The frontier of AI is no longer just in the data center; it's on the factory floor, in our retail stores, in public infrastructure, and in the smart devices all around us. Driving this shift are vision language models (VLMs), a revolutionary class of AI that can interpret and reason about images and videos. The potential is immense, but any developer who has tried to deploy these models at the edge knows the harsh reality: it's a battle against dependency hell, driver incompatibilities, and inconsistent environments.
What if you could bypass that complexity entirely? What if deploying a VLM was as simple as ramalama run?
Enter RamaLama, an open source command-line interface (CLI) designed to make working with AI models "boring" by handling the hard parts for you. It leverages container engines like Podman and Docker to abstract away hardware and software dependencies, providing an isolated and repeatable environment for your models with a stronger security posture.
In this article, we'll show you how to leverage RamaLama to deploy powerful multimodal AI models on your edge devices. We will cover everything from pulling your first VLM, to serving it via an API, and turning a once-daunting task into a manageable and efficient workflow.
Vision language models for the edge
For years, the most powerful artificial intelligence lived in the cloud, accessible only through an internet connection. But a new frontier is rapidly emerging: the edge. Imagine a smart camera that doesn't just record video but describes what it sees in real-time, an offline industrial scanner that identifies product defects, or a device that can help identify threats and hazards in public infrastructure and raise the appropriate warnings. This is the promise of vision language models: AI that can see, understand, and communicate information about the world.
Bringing this capability to local, resource-constrained edge devices has traditionally been a challenge, fraught with complex dependencies, hardware-specific configurations, and deployment nightmares. RamaLama simplifies the process by embracing a container-native philosophy, making the process of deploying sophisticated VLMs as straightforward and reliable as running a container on the edge device.
The RamaLama architecture: Simplicity through containerization
At its core, RamaLama's architecture is built on a simple premise: “Treat AI models with the same robust, portable, and isolated approach that containers brought to software applications.”
Instead of requiring users to manually configure complex environments with specific GPU drivers, Python libraries, and model dependencies, RamaLama abstracts this entire process away. It acts as an intelligent orchestrator that sits between the user and a container engine like Podman or Docker. When a user issues a command like ramalama run, the tool first inspects the host system to detect available hardware. It then automatically determines whether to use a CPU or a specific type of GPU (like NVIDIA via CUDA, AMD via ROCm, or an Intel GPU).
Based on this hardware detection, RamaLama's key architectural function comes into play: it selects and pulls a pre-configured OCI (Open Container Initiative) container image specifically optimized for that environment. These images, stored in registries like Quay.io, contain all the necessary system libraries, drivers, and runtimes (such as llama.cpp or vLLM) needed to execute the AI model efficiently. The user's chosen model, pulled from a source like Hugging Face or Ollama, is then mounted into this container. (See Figure 1.) This elegant design means the user's machine stays clean, and the model runs in a more consistent, reproducible environment, effectively eliminating the "it works on my machine" problem for AI.
