Encryption is valuable in Apache Kafka, as with other communication tools, for protecting data that might be sent to unanticipated or untrustworthy recipients. This series of articles introduces the open source Kryptonite for Kafka library, which is a community project I wrote. Kryptonite for Kafka requires no changes to source code, as it works entirely through configuration files. It currently does so by encrypting data through integration with Apache Kafka Connect, but there are plans to extend the scope of the project to other integration strategies for Kafka.
This first article in the series demonstrates encryption on individual fields in structured data, using a relational database and a NoSQL database as examples. The second article focuses on files and introduces some additional sophistication, such as using different keys for different fields.
How Kryptonite for Kafka reduces the risk of a data breach
Kafka can take advantage of several security features, ranging from authentication and authorization to TLS-based, over-the-wire traffic encryption of data on its way in and out of Kafka topics. Although these measures secure data in transit, they take place within Kafka, so there is always a stage where the broker has to see plaintext data and temporarily keep it in memory.
This stage can be considered a blind spot in Kafka security. The data might be encrypted on disk, but the Kafka brokers see the plaintext data right before storing it, and decrypt the data temporarily every time they read it back from disk. Therefore, disk encryption alone cannot protect against RAM scraping and other clever attack vectors.
Kryptonite for Kafka plugs this in-memory loophole and offers added sophistication, such as the ability to encrypt specific fields in structured data.
Encryption outside the Kafka brokers
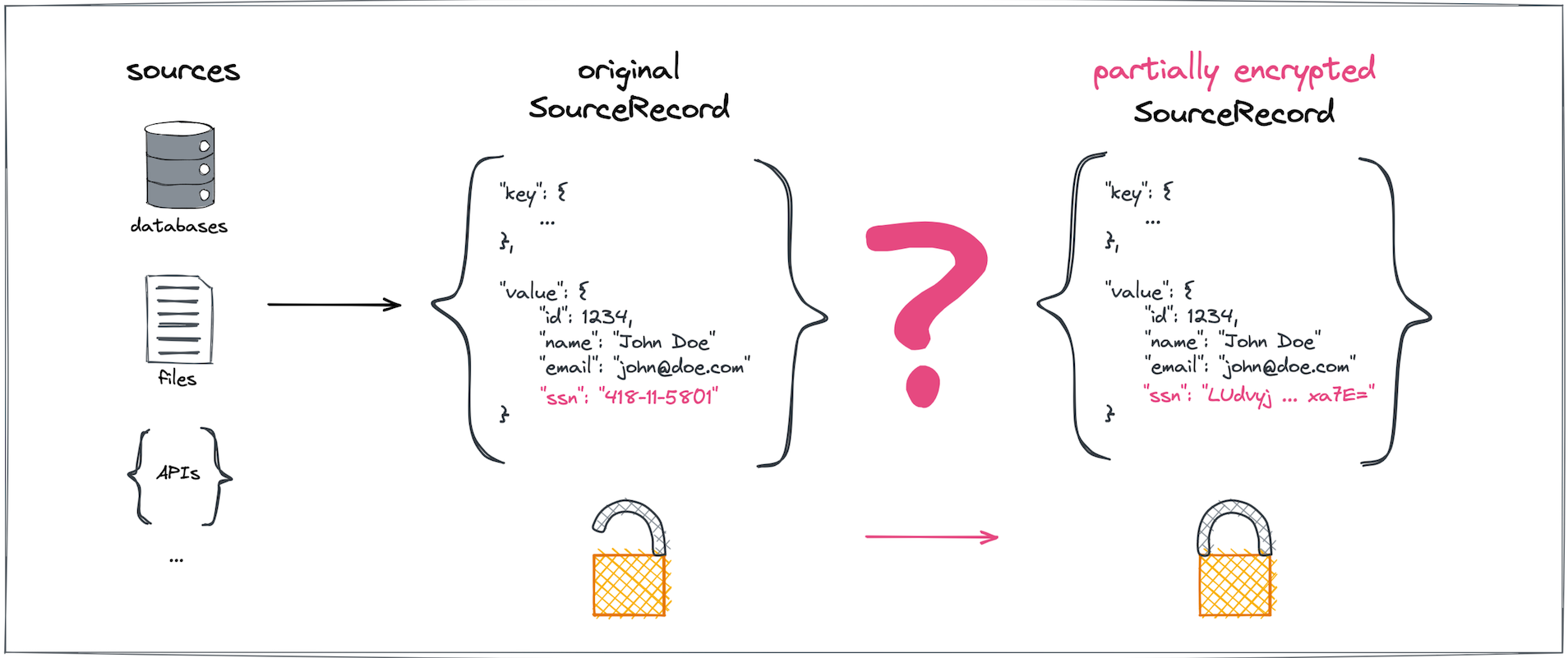
Let's imagine a generic Kafka Connect data integration. Assume we would like to encrypt a certain subset of sensitive fields found in a ConnectRecord payload originating from any data source (Figure 1).
