Many times, I’ve helped customers choose between Red Hat AMQ Broker and Red Hat AMQ Streams. Red Hat AMQ Broker is a messaging solution based on the upstream Apache ActiveMQ Artemis project. Red Hat AMQ Streams, on the other hand, is a data streaming platform based on the combination of the upstream Apache Kafka and Strimzi projects.
We could perform a thorough feature-to-feature comparison to decide between those two. Instead, I will provide an alternative view from the perspective of the philosophy behind those two initiatives.
Pushing messages versus pulling events
Apache ActiveMQ Artemis exposes open interfaces and open protocols. The client applications can exchange information with the server through JMS, AMQP, or MQTT. As a consequence, those client applications can be written in multiple languages such as Java, .NET, JavaScript, and Python. So, the client applications send messages to the server, as depicted in Figure 1.
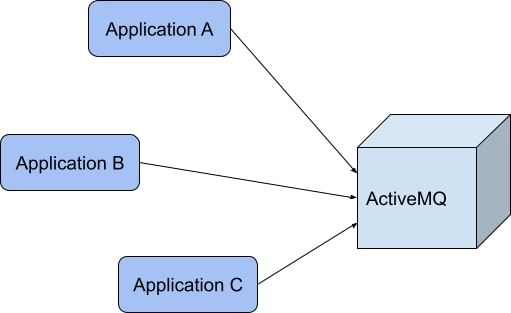
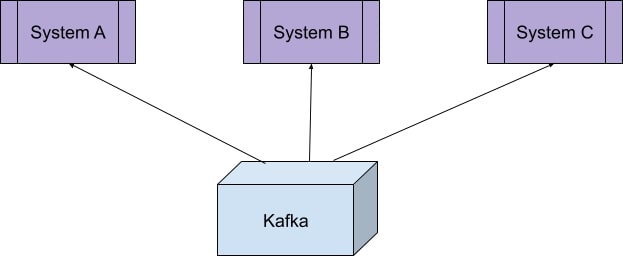
On the other hand, Apache Kafka uses its own protocol. Only clients using the Kafka API can interact with it. Therefore, here, it's rather the server that will get information from external systems (Figure 2). This opposite approach changes from the concept of messages to the concept of events.
Quality of service
Considering data as events rather than messages has led to a different way of defining certain responsibilities. Kafka will query data from external systems and store them for later consumption. It will not take any responsibility for how to interpret the data or for determining its importance. This responsibility will be left to the consumers.
ActiveMQ, on the other hand, will be requested by an external system to carry the data for it and will implicitly accept some responsibility for handling the message with a proper quality of service.
We can understand that difference easily if we consider the exactly-once delivery quality of service. This is achievable with both technologies. But on one hand, it will be guaranteed by the server, while on the other hand, it will be up to the consumer to enforce it. Even though there are some experimental components aimed at bringing the concept of transactions to Kafka, we already know from the CAP theorem that it will have to leave behind either partitioning or high availability.
To go one step further, Kafka will not even ensure the data is safely stored. The data will be sent to the cache, which will eventually flush it to disk. Alternatively, ActiveMQ performs synchronous writing to ensure acknowledged data can never be lost.
Clustering
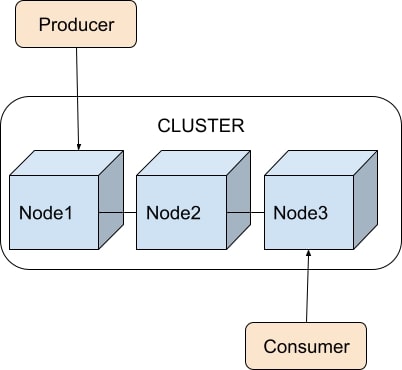
With ActiveMQ, the consumer doesn’t have to be connected exactly where the message is produced. The proper routing of the message is another responsibility taken by the server. It’s the same principle as having postmen to ensure the delivery of the mail to the right addresses.
As a consequence, if the clustering feature can indeed provide an increase in the inbound throughput, it is usually accompanied by a decrease in the outbound latency due to the hops the data need to cross to reach the right consumers over the cluster (Figure 3).
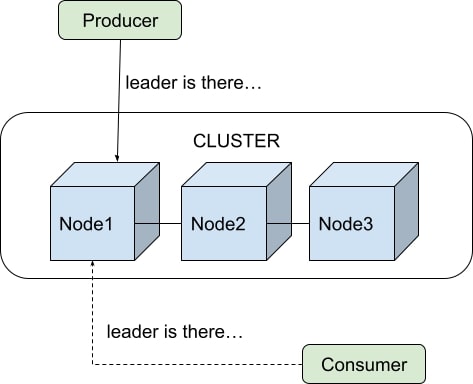
In the case of Kafka, the server doesn’t take any responsibility for ensuring that events are sent to the proper destination. Instead, it will help the client applications willing to consume an event to connect to the node where the event is located (Figure 4), which guarantees both maximum throughput and minimum latency. Here, that would be closer to acting as the post office.
Is Kafka better than ActiveMQ?
It is true that ActiveMQ doesn’t fit with the cloud as well as Kafka does. But it doesn’t mean that there are no longer any use cases for ActiveMQ. The cloud is not only a change of technology but also a change of paradigm. Today, we might still have more use cases for ActiveMQ than for Kafka, as there are still plenty of business use cases requiring guaranteed deliveries of information. Actually, comparing ActiveMQ to Kafka is not very far from comparing a relational database to a NoSQL one.
Last updated: August 14, 2023