OpenVINO is a toolkit developed by Intel for deploying and optimizing AI models across various hardware platforms. At its core, model serving involves three main components: the model to deploy, an inference runtime and a model server.OpenVINO in this context is the runtime that supports multiple types of model, while OpenVINO Model Server (OVMS) is built on top of the runtime, designed to streamline the deployment and management of deep learning models in production environments by leveraging these two key components.
Model-serving engines like OVMS facilitate the deployment and management of models, abstracting hardware-specific complexities and enabling seamless integration with existing infrastructure(i.e. providing metrics). Inferencing runtimes are responsible for executing inference requests in real time, and making decisions based on incoming data. Together, they form a robust framework for efficient and scalable AI deployment.
Key features
- Simplified model deployment: OVMS provides a streamlined process for deploying deep learning models, abstracting away hardware-specific complexities and enabling easy integration with existing infrastructure.
- Scalability: OVMS is designed to handle varying inference workloads efficiently, allowing seamless scaling across multiple hardware devices such as CPUs, GPUs, FPGAs, and VPUs.
- Flexibility: OVMS supports a wide range of deep learning frameworks, including TensorFlow, PyTorch, Caffe, vLLM, and ONNX. It also accommodates various model formats such as TensorFlow SavedModel, ONNX, and OpenVINO Intermediate Representation.
- Monitoring and management: OVMS includes tools and features for monitoring model performance, resource utilization, and server health. This enables administrators to optimize system performance and troubleshoot issues effectively.
Architecture overview
OpenVINO Model Server includes multiple components, including an inference engine and hardware abstraction layer. It interacts with the client application via API protocols and uses an internal model registry to pull the models from storage. These components work together to ensure efficient model deployment, execution, and management. See Figure 1 for an illustration of this.
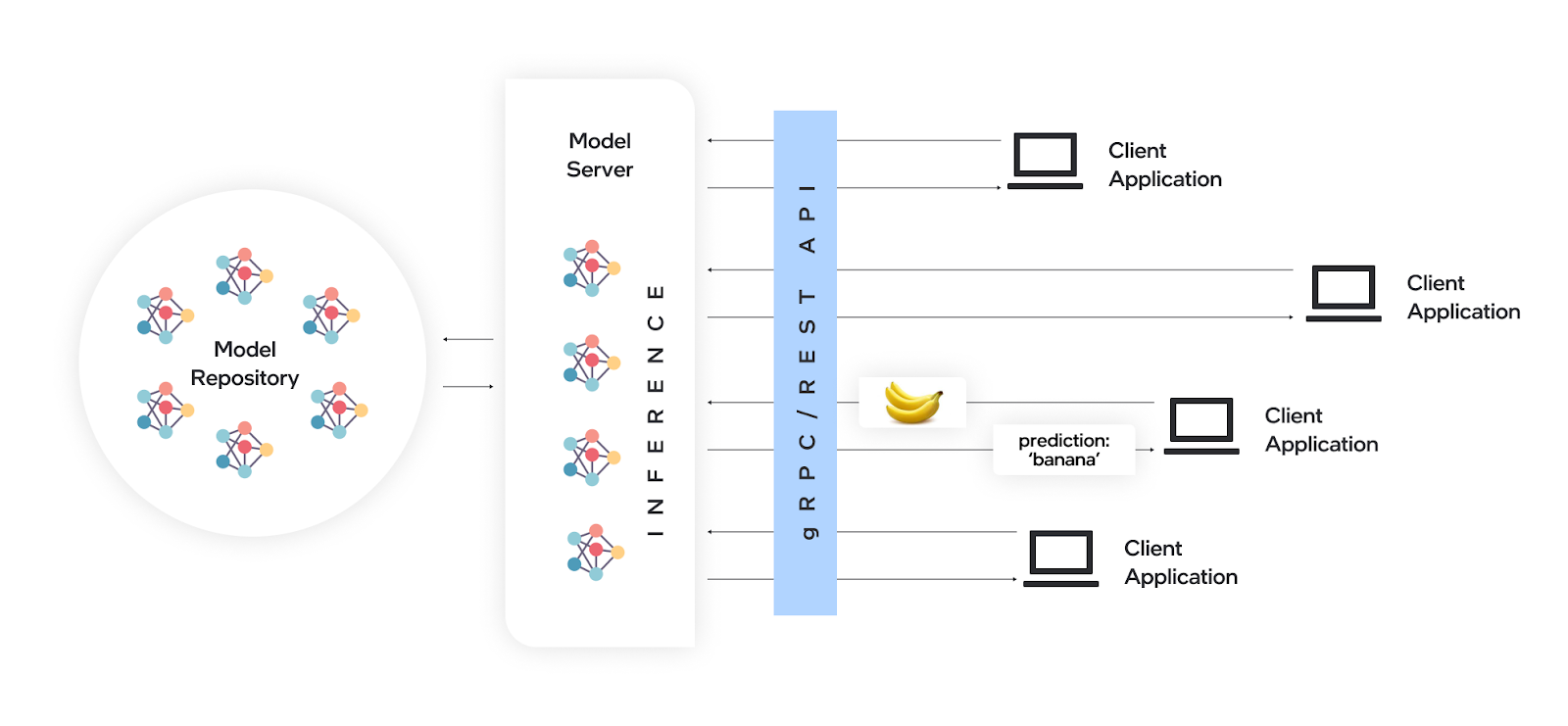
The components of OVMS include:
- Client-server interaction: Clients communicate with the OVMS server via RESTful APIs or gRPC protocols. Clients send inference requests containing input data to the server, which processes the requests using loaded models and returns the inference results.