On the consumer side, we need to decrypt the same subset of previously encrypted fields in a ConnectRecord payload directed to the data sink (Figure 2).
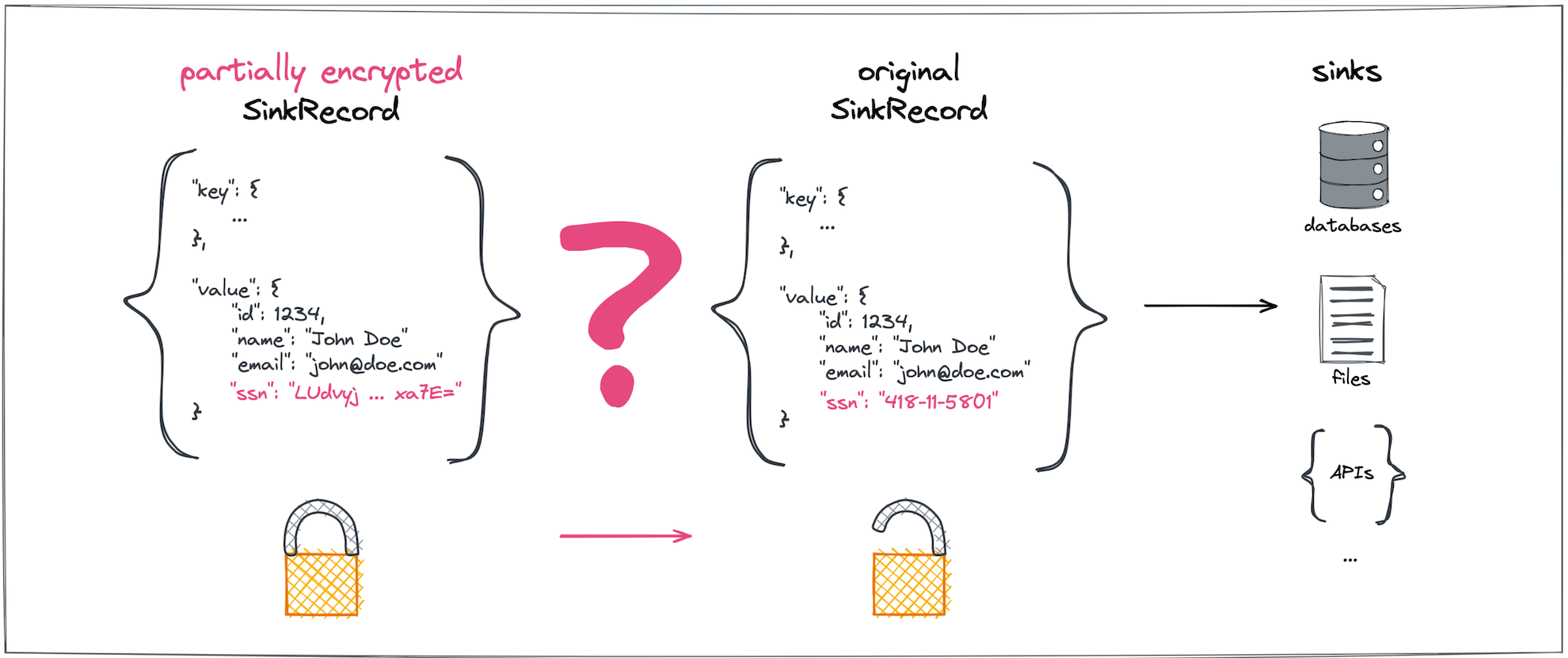
To make sure the Kafka brokers themselves never get to see—let alone directly store—the original plaintext for sensitive data fields, the encryption and decryption must happen outside of the brokers, a step represented by the pink question marks in Figures 1 and 2.
