Over the past decade Apache Kafka has become a commonly deployed piece of data infrastructure. It is considered by many to be the de facto standard for low latency, high throughput, scale out message processing, and data streaming. Kafka is also a data store and therefore subject to many of the same security and compliance obligations as databases, such as encryption at rest.
Encrypting Kafka data at rest
Apache Kafka does not provide a facility for encrypting sensitive data at rest. Infrastructure providers usually compensate for this by deploying file system or volume encryption. However, encrypting at this level has drawbacks. First, operations personnel and services with file system permissions may view data content. Secondly, file system and volume encryption is not differentiated with regards to the encryption key—a single key typically encrypts all data, and therefore all Kafka topics, in the file system/volume.
Topic encryption off-broker, above the file system and volume level, addresses these shortcomings. This strategy aligns better with zero-trust architectures because it assures that system administrators of the Kafka broker are unable to view data content, even with full file system permissions. Encrypting at topic-granularity enables the use of topic-specific encryption keys, where the key can in principle be managed by the topic owner, not the infrastructure owner.
Implementation choices
If encryption needs to happen off-broker to provide the desired security properties, there are still a number of options about where encryption can take place.
Encryption within an application certainly works, but it needs to be done in every Kafka application. Clearly that’s incompatible with third-party applications, and impractical for distributed data streaming.
Encryption within a Kafka client, perhaps by using a client-specific plugin, also works but still has drawbacks. It needs to be re-implemented in every client library in a compatible way. Each implementation will likely need to be audited and reviewed (for example, for FIPs certification), which increases costs. Key material ends up being distributed widely across applications.
Another option is to perform encryption between the Kafka client and the broker using a Kafka aware proxy.
How it works
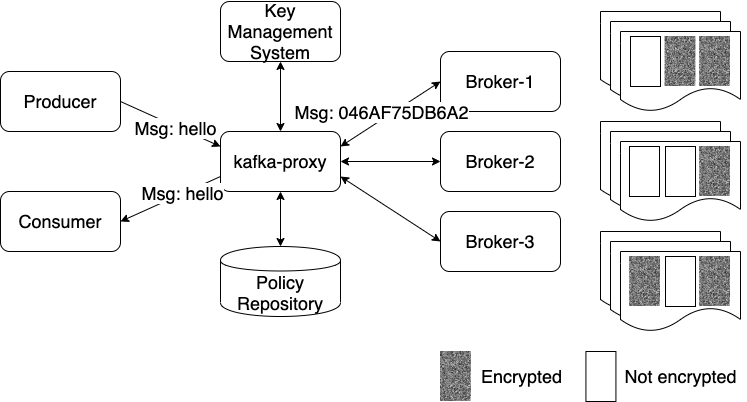
Inserting a proxy between Kafka clients and brokers provides an intermediary for observing and enhancing the Kafka message flow. The proxy intercepts and deserializes Kafka messages, encrypts and decrypts the relevant parts as per policy, re-serializes messages, and forwards messages to their respective destination. Both Kafka clients and brokers are unaware of the proxy and therefore do not require modification or configuration to specifically support topic encryption-at-rest.
In the example shown in Figure 1, a Kafka producer sends a message containing a record with data, “hello”. The proxy receives the Produce message, consults policy, obtains a key from a key management system, encrypts the data, replaces the record data with the ciphertext, and forwards the message to the broker where the data is stored “as-is” in encrypted form. When a Kafka consumer reads from the topic, the proxy intercepts the Kafka Fetch message and initiates the reverse process. The ciphertext is retrieved from the broker, decrypted by the proxy, the record data is replaced with the plaintext “hello”, and the message is returned to the consumer. The Policy Repository is the logical component containing definitions of the topics to encrypt as well as details specific to the topic’s encryption / decryption such as key identifier.
When a Kafka record is encrypted, metadata such as a version, the key ID, and the initialization vector are added by the proxy to the Kafka record, used, then removed during decryption.
Both simple key management and envelope encryption schemes can be supported within this framework. The difference is the meaning of the version and key identifier stored in the message header.
Key rotation strategies are impacted by the immutability of Kafka messages. In some respects, encrypting Kafka data is like tape encryption since it is not possible to update Kafka records persisted at the broker.
One key rotation strategy involves periodically changing the current topic encryption key without re-encrypting previous records. The older key is no longer used for encryption but is used for decryption since older records still refer to the previous key. Should a single key be compromised, the potential extent of the exposure, the so-called blast radius, is limited. Limiting the lifetime of a key either by time, data volume, or number of encryptions without re-encrypting the entire topic is a pragmatic risk-reduction measure.
Re-encrypting all topic data with a new key, for example as a matter of data protection policy or as part of an incident response, may be required. In this case the key rotation strategy involves creating a topic configured with a new key and mirroring the original topic to the new topic before deleting the old topic. This involves stopping traffic to the broker or topic during the mirroring. In most cases, topic consumers must be informed of the new topic identifier.
Which of these alternatives is preferred is a trade-off between having down time on the availability of the topic versus having older messages remaining decryptable using the old key (vulnerable). This in turn depends on the message retention policy of the topics, the key rotation time and the sensitivity of the data stored.
The Kroxylicious Kafka proxy
The initial outcome of a collaboration between IBM Research and Red Hat was a Kafka proxy written using the Vert.X framework.
Subsequently, Red Hat initiated the Kroxylicious project to provide a Kafka-aware proxy supporting pluggable "filters." Filter authors can write custom logic using the Java language. Kroxylicious proxy administrators can then configure their choice of filters. By composing filters into a chain, the administrator can combine multiple features into a single Kafka-aware proxy.
For example, one filter might perform schema validation of records destined for Kafka, rejecting those which do not declare a schema (or which are invalid according to their declared schema), and another filter might transform records, such as encrypting them. By configuring both of these filters (and assuming the only ingress to the Kafka cluster is through the proxy,) a strong guarantee of both schema validity and data security can be made.
The Kroxylicious RecordEncryption filter now implements the same functionality for encrypting records, albeit with a few differences from the original collaboration. For example, the Kroxylicious filter uses envelope encryption and currently only supports the Hashicorp Vault Key Management Service (KMS), though support for Amazon Web Services (AWS) KMS is being added.
Future
There remains some work to do before the Kroxylicious RecordEncryption filter can be said to provide a more complete encryption-at-rest solution for Apache Kafka. We need to implement encryption of Kafka record keys and improve the integrity of the solution, making it harder for malicious actors to tamper with record data on the Kafka broker to subvert the security provided. However, there are limits to what can practically be achieved while working within the constraints imposed by Kafka’s record format, and the contract between Kafka clients and brokers.
Kroxylicious, including the RecordEncryption filter, will be made available as a Technology Preview in the upcoming release of Red Hat AMQ Streams, a fully supported distribution of Apache Kafka. Users of both Red Hat AMQ Streams and the open source Kroxylicious project are invited to experiment with it and provide feedback.
Additional resources
- Kroxylicious source code repository
- Securing Kafka with Encryption-at-Rest, 2021 IEEE International Conference on Big Data (Big Data), C. Giblin, S. Rooney, P. Vetsch, A. Preston.
- Safeguarding Your Kafka Data with Encryption-at-rest, Kafka Summit London 2024, T. Bentley.