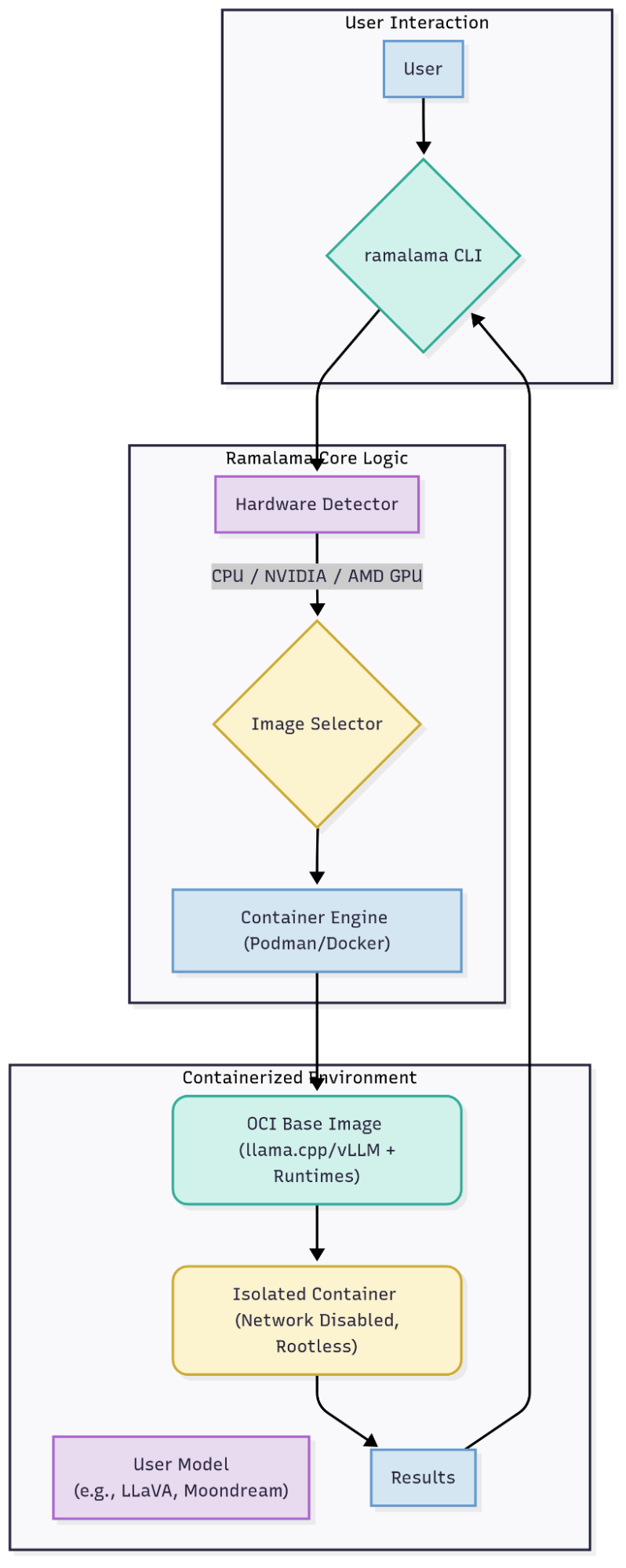
By default, RamaLama runs models inside rootless containers, which provides crucial isolation from the host system. Furthermore, it applies a stringent security policy out of the box: the AI model is mounted as a read-only volume, preventing any potential modification of the host's file system. Critically, containers are run with networking disabled (--network=none), blocking any unauthorized communication and severely limiting the potential for leaks of the sensitive data processed by the model. This multi-layered, security-first approach allows developers to experiment with and serve a wide variety of models from the community with a significantly reduced risk profile.
Deploying Qwen vision language models using RamaLama
We will now walk through deploying the Qwen2.5VL-3B VLM on a local workstation using RamaLama. The major steps are as follows:
- Install RamaLama on your platform.
- Pull the qwen2.5vl:3b model from Hugging Face.
- Serve the VLM on the local system to expose an OpenAI-compliant REST API endpoint for applications.
- Test the VLM inference using images and videos.
Prerequisites
Before you begin, ensure you have the following prerequisites in place:
- Install Podman (recommended) or Docker.
- Create a Hugging Face account to download private LLMs that require a token. Set your token as the value for the HF_TOKEN environment variable for your system (for example, by setting it in
~/.bashrcor~/.zshrc). - Install RamaLama.
- Run
ramalama infoto verify that theramalamaCLI is correctly installed. You should see various details about your environment and no errors. - Clone the code and test files from the GitHub repository at https://github.com/rsriniva/ramalama-edge to your local system.
Pull the Qwen2.5 VLM from Hugging Face
Download the qwen2.5vl:3b model from Hugging Face as follows.
ramalama pull qwen2.5vl:3bVerify the model has been downloaded and is stored locally:
ramalama ls
NAME MODIFIED SIZE
hf://ggml-org/Qwen2.5-VL-3B-Instruct-GGUF 23 hours ago 2.58 GBServe the VLM on the local system
To expose the VLM as a callable REST API endpoint (on port 8081), use the ramalama serve command.
ramalama serve --port 8081 qwen2.5vl:3b
ggml_vulkan: Found 1 Vulkan devices:
ggml_vulkan: 0 = Virtio-GPU Venus (Apple M1 Pro) (venus)
...
main: HTTP server is listening, hostname: 0.0.0.0, port: 8081, http threads: 4
main: loading model
srv load_model: loading model '/mnt/models/Qwen2.5-VL-3B-Instruct-Q4_K_M.gguf'
...
main: server is listening on http://0.0.0.0:8081 - starting the main loop
srv update_slots: all slots are idleNote: You can start multiple instances of the VLM or other LLMs and serve them on a different port as long as you have the CPU, memory, and GPU capacity on your system. Each instance will run in its own container.
List the models that are running on your system:
ramalama ps
CONTAINER ID IMAGE PORTS
0685b116a10c quay.io/ramalama/ramalama:latest 0.0.0.0:8081->8081/tcpTest the VLM using the built-in web UI
RamaLama comes with a built-in, simple chat web UI that you can use to interact with the model:
- Navigate to http://localhost:8081 with a web browser.