Kryptonite for Kafka's approach to data encryption: An overview
Before Kryptonite for Kafka, no flexible and convenient way to accomplish client-side field-level cryptography was available for Kafka in free and open source software, neither with the standard features in Kafka Connect nor with additional libraries or free tools from Kafka Connect's open-source ecosystem.
Encryption could happen directly in the original client or in some intermediary process like a sidecar or a proxy, but an intermediary would likely impose higher deployment effort and an additional operational burden. To avoid this, Kryptonite for Kafka currently performs the encryption and decryption during a Kafka Connect integration. The worker nodes of a Kafka Connect cluster encrypt the fields designated as sensitive within ConnectRecord instances.
For that purpose, the library provides a turnkey ready single message transform (SMT) to apply field-level encryption and decryption to Kafka Connect records. The system is agnostic to the type of message serialization chosen. It uses authenticated encryption with associated data (AEAD), and in particular applies AES in either GCM or SIV mode.
Each encrypted field is represented in the output as a Base64-encoded string that contains the ciphertext of the field's value along with metadata. The metadata consists of a version identifier for the Kryptonite for Kafka library itself, a short identifier for the encryption algorithm, and an identifier for the secret key material. The metadata is authenticated but not encrypted, so Kryptonite for Kafka on the consumer side can read it and use it to decrypt the data.
For schema-aware message formats such as AVRO, the original schema of a data record is redacted so that encrypted fields can be stored in Base64-encoded form, changing the original data types for the affected fields.
In a nutshell, the configurable CipherField SMT can be plugged into arbitrary Kafka Connect pipelines, safeguarding sensitive and precious data against any form of uncontrolled or illegal access on the data's way into and out of Kafka brokers (Figures 3 and 4).
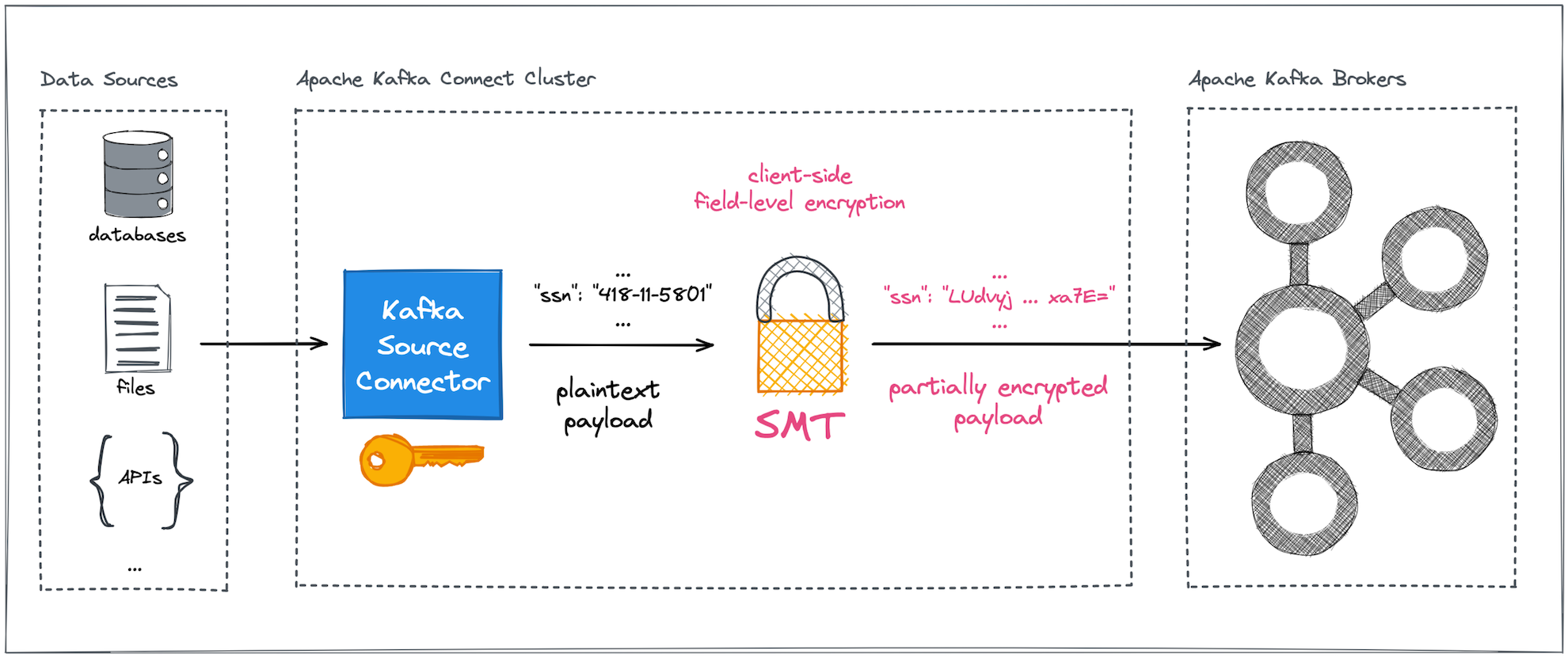
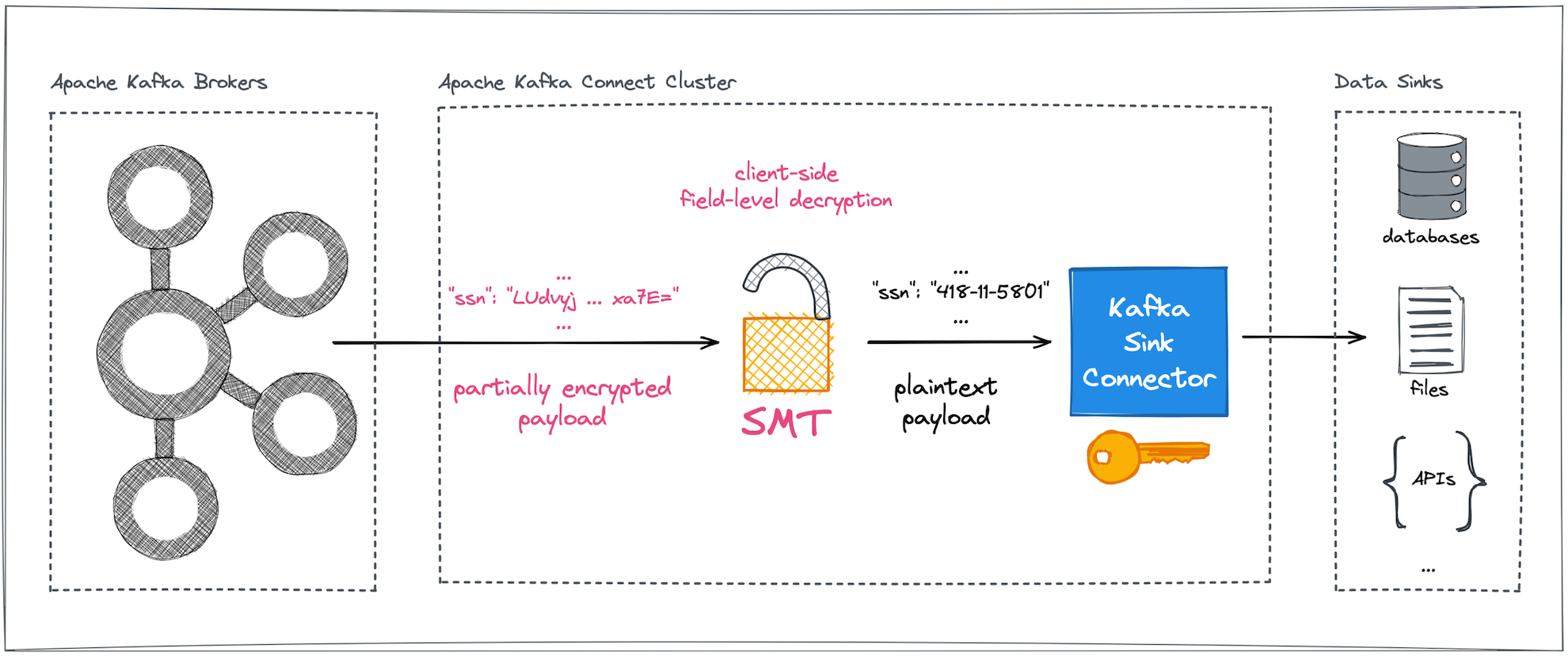
Advantages of encryption outside the Kafka brokers
With the Kryptonite for Kafka approach, sensitive fields are automatically and always secured, not only in transit but also at rest, whenever sensitive data is outside the Kafka Connect environment. Protection is guaranteed for all target systems and for whatever downstream consumers eventually get their hands on the data. Even if someone has access to the brokers, they cannot misuse the sensitive parts of the data unless they manage to steal the secret keys from (usually remote) client environments or break the underlying cryptography itself.
