Accessing and operating on data is one of the most time-consuming aspects of computing. Developers can improve efficiency by looking for ways to avoid the overhead required by standard file operations. To illustrate the possibilities, I will report on a couple of interesting cases where I designed cloud-scale services that dynamically construct files for users to consume.
The first application was an incremental backup and restore application, and the second was part of a new OpenShift installation service that creates personalized ISO files of Red Hat Enterprise Linux CoreOS (RHEL CoreOS). Both applications went through similar iterations, starting with naive implementations and gradually improving their efficiency. I will focus on the ISO design first and briefly discuss the backup and restore application at the end.
First optimization: Amazon S3 server-side copy
In the naive ISO implementation, we started with a copy of the RHEL CoreOS ISO in an Amazon Simple Storage Service (S3) bucket. When a user requested a customized ISO via a "generate" REST API, the back-end service fetched the base ISO from S3, executed logic to insert our customizations into the ISO (Ignition data), and uploaded the resulting ISO back to S3. The user could then download the ISO directly from S3.
This naive implementation required the back-end service to download roughly 900MB to the file system, read it, perform a few modifications, write the new ISO to the file system, and upload the new 900MB ISO. The whole process took roughly 30 seconds and incurred significant Amazon Web Service (AWS) costs—both from data transfers and from storing the 900MB per ISO. However, an important benefit was that users downloaded their files directly from S3, so our service did not need to incur the overhead of the download traffic.
The first milestone in optimizing this design involved S3’s UploadPartCopy API. Amazon S3 recommends dividing the uploads of large files into parts for parallelized uploads and resilience to network issues. The UploadPartCopy API tells S3 that it should retrieve a part’s data from an offset in an existing object instead of expecting a data upload for the specific part. For this optimization, we took advantage of the intelligent way Ignition data is stored in the RHEL CoreOS ISO, as depicted in Figure 1.
An ISO is generally created by taking a directory tree with the necessary files and packing it up with a given tool. The RHEL CoreOS generation process adds an empty file where the Ignition data will be stored into that directory tree, packs the ISO, finds the empty file’s offset in the ISO, and writes the offset and size into a well-known offset in the ISO’s header. Our optimization instructed S3 to create the new ISO object by performing server-side copies of the data preceding and following the Ignition area, and filling the Ignition area with our uploaded Ignition configuration, as shown in Figure 2.
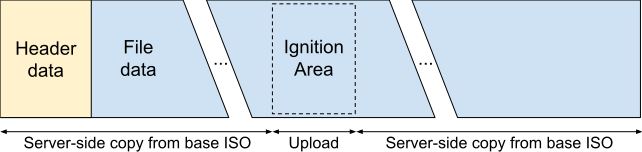
Amazon S3 requires each file part to be between 5MB and 5GB in size, which slightly complicated our implementation, but it was straightforward otherwise. The generation time went down from 30 seconds to around 12, and we also saved money on transfer costs. However, we were still paying for storing all of the custom ISOs.
Second optimization: Download stream injection
The second optimization involved a tradeoff: We would serve files from our installation service instead of from S3. This allowed an optimized experience and eliminated almost all S3 costs, but incurred the download traffic costs.
We again started with the base ISO in S3 but cached it locally. When a user asked to download their ISO, we would begin serving data from the cached base ISO. But as soon as the download stream reached the Ignition area, we began serving our Ignition data. After we injected the Ignition data into the download stream, we continued serving the data from the base ISO.
The benefits were that our service no longer incurred S3 transfer costs or storage costs. This optimization also improved our user experience (UX); rather than forcing the user to generate an ISO, wait 12 or 30 seconds, and then download the file, the user could initiate the download immediately. The drawback was that our service needed to handle the user download traffic. To address this, we split the ISO service into a separate microservice that we could independently scale.
Backup and restore application
The backup and restore application that I designed was similar. We implemented incremental disk backups, meaning that the oldest backup contained a full disk image at a certain point in time, and each additional backup contained only the chunks of data that changed from the previous backup. We implemented each backup as one S3 object containing the data and another object containing a bitmap describing the chunks the data object contained.
The three primary operations in this application were backup, restore, and compaction. We continuously tracked the changes to the disk locally using a bitmap. We took a consistent snapshot of both the data and the bitmap and uploaded them to S3 in the previously described format to create a new backup.
To restore a disk backup, we downloaded all relevant bitmaps to understand which chunks should be read from which backups. We then created a download stream that read only the relevant data from the relevant incremental backup objects.
Compaction is an important operation in incremental backups. If left unchecked, the incremental backup chains would grow indefinitely. The growth would incur high storage costs, long recovery times, and, worst of all, an increased risk that a restore operation would fail due to a corrupt link in the chain. Therefore, compaction merges the oldest (full) backup with the next-oldest (incremental) backup. We performed this merge using the S3 UploadCopyPart API that I described earlier, creating a new full backup from the two original backups.
Conclusion
These examples illustrate the impact of file formats on subsequent operations involving the files. If you are dealing with existing file formats, get to know them and consider how to best work with them. If you have the challenge and luxury of defining a new file format, efficient operations should be among your top considerations.
In either case, it is important to become familiar with your storage platform's APIs and behaviors. What operations can you offload to it? Does it perform better with many small files or a few large ones? Is there a significant difference between random and sequential access? File operations tend to be slow compared to other application tasks, but there are also many opportunities for optimization and innovation.
Last updated: October 30, 2023