- Model repository: The "model repository" format refers to a specific directory layout that helps in managing model versions and dependencies efficiently. The Model Loader component is responsible for loading deep learning models into memory from a model repository on various storage sources such as local filesystems or remote repositories like S3-compatible storage.
- Inference: The Inference Engine executes inference requests on loaded models, utilizing hardware accelerators when available to optimize performance. It can also split a model between the accelerator and the CPU in some cases. The Inference Engine handles data preprocessing, model execution, and post-processing tasks.
- Hardware abstraction: OVMS abstracts hardware-specific details, allowing models to be deployed seamlessly across heterogeneous hardware platforms. This ensures portability and interoperability across different environments.
Model conversion to OpenVINO intermediate representation
Preparing models for serving with OpenVINO involves a two-step process. First, the models are converted into an OpenVINO format optimized and sized for specific hardware types. Then, the models are loaded into the OVMS model server.
- Conversion process: Models trained in various frameworks such as TensorFlow, PyTorch, and ONNX are first converted to the OpenVINO Intermediate Representation (IR) format using the OpenVINO Model Optimizer. The Model Optimizer uses various techniques to provide better performance and efficiency. This process includes steps like model quantization, optimization, and transformation to ensure compatibility with OpenVINO.
- Loading IR models: Once converted, the OpenVINO IR models are loaded into OVMS. This enables the models to be deployed efficiently across different hardware platforms supported by OpenVINO.
Supported frameworks and models
OpenVINO Model Server supports a wide range of deep learning frameworks and model formats, enabling seamless deployment and integration.
- Deep learning frameworks: OVMS supports popular deep learning frameworks including TensorFlow, PyTorch, Caffe, and ONNX. This broad compatibility enables users to deploy models trained in their preferred framework without conversion or modification.
- Model formats: OpenVino Model Server supports multiple model formats such as TensorFlow SavedModel, ONNX, and OpenVINO Intermediate Representation.
- TensorFlow SavedModel: This format is ideal for complex models that require TensorFlow-specific features and integrations. It is commonly used for workloads involving large-scale image and text processing tasks.
- ONNX: The Open Neural Network Exchange (ONNX) format is best suited for interoperability between different deep learning frameworks. It is particularly useful for models that need to be trained in one framework and deployed in another, offering flexibility for various machine-learning tasks.