In short, Kryptonite for Kafka offers an additional layer of data security independent of whoever owns or operates the Kafka cluster, thus protecting the data against internal attackers. Encryption also protects data against external attackers who might get fraudulent access to the Kafka topic data in the future.
Given such a setup, you can precisely define which downstream consumers can read the sensitive data fields. In a Kafka Connect data integration pipeline, only sink connectors explicitly given access to the secret keys can successfully decrypt the protected data parts.
Example: Exchanging structured data between a relational database and a NoSQL database
This example demonstrates field-level data protection during replication between two different types of databases. The source is MySQL and the sink is MongoDB. The exchange uses the open source Debezium platform for log-based change data capture (CDC). Kryptonite for Kafka post-processes Debezium's MySQL CDC event payloads to encrypt certain fields before the data leaves Kafka Connect on the client side and reaches the Kafka brokers. The MongoDB sink connector that reads these Kafka records gets access to pre-processed, properly decrypted records, and at the end of the process stores plaintext documents into MongoDB collections (Figure 5).
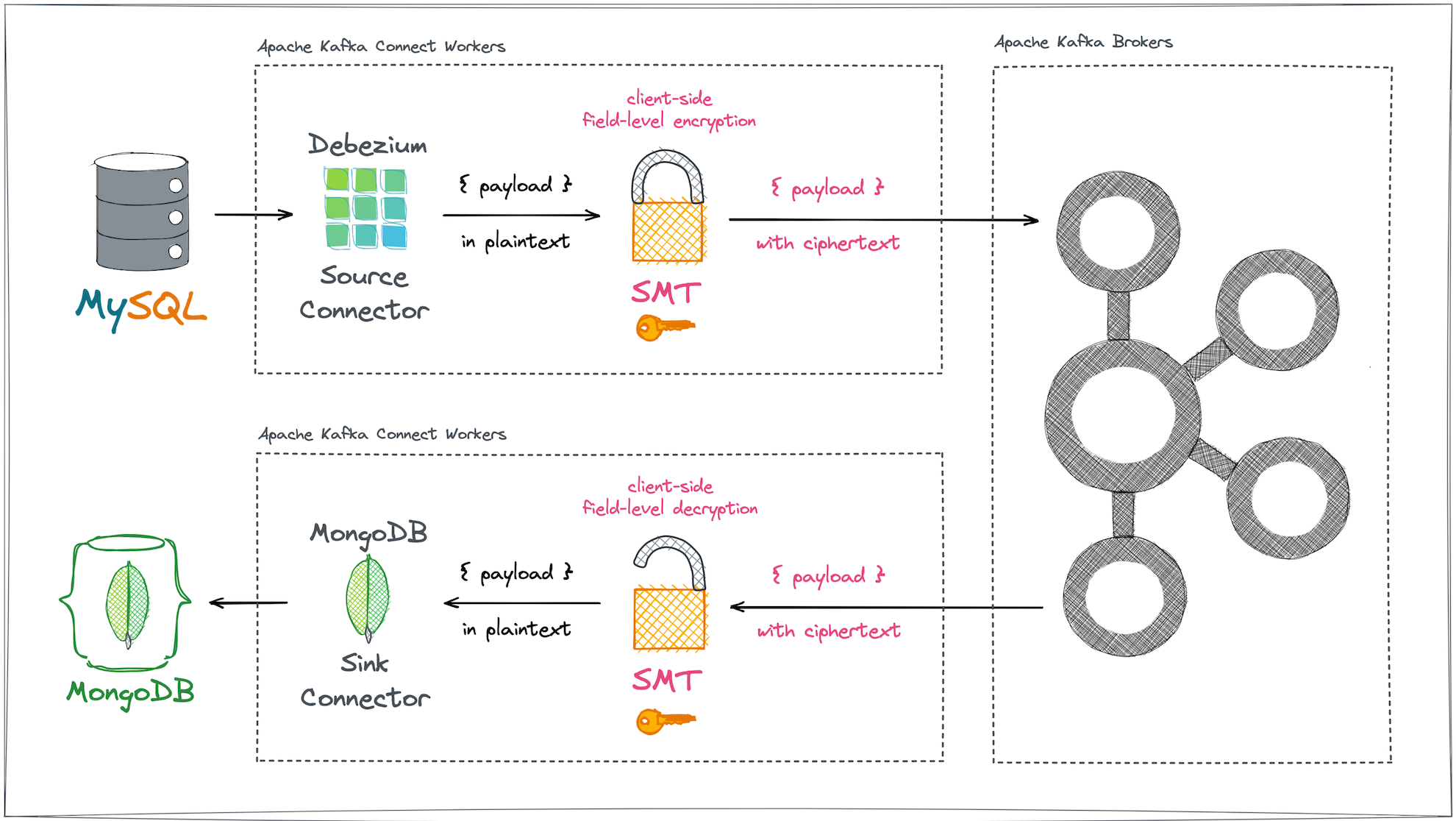
Producer-side encryption
The MySQL instance stores, among other data, an addresses table containing a couple of rows representing different kinds of fictional customer addresses (Figure 6).

