This post is a practical, end-to-end guide to running hundreds to thousands of machine learning models without chaos. It assumes you already know what your models do; the focus here is how to operate them at scale with consistency, traceability, and security.
We'll show how to turn the model lifecycle into an assembly line (define → train → package → deploy → monitor → retrain) using configuration-driven pipelines, versioned artifacts, and GitOps promotion. The goal isn't any specific vendor stack; it's a set of repeatable patterns you can re-create with cloud-native, open tools.
What you'll get in this deep dive:
- A repository (repo) layout across five GitHub repositories (models, pipelines, training pipelines, data, deployment), showcasing a working example.
- Continuous training that reacts to config or data changes and produces immutable, scannable model artifacts ("ModelCars").
- Versioned AI training pipelines, so different models can be linked to different pipeline versions.
- Data lineage with dataset versioning for reproducibility and audits.
- GitOps deployments: Automatic test deploys and PR-gated promotion to production.
By the end, you'll know exactly how these pieces fit together and how to adapt this pattern to your environment.
For more high-level details on the problem and solution, read part 1 of this two-part blog series.
And if you prefer something more visual, you can see a full walkthrough and demo on YouTube: The MLOps Challenge: Scaling from One Model to Thousands
An assembly line for models
To tackle the challenges of scaling machine learning, we need more than ad-hoc scripts and manual processes. We need a systematic, automated, and transparent approach that treats pipelines and models as first-class citizens.
Here's what that looks like:
- A simple interface for data scientists. Models are defined through lightweight configuration files and Python training pipelines—no Kubernetes deep dives required.
- Pipelines as first-class citizens. Every model is built and deployed through a pipeline, ensuring consistency and repeatability.
- Versioned training pipelines as custom resources. Each change to a training pipeline is captured as a versioned resource, so we always know what ran, when, and why.
- Training pipeline CI/CD. Automated workflows ensure every training pipeline change is tested, validated, and deployed correctly.
- Continuous training. Trigger the right training pipeline with the right version whenever new data or configurations arrive.
- Built-in governance. Models are scanned, container images are validated, and metadata is pushed to a model registry.
- Model registry as a single source of truth. This gives full transparency and traceability across the entire fleet of models.
- Data versioning for lineage. Every dataset used for training is versioned, making experiments reproducible and auditable.
- Safe, automated deployments. Test deployments happen automatically for quick validation. Production deployments require a pull request and human approval where keeping people in the loop matters.
- Models as containers (a.k.a. "ModelCars"). Each model is packaged as an immutable OCI-compliant artifact, enabling consistent deployment, traceability, and security scanning.
This approach transforms the messy, manual process of managing models into a streamlined assembly line: define → train → package → deploy → monitor → retrain.
This way, we can keep adding pipelines and models, resulting in a system that scales from one model to thousands without losing control, visibility, or compliance.
Technical architecture: Repos and responsibilities
Now that we've given some background on what we want to do, let's look at the technical flow that makes it all work.
At a high level, the system is built from a set of specialized components working together.
We divided it up into 5 different GitHub repositories:
- Model configurations (nine-thousand-models)
- Pipelines (nine-thousand-pipeline)
- Training pipelines (nine-thousand-kfp)
- Data management (nine-thousand-data)
- Deployment (nine-thousand-models-gitops)
You can find them all under the nine-thousand-models GitHub organization.
Let's go through them and see what each one does and how they interact with our environment.
Model configurations
This is where the model configurations are stored.
They identify what data the model should use for training, what pipeline should be used to train it, which parameters we send into the pipeline, and what runtime it should be served with.
Here's a small example JSON file:
{
"data_source": {
"type": "dvc",
"dataset": "datasets/churn-predictor/data.parquet",
"repo_url": "https://github.com/nine-thousand-models/nine-thousand-data",
"dvc_hash": "5c2145f3f900c69fb20c0af2657b7876"
},
"model_name": "churn-predictor-model",
"kubeflow_pipeline": "classification-training-pipeline",
"kubeflow_pipeline_version": "classification-training-pipeline-v1.23.0",
"runtime_name": "tensorflow",
"model_hyperparameters": {
"epochs": 1
}
}Even though this is a small example, you can see how to extend this approach to gain more flexibility. By adding or adjusting hyperparameters in the JSON file, we can reuse the same training pipeline for many different models with different behaviors or performance characteristics. This also makes it simple for data scientists to define new models or update existing ones whenever needed.
Pipelines
In this repo, we define the pipelines that glue everything together.
Continuous training pipeline
The continuous training pipeline kicks off our individual training pipelines, scans and packages the model, and ensures the metadata is updated to reflect the changes (see Figure 1). We set this pipeline to trigger automatically on any change to our model JSON files, but you can also trigger it on other events or based on a schedule.

