipped with a TPM.
Final thoughts
In this article, we described the confidential cluster operator design and flow. We defined its role in deploying and managing confidential Kubernetes clusters.
The current design of the trusted execution cluster operator's registration service has a security vulnerability because its open endpoint allows any node to request an ignition configuration, which could lead to policy pollution or unnecessary secret consumption. To mitigate this, introducing a baseline attestation step strengthens the registration phase. In this enhanced process, a node must first attest with its general Trusted Computing Base (TCB) state—evidence about the platform and firmware, but without its unique UUID—before the registration service releases the UUID-specific ignition configuration. This change ensures that only nodes presenting a valid TCB are able to register and proceed to full attestation and secret provisioning. Future work also includes expanding attestation support beyond Azure vTPM to generic vTPM for cloud providers like GCP.