The following Debezium MySQL source connector captures all existing addresses, together with any future changes from the table:
{
"name": "mysql-source-001",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "debezium",
"database.server.id": "1234567",
"database.server.name": "mysqlhost",
"database.whitelist": "inventory",
"table.whitelist": "inventory.addresses",
"database.history.kafka.bootstrap.servers": "kafka:9092",
"database.history.kafka.topic": "mysqlhost-schema",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": false,
"transforms.unwrap.delete.handling.mode": "drop"
}
}
The preceding configuration is pretty straightforward, serializing CDC events as JSON without explicit schema information and unwrapping the Debezium payloads. Unsurprisingly, the resulting plaintext record values stored in the corresponding Kafka topic (called mysqlhost.inventory.addresses) will look something like this:
{
"id": 13,
"customer_id": 1003,
"street": "3787 Brownton Road",
"city": "Columbus",
"state": "Mississippi",
"zip": "39701",
"type": "SHIPPING"
}
Let's assume the task is now to make sure that values originating from the addresses table's street column (Figure 7) for all these CDC event payloads must not be stored in Kafka topics as plaintext.
Thanks to the field-level encryption capabilities of the custom CipherField SMT, fine-grained protection can be easily achieved without writing any additional code. Simply add the following to the Debezium MySQL source connector configuration:
{
"name": "mysql-source-enc-001",
"config": {
/* ... */
"transforms": "unwrap,cipher",
/* ... */
"transforms.cipher.type": "com.github.hpgrahsl.kafka.connect.transforms.kryptonite.CipherField$Value",
"transforms.cipher.cipher_mode": "ENCRYPT",
"transforms.cipher.cipher_data_keys": "${file:/secrets/classified.properties:cipher_data_keys}",
"transforms.cipher.cipher_data_key_identifier": "my-demo-secret-key-123",
"transforms.cipher.field_config": "[{\"name\":\"street\"}]",
"transforms.cipher.predicate":"isTombstone",
"transforms.cipher.negate":true,
"predicates": "isTombstone",
"predicates.isTombstone.type": "org.apache.kafka.connect.transforms.predicates.RecordIsTombstone"
}
}
The SMT configuration contains transform.cipher.* properties with the following meanings:
- Operate on the records' values (
type: "CipherField$Value"). - Encrypt data (
cipher_mode: "ENCRYPT"). - Load the secret key material from an external key file (
cipher_data_keys: "${file:/secrets/classified.properties:cipher_data_keys}). - Use a specific secret key based on its ID (
cipher_data_key_identifier: "my-demo-secret-key-123"). - Process only the
streetfield (field_config: "[{\"name\":\"street\"}]"). - Ignore any tombstone records (see predicate definitions).