- OpenVINO Intermediate Representation (IR): This format is optimized for Intel hardware, making it the best choice for performance-critical applications, such as real-time inference on edge devices or high-throughput inference on servers.
Deployment scenarios
OpenVINO Model Server offers significant flexibility by supporting deployment across various hardware footprints. This adaptability enables OVMS to address diverse use cases and environments, ensuring optimal performance and efficiency. The deployment options include:
- On-premise deployment: OVMS can be deployed in on-premise data centers, providing local inference capabilities with low latency and high throughput using the cloud-native KServe v2 serving APIs.
- Cloud deployment: OVMS is cloud-ready and can be deployed on major cloud platforms such as AWS, Azure, and GCP. Cloud deployment offers scalability, elasticity, and ease of management, making it suitable for handling large-scale inference workloads.
- Edge deployment: OVMS can be deployed on edge devices such as IoT gateways, edge servers, and embedded systems. Edge deployment enables inference at the point of data collection, reducing latency and bandwidth usage while preserving data privacy and security.
Performance and optimization
OpenVINO provides various optimization techniques to enhance model performance and efficiency. These include model quantization, which reduces model size and computational complexity. OVMS further improves throughput by implementing batch processing, which allows the server to process multiple inference requests simultaneously.
Automatic batching:
- Aggregates multiple inference requests into batches.
- Reduces overhead by processing requests in bulk.
- Enhances throughput and resource utilization.
Asynchronous API:
- Enables non-blocking execution of inference requests.
- Allows concurrent handling of multiple requests.
- Improves responsiveness and throughput.
Number of wired streams:
- Determines concurrent data streams for efficient data transfer.
- Minimizes latency and maximizes bandwidth utilization.
- Requires tuning based on network and hardware constraints.
CPU pinning and CPU affinity:
- Assigns specific CPU cores to dedicated tasks.
- Prevents core migration, reducing overhead.
- Improves stability and predictability of CPU-bound workloads.
Benchmarking: OpenVino Model Server performance benchmarks demonstrate its efficiency and scalability across different hardware platforms and inference workloads.
Security considerations
Ensuring the security of models and data is crucial when deploying AI solutions. OpenVINO Model Server incorporates several security measures to protect sensitive information and maintain the integrity of its operations.
- Authentication and authorization: OpenVINO Model Server supports multiple cloud-hosted storage options to provide authentication and authorization mechanisms to secure access to its APIs and resources. Users can control access permissions and enforce security policies to protect sensitive data and models.
- Model security: OVMS includes features for ensuring model security, such as encryption, access control, and tamper detection. These measures safeguard intellectual property and prevent unauthorized access or manipulation of models. Many S3-compatible solutions use SSL-based encryption which can protect models being loaded onto instances of the model server. Additionally, OVMS provides sample code to implement a full TLS handshake for HTTPS encryption between clients and the model server.
Integration and extensibility
APIs and SDKs: OVMS offers APIs and SDKs for integrating with custom applications and frameworks. These interfaces enable seamless integration of OVMS into existing workflows and environments, allowing users to leverage its capabilities without disrupting their development processes.
Custom plugins: OVMS supports custom plugins for extending its functionality and integrating with specialized hardware or software components. Users can develop and deploy custom plugins to meet specific requirements or optimize performance for their use cases.
OpenShift AI integration with OpenVINO and KServe
Red Hat OpenShift AI is an integrated MLOps platform for building, training, deploying, and monitoring predictive and gen AI models at scale across hybrid cloud environments. OpenShift AI uses KServe, a flexible machine learning model serving framework, to serve and support multiple generative AI inference runtimes. OpenShift AI also includes OpenVINO Model Server as one of the serving engines and formats supported.
How do OpenShift AI users benefit from OpenVINO?
OpenShift AI users can significantly enhance their AI/ML workflows by integrating OpenVINO for optimized model performance and KServe for scalable model serving. This combination provides flexibility, efficiency, and comprehensive monitoring capabilities.