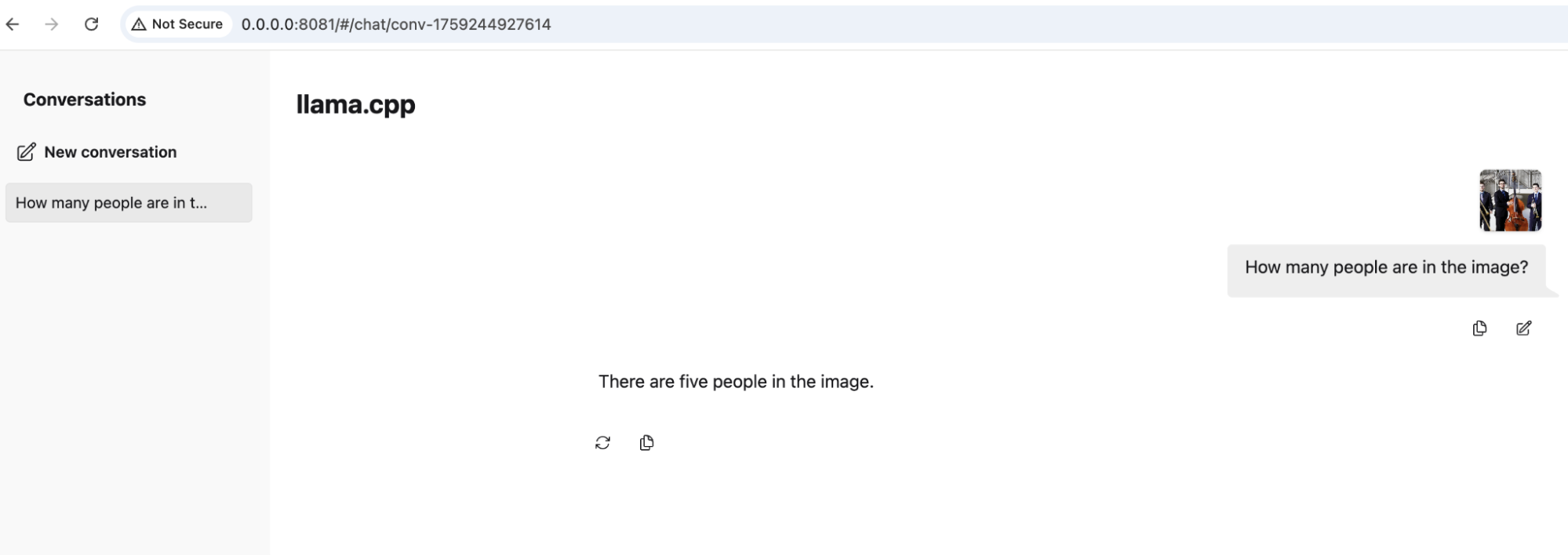
- Click the attachment icon at the bottom of the web UI next to the chat box and upload the jazz-quintet.jpg file from the folder where you cloned the test code and files from GitHub.
- You can now ask questions to the VLM about the image. Try entering
How many people are in the image?to prompt a response from the VLM (Figure 2).
- Ask a follow-up question like
What is the person in the center of the image holding?and inspect the response from the VLM. Because we are using a smaller quantized model, the results might not be fully accurate, but should be close to the actual answer you expect. Using larger, non-quantized models will result in better results.
Communicate with the VLM from applications
In real-world scenarios, you will invoke the VLM using the RamaLama-provided REST API (which is OpenAI-compliant) from applications that reside on or near the edge device.
Inspect the Python script image_analyze.py in the Git repository. This script uses the OpenAI client and sends the image to the VLM for analysis. A real-world use case is a camera or image capture device that sends images to the VLM for analysis.
To run the script, you first need to create a Python virtual environment in the same folder and activate it:
python -m venv venv
source venv/bin/activate
(venv)Next, install the dependencies required for the script to run. A requirements.txt file listing all the dependencies is provided for you.
(venv) pip install -r requirements.txtInspect the script and change the IMAGE_FILE and PROMPT variable as needed. You can now run the image_analyze.py script.
(venv) python image_analyze.py
Querying local model served by RamaLama...
Prompt: How many people are in this image?
Response from model:
There are five people in the image.You can provide your own images and change the PROMPT variable with the query you want to send to the VLM.