And to make this concrete, Figure 2 shows the Tekton tasks that implement this workflow.

After the continuous training pipeline finishes, we will have a newly trained model packaged as a ModelCar and served in our test environment, a pull request (PR) that promotes that model into our production environment, and an entry in our model registry that reflects this new model version (Figure 3).

Training pipeline CD pipeline
The training pipeline CD pipeline compiles and deploys new versions of the individual training pipelines so that they are ready to be executed by the continuous training pipeline. See Figure 4.

The training pipeline versions that this pipeline deploys are the ones we were referring to in the sample model JSON. This allows us to keep different models training on different versions of our training pipelines.
Data pipeline
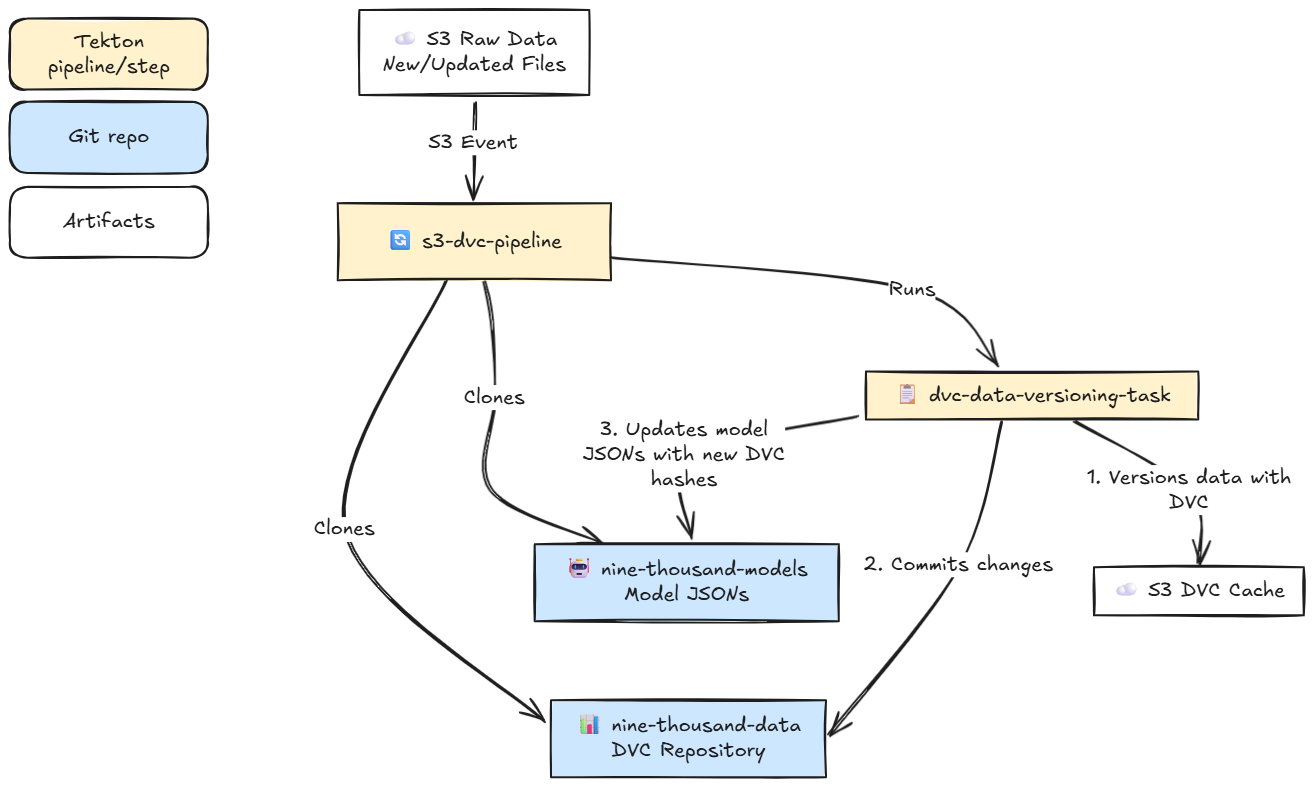
We added a data pipeline just to showcase how data versioning could be managed. This is a small pipeline that detects when new data comes in, versions it through DVC (Data Version Control), and updates our data repository (which just stores the DVC files; see Figure 5) . It also updates our model repository for the models associated with the specific data that was updated—and we now know what happens when we update a model JSON. 😉We will get a new model trained on the new data specified in that JSON file.
Training pipeline
The training pipeline is where we store our individual training pipelines. In our case, these are Kubeflow pipelines that are built in Python so it's easy for a data scientist or machine learning engineer to create new ones or modify existing ones.
These are the pipelines that execute the actual machine learning (ML) flow: fetch data, preprocess, train, evaluate, validate, and register models.
These pipelines can be defined based on what kind of training steps you want to take. Ours looks like Figure 6.