Workflow with KServe and OpenVINO
To illustrate this integration, below is diagram and detailed explanation of the workflow (Figure 2).
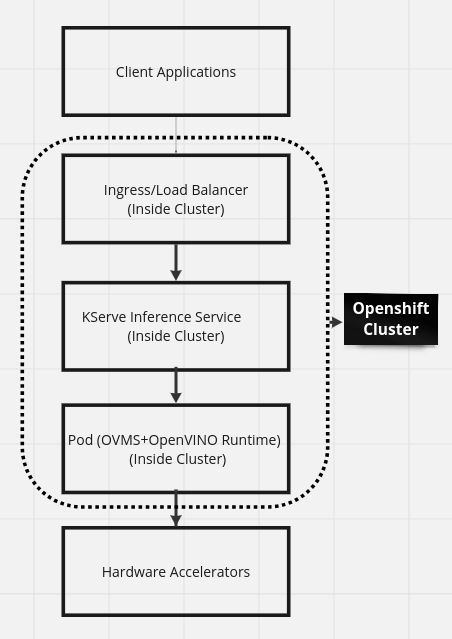
Client applications: Users interact with client applications (web/mobile apps) that send inference requests.
Ingress/Load balancer: Manages traffic to KServe endpoints.
OpenShift Kubernetes cluster: Manages container orchestration, scaling, and resource management.
KServe Inference Service: Handles inference requests and provides metrics.
KServe controller: Manages model deployments, scaling, and routing.
Model serving pods: Run on OpenShift nodes, scaling based on demand.
OVMS inference engine: Executes model inference requests utilizing hardware acceleration.
OpenVINO runtime: Executes optimized model inferences using OpenVINO IR models.
Practical example: Running an inference request and getting metrics
Step-by-step guide:
- Model optimization:
- Train your model: Use a preferred framework such as TensorFlow, PyTorch, or ONNX.
- Optimize the trained model: Use the OpenVINO Model Optimizer to convert your model into the Intermediate Representation (IR) format.
- Deploying with KServe on OpenShift:
- Install OpenVINO toolkit operator: Use the OpenShift console to deploy the OpenVINO toolkit operator for managing model deployments.
- Deploy OVMS: Deploy the OpenVINO Model Server on OpenShift using KServe to manage model inference requests.
- Running inference:
- Send inference requests: Use client applications to send inference requests to the KServe endpoints.
- Monitor metrics: Use KServe's built-in monitoring tools to gather metrics on model performance and resource utilization.
Sample inference request
This inference request demonstrates how to send data gathered from the application and input it into the actual model running on the remote API endpoint, whether on-premise or in the cloud.
Example code:
import requests
response=requests.post("http://<kserve-endpoint>/v2/models/<model-name>:predict",json={"instances": input_data})print(response.json())Conclusion
OpenVINO Model Server (OVMS) streamlines the deployment and management of deep learning models across various environments by leveraging the powerful optimization capabilities of the OpenVINO toolkit. With its support for popular frameworks like TensorFlow, PyTorch, Caffe, and ONNX, as well as multiple model formats, OVMS offers flexibility and ease of integration. Its robust architecture includes features such as model quantization, which reduces computational complexity, and batch processing to enhance throughput, making it ideal for handling high-volume inference workloads. Furthermore, OVMS ensures the security of models and data through comprehensive authentication, authorization, and encryption mechanisms. Whether deployed on-premise, in the cloud, or at the edge, OVMS provides scalable, efficient, and secure AI deployment, enabling organizations to harness the full potential of their AI models with minimal complexity and maximum performance.
By integrating OVMS with Red Hat OpenShift AI and the KServe model serving framework embedded in OpenShift AI, users can achieve enhanced flexibility, scalability, and monitoring capabilities, making it an ideal solution for modern AI/ML workflows. To explore how the joint Red Hat and Intel AI solution can further benefit your AI ecosystem, check out the Red Hat and Intel AI Solution Brief.
Last updated: January 15, 2025