Our team took a fresh look at installing Red Hat OpenShift on bare-metal hardware and developed a software-as-a-service (SaaS) installation service called the Assisted Installer, available as a technology preview on the Red Hat Hybrid Cloud Console. This article describes the design and architectural choices we made in order to be able to offer the service for both on-premises and cloud deployments, while also continuously improving user experience.
Installing bare-metal clusters
Installing clustered software has become simpler with the adoption of virtualization and the cloud, which can provide the requisite infrastructure with a few API calls. Some software is even offered "as a service" on these platforms, allowing users to forgo installation and management.
However, installing bare-metal clusters is more challenging. An infrastructure administrator typically provides connected hardware, IP addresses, and other environmental configurations such as DHCP, DNS, and NTP. The cluster creator then typically configures the clustered software. In case of misconfiguration, the installation fails and the administrators must investigate the cause.
In designing the OpenShift Assisted Installer, our main goal was to provide an excellent user experience. This meant an intuitive and interactive flow that simplified and demystified the configuration inputs, provided early feedback, and, of course, ended with a successful installation.
From the cloud to bare metal
Why run the Assisted Installer service on the cloud rather than have users deploy it themselves? There are four reasons:
- Users can jump into the installation process without pre-installing any software.
- We collect aggregate metrics on usage and failures as a feedback loop for improving the service. Examples of usage information include the popularity of each feature and how many users reach each installation stage. This information helps us see where users experience difficulty with the installation. We also look at where most failures occur, and correlate failures and various parameters such as the OpenShift version or other enabled features.
- We can easily help users debug failed installations, as all logs and events are stored by the service.
- We deploy new versions of the Assisted Installer often in order to get the latest code into users’ hands, collect feedback quickly from metrics and failed installations, and iterate again.
These benefits are typical for software deployed as a service. However, bare-metal hardware is not always connected to the Internet and therefore seems like a less natural fit for SaaS. Consequently, we architected the installer service to run either as a scalable SaaS or on-premises in a potentially disconnected environment. Users get all of the benefits from running as a cloud service while also offering stable versions for on-premises deployments.
Assisted Installer's dual architecture
Figure 1 highlights the service's deployment-specific areas. The SaaS deployment exposes a user-facing REST API and uses cloud services for storing metadata and files, as shown in red. The service is deployed on-premises as a Kubernetes Operator, exposing a Kubernetes-native custom resource API and using locally-deployed storage, which is shown in blue. Outside of these few components, the vast majority of the service is identical in both deployment types.
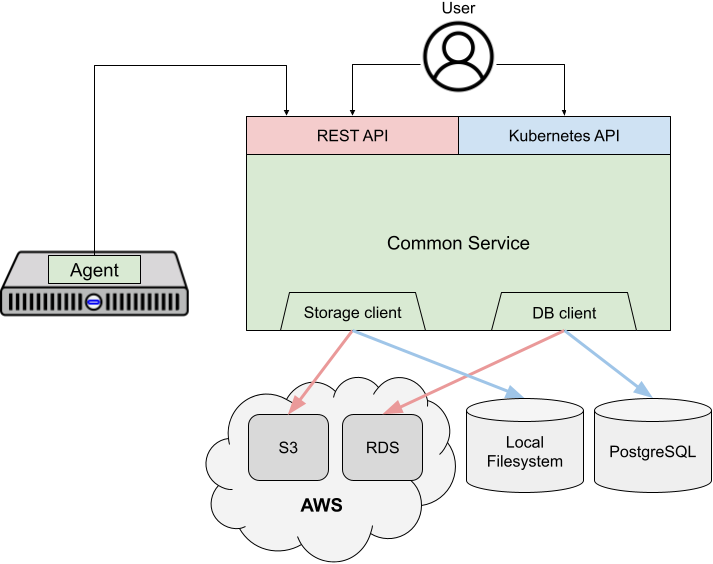
The first main difference between the two deployments is the user-facing API. An administrator using the SaaS would use the imperative REST API. For an on-premises deployment, they would use the declarative Kubernetes-native API. As is standard in Kubernetes, a controller implements the API logic for a resource in a “reconciliation” function that is called whenever the desired or actual state changes. Each controller compares the desired state of a resource as specified by the administrator with the resource's actual state and executes a series of imperative actions to reach the desired state. The service’s events subsystem, which allows administrators to monitor installations, also triggers the reconciliation whenever the actual state changes.
Before installing, the infrastructure administrator boots any number of hosts with a discovery image that causes the host to run an agent process. Using the REST API, the agent registers with the installer service and polls for instructions, such as performing various validations and installing itself. The agent-service communication is well-suited for the SaaS: Because hosts are generally not publicly addressable, agents contact the service and not the other way around. We use HTTPS for added security, and the agent can be configured to use an HTTP or HTTPS proxy.
The installer service itself is stateless, storing its state in an SQL database and its files in an object store. This allows the SaaS deployment to scale out to handle the load from many simultaneous users. Kubernetes Operators, on the other hand, store their state in the Kubernetes cluster’s etcd key-value store. This currently means that we are maintaining the same state in two databases, and the Kubernetes Operator requires a persistent volume, neither of which is ideal. However, we plan to modify the service to treat the SQL database and storage as ephemeral and rely on the key-value store for the source of truth.
One improvement we have in mind for this architecture is to move the Kubernetes Operator into an independent component that interacts with the installer service via a REST API. The resulting operator would be more similar to existing operators interacting with external REST services, such as Crossplane or ACK. We would first implement an efficient method for the operator to receive events via a webhook to avoid polling.
Conclusion
OpenShift's Assisted Installer service illustrates how software that is traditionally on-premises and disconnected can be architected to also run as a service, providing the benefits of fast feedback-update-release cycles. This software reuse, along with a strong user-experience focus, has generated positive user feedback and a high installation success rate for this service.
Last updated: August 27, 2025