Data management
The data management repo simply holds our Data Version Control (DVC) information. If you don't use DVC, you might not need this repo.
Deployment
We use Argo CD to automatically deploy our models, keeping the cluster synced with this GitOps repo.
It contains YAML files for our model serving configurations in test and production (in two separate folders), which look something like this:
chart_path: charts/model-deployment/simple
name: anomaly-detector
image_repository: image-registry.openshift-image-registry.svc:5000
image_namespace: fika-test
version: f7844fe3d7
The interesting part here is the version, f7844fe3d7, which points out which ModelCar we should serve as our model.
These connect together in a seamless flow, where all the data scientist/ML engineer needs to interact with are:
- The training pipelines repository, to build new pipelines or update existing ones.
The models repository, to quickly modify or train new models.
Note: We chose these tools because they are open, cloud-native, and fit well into our Red Hat OpenShift AI platform. But the real point isn't which tools you use, it's the principles.
Want to see it in action? Check out this video where we show the full technical implementation in a live demo.
Additional enhancements
The preceding flow showcases how you can scale from a single model to many, but there are a few bells and whistles you might want to consider adding on.
Trigger retraining on monitoring
We haven't covered monitoring much in the flow above; it has been more about getting models deployed. However, you'll also need to add monitoring to properly maintain your models.
Something that can be useful to monitor are model metrics such as drift, so you know if what the model is trained on matches up with what you are seeing in the real world.
This also allows you to trigger retraining based on these metrics, as an alternative to retraining only when new data comes in or the model configuration changes.
Schedule training jobs
Rather than just running the training code inside a pipeline step, you can execute a training job that can be scheduled for when resources are available.
This allows for more optimal sharing of resources.
Batch processing
In this example, we showcase how you can serve and maintain multiple models at scale.
Instead of just serving the models, you can also run batch job pipelines that process the data and save it somewhere without serving the model.
The general flow would mostly stay the same; you would just have another pipeline that fetches the model, data, and then saves it.
Infra scaling
When growing to a very large scale, you will need to start thinking about scaling your infrastructure as well.
This can come in the form of autoscaling machines or scaling across multiple clusters, using technologies such as Red Hat Advanced Cluster Management, which is part of OpenShift Platform Plus.
How to onboard this in practice
You likely won't go from 0 to a full system in a day; it will be a progression. Here are steps that can guide you through that process.
Step 1: Prove it with one model.
- Pick one use case (for example,
demand-forecaster). - Build the training pipeline end-to-end.
- Automate retraining with new data.
Step 2: Generalize the flow.
- Make pipelines reusable (config-driven).
- Standardize data versioning and packaging.
- Apply GitOps for safe deployments.
Step 3: Scale in iterations.
- Add more models, one category at a time.
- Reuse the same "assembly line" for each.
- Continuously refine monitoring and retraining.
Step 4: Manage the fleet.
- Hundreds to thousands of models.
- Event-driven retraining.
- Centralized governance, lineage, and security.
Wrap-up: Turning the factory lights on
If part 1 was the blueprint, this deep dive is powering up the factory floor. With config-driven models, versioned pipelines, continuous training, and GitOps promotion, every model rolls off the line as a scannable, traceable ModelCar.
The results:
- Speed: New models are a config change.
- Safety: Scanned, signed, PR-gated.
- Sightlines: Lineage from data to deploymen.)
You don't need to bet on a monolithic platform or perfect tooling. Start with one model, wire up the conveyor belts, and let the system do the heavy lifting. As your catalog grows from dozens to thousands, the process stays the same; only the throughput increases.
To go even deeper and hands-on implement a system such as this one, check out the 5-day enablement training course MLOps Enablement with OpenShift AI.