Maintaining the secrecy of the secret key materials is of utmost importance, because leaking any of the secret keys renders encryption useless. Secret key exchange is a complex topic of its own. This example obtains the keys indirectly from an external file, which contains a single property called cipher_data_keys that in turn holds an array of key definition objects (identifier and material):
cipher_data_keys=[ { "identifier": "my-demo-secret-key-123", "material": { "primaryKeyId": 1000000001, "key": [ { "keyData": { "typeUrl": "type.googleapis.com/google.crypto.tink.AesGcmKey", "value": "GhDRulECKAC8/19NMXDjeCjK", "keyMaterialType": "SYMMETRIC" }, "status": "ENABLED", "keyId": 1000000001, "outputPrefixType": "TINK" } ] } } ]
More details about externalizing sensitive configuration parameters in Kafka Connect can be found in the library's documentation.
The resulting source connector configuration achieves the goal of partially encrypting all Debezium CDC event payloads before they are sent to and stored by the Kafka brokers. The resulting record values in the topic mysqlhost.inventory.addresses reflect the encryption:
{
"id": 13,
"customer_id": 1003,
"street": "NLWw4AshpLIIBjLoqM0EgDiUGooYH3jwDnW71wdInMGomFVLHo9AQ6QPEh6fmLRJKVwE3gwwsWux",
"city": "Columbus",
"state": "Mississippi",
"zip": "39701",
"type": "SHIPPING"
}
Consumer-side decryption
The sink connector that picks up these partially encrypted Kafka records needs to properly apply the custom CipherField SMT as well. Only then can the connector get access to the previously encrypted Debezium CDC payload fields before writing them into the targeted data store, which is MongoDB in this case.
The MongoDB sink connector configuration for this example might look like this:
{
"name": "mongodb-sink-dec-001",
"config": {
"topics": "mysqlhost.inventory.addresses",
"connector.class": "com.mongodb.kafka.connect.MongoSinkConnector",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable":false,
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable":false,
"tasks.max": "1",
"connection.uri":"mongodb://mongodb:27017",
"database":"kryptonite",
"document.id.strategy":"com.mongodb.kafka.connect.sink.processor.id.strategy.ProvidedInKeyStrategy",
"delete.on.null.values": true,
"transforms": "createid,removefield,decipher",
"transforms.createid.type": "org.apache.kafka.connect.transforms.ReplaceField$Key",
"transforms.createid.renames": "id:_id",
"transforms.removefield.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.removefield.blacklist": "id",
"transforms.decipher.type": "com.github.hpgrahsl.kafka.connect.transforms.kryptonite.CipherField$Value",
"transforms.decipher.cipher_mode": "DECRYPT",
"transforms.decipher.cipher_data_keys": "${file:/secrets/classified.properties:cipher_data_keys}",
"transforms.decipher.field_config": "[{\"name\":\"street\"}]",
"transforms.decipher.predicate":"isTombstone",
"transforms.decipher.negate":true,
"predicates": "isTombstone",
"predicates.isTombstone.type": "org.apache.kafka.connect.transforms.predicates.RecordIsTombstone"
}
}
The interesting part again is the configuration's transform.decipher.* properties, which are defined as follows:
- Operate on the records' values (
type: "CipherField$Value"). - Decrypt data (
cipher_mode: "DECRYPT"). - Load the secret key material from an external key file (
cipher_data_keys: "${file:/secrets/classified.properties:cipher_data_keys}). - Use a specific secret key based on its ID (
cipher_data_key_identifier: "my-secret-key-123"). - Process only the
namefield (field_config: "[{\"name\":\"street\"}]"). - Ignore any tombstone records (see predicate definitions).
With this configuration in place, Kafka Connect processes all CDC events by first applying the custom CipherField SMT to decrypt selected fields, and then handing them over to the sink connector itself to write the plaintext documents into a MongoDB database collection called kryptonite.mysqlhost.inventory.addresses. An example document for the address having _id=13 is shown here in its JSON representation:
{ "_id": 13,
"zip": "39701",
"city": "Columbus",
"street": "3787 Brownton Road",
"state": "Mississippi",
"customer_id": 1003,
"type": "SHIPPING" }
This example has shown how end-to-end change data capture pipelines between heterogenous databases can be secured by explicitly protecting sensitive CDC payload fields. Proper configuration of a custom SMT is sufficient to achieve client-side field-level encryption and decryption of Kafka Connect records on their way in and out of Kafka topics. A fully working example of this database integration scenario can be found in the accompanying demo scenario repository.
The second article in this series will show the use of Kryptonite for Kafka with files, introduce more features, and discuss plans for the future of the project.
Last updated: August 14, 2023