You can pull and serve other VLMs, and perform your own tests before deploying your application to production. RamaLama makes it easy to experiment with different models with minimal code changes, and once testing is complete, you can deploy the models to a Kubernetes or OpenShift cluster using RamaLama-generated YAML artifacts.
Test with videos
You can also analyze video streams using the same setup. Inspect the video_analyze.py script in the same folder. A sample video file in MP4 format is provided in the same folder. To process the video file, we take image snapshots of the video in 7-second intervals using the OpenCV library, and send the stream of images to the VLM for analysis.
Note: The snapshot intervals are customizable and depend on the length of the video and the hardware capacity backing the VLM. Because we are testing this on our local systems, we use a modest 30-second video and take 7 snapshots at 7-second intervals.
Run the video_analyze.py script:
(venv) python video_analyze.py
Extracting frames from 'classroom.mp4' every 7 seconds...
Successfully extracted 5 frames.
Sending frames to the VLM for analysis...
====================
Video Analysis Summary
====================
In the video, there are four individuals seated at desks in a classroom or meeting room. The person on the far right, who appears to be the last in the sequence, is standing up and leaning towards the table, then turning and walking away. The other three individuals remain seated, with their body language indicating they are engaged in the conversation or activity. The person on the far right also interacts with the individual next to him, possibly discussing something or gesturing with their hands.You can debug the script by checking the output in the terminal where you started the VLM. You should see the communication between the client and the VLM and see some basic statistics about the inference printed on the console.
srv log_server_r: request: POST /v1/chat/completions 192.168.127.1 200
srv params_from_: Chat format: Content-only
slot launch_slot_: id 0 | task 49 | processing task
...
srv process_chun: processing image...
srv process_chun: image processed in 9983 ms
slot update_slots: id 0 | task 49 | prompt processing progress, n_past = 51, n_tokens = 3, progress = 0.727273
slot update_slots: id 0 | task 49 | kv cache rm [51, end)
srv process_chun: processing image...
srv process_chun: image processed in 11417 ms
slot update_slots: id 0 | task 49 | prompt processing progress, n_past = 55, n_tokens = 3, progress = 0.787879
slot update_slots: id 0 | task 49 | kv cache rm [55, end)
srv process_chun: processing image...
srv process_chun: image processed in 12865 ms
slot update_slots: id 0 | task 49 | prompt processing progress, n_past = 59, n_tokens = 3, progress = 0.848485
slot update_slots: id 0 | task 49 | kv cache rm [59, end)
srv process_chun: processing image...
srv process_chun: image processed in 14268 ms
slot update_slots: id 0 | task 49 | prompt processing progress, n_past = 66, n_tokens = 6, progress = 0.954545
srv log_server_r: request: POST /v1/chat/completions 192.168.127.1 500
srv update_slots: all slots are idle
srv params_from_: Chat format: Content-only
slot launch_slot_: id 0 | task 208 | processing task
slot update_slots: id 0 | task 208 | new prompt, n_ctx_slot = 4096, n_keep = 0, n_prompt_tokens = 66
slot update_slots: id 0 | task 208 | need to evaluate at least 1 token for each active slot, n_past = 66, n_prompt_tokens = 66
slot update_slots: id 0 | task 208 | kv cache rm [65, end)
slot update_slots: id 0 | task 208 | prompt processing progress, n_past = 66, n_tokens = 1, progress = 0.015152
slot update_slots: id 0 | task 208 | prompt done, n_past = 66, n_tokens = 1
slot release: id 0 | task 208 | stop processing: n_past = 162, truncated = 0
slot print_timing: id 0 | task 208 |
prompt eval time = 72.13 ms / 1 tokens ( 72.13 ms per token, 13.86 tokens per second)
eval time = 5809.82 ms / 97 tokens ( 59.90 ms per token, 16.70 tokens per second)
total time = 5881.95 ms / 98 tokens
srv update_slots: all slots are idle
srv log_server_r: request: POST /v1/chat/completions 192.168.127.1 200Further reading
- RamaLama website
- How RamaLama runs AI models in isolation by default
- How to run OpenAI's gpt-oss models locally with RamaLama
- Unleashing multimodal magic with RamaLama
- How RamaLama makes working with AI models boring
- Supercharging AI isolation: microVMs with RamaLama & libkrun
- Simplify AI data integration with RamaLama and RAG
- Simplifying AI with RamaLama and llama-run
- Podman AI Lab and RamaLama unite for easier local AI
- How to run AI models in cloud development environments
Acknowledgements
This article was created with assistance from Daniel Walsh and Michael Engel.