If you have ever tested throughput performance in a container deployment, you know that the UDP protocol is (a lot) slower than TCP. How can that be possible? After all, the TCP protocol is extremely complex, whereas UDP is simple and carries less per-packet overhead. This article will explain the not-so-dark magic beyond the superior TCP throughput performance and how recent improvements in the Linux kernel can close that gap. You'll also learn how to use all these shiny new features in the upcoming version 8.5 of Red Hat Enterprise Linux to boost UDP throughput in container deployments by a factor of two or more.
Bulk transfers and packet aggregation through TSO and GRO
The typical container network infrastructure is quite complex. When a container sends a packet, it traverses the kernel network stack inside the container itself, reaches a virtual Ethernet (veth) device, and is forwarded on the peer veth device to reach the host virtual network. The host then forwards the packet towards a Linux or Open vSwitch (OVS) bridge and eventually over a UDP tunnel. Finally, the packet reaches the hardware network interface card (NIC). Figure 1 illustrates the sequence of packet transmissions.
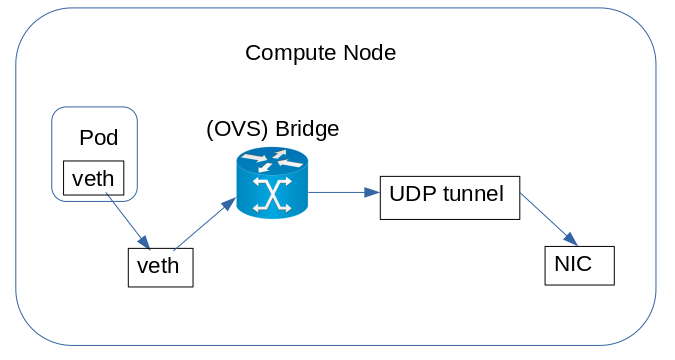
A packet coming in on the wire, targeting the container, will go through the same path in the reverse direction.
It's easy to guess that the CPU time needed to perform all the forwarding and encapsulation steps is easily far greater than the actual transport protocol processing time, regardless of the actual complexity of the protocol—whether UDP, TCP, or MPTCP. Additionally, the container orchestration adds significant overhead due to the complex forwarding ruleset needed to cope with multiple containers per host, etc.
TCP and MPTCP can alleviate the forwarding overhead thanks to aggregation. On the transmit side, the data stream is glued into packets larger than the current TCP maximum segment size (MSS). The large packets traverse the whole virtual network unmodified until they land on the real NIC. In the most common scenario, the NIC itself segments the large packet into MSS-size ones via Transmit Segmentation Offload (TSO).
In the reverse path, the packets received by the NIC are aggregated into large ones before entering the network stack. The received packet aggregation is usually performed by the CPU and is called Generic Receive Offload (GRO). Some NICs have hardware offload capability for GRO too.
In both cases (receive and transmit), a single aggregated packet amortizes the high virtual network forwarding cost for multiple packets received or sent on the wire. The key point is that such aggregation is not available by default for the UDP protocol, and each UDP packet has to pay the full forwarding overhead.
Generic Receive Offload for UDP—why not?
The TCP protocol is stream-oriented. Therefore, its data can be segmented in as many packets as needed, as long as the data stream can be reconstructed while preserving the data integrity. In contrast, the UDP protocol is packet-based: The data is transmitted in units (packets) whose size is specified by the user-space application. Splitting a single UDP packet into multiple ones or aggregating multiple UDP packets in a single one may confuse the recipient, which relies on the packet length to identify the application layer message size.
Due to all the considerations discussed so far, the Linux kernel has long supported GRO/TSO for the TCP protocol only.
Since Linux 4.18, thanks to QUIC—a reliable transport protocol built on top of UDP—the Linux UDP implementation has gained TSO support. It's up to the application to enable UDP segmentation on a per-socket basis and then pass the aggregated UDP packets to the kernel and the target length for the on-the-wire packet. Because this feature is a per-application opt-in, the peers by design understand that the application message size is potentially different from the transmitted or received UDP packet size.
TSO support can significantly improve the performance of UDP transmits in containers. But the improvement doesn't assist the receive path.
More recently, in Linux 5.10, the UDP protocol has additionally gained GRO support. This side of the aggregation process is also enabled on a per-socket basis. Once the application sets the relevant socket option, UDP_GRO, the network stack starts aggregating incoming packets directed to the relevant socket in a process similar to what it was already doing for TCP.
With GRO in place, even the container receive path could potentially see the benefit of packets aggregation. Still, a few significant problems stand out. Because both TSO and GRO must be enabled explicitly from the user-space applications, only a few would go to the trouble. Additionally, a virtual network is often built on top of UDP tunnel virtual devices, and the initial UDP GRO implementation did not support them.
The missing Linux kernel pieces
But the Linux network community never sleeps—literally, have a look at the timestamps on the email sent by the main contributors on the mailing list—and system-wide UDP GRO support has long been only a few bits away: the kernel just needed to segment back the UDP aggregated packet as needed. For example, an aggregated UDP GRO packet could land on a socket lacking the UDP_GRO option due to some complex forwarding configuration. Segmenting the aggregated packet avoids confusing the receiver application with unexpected large datagrams. System-wide UDP GRO was implemented upstream with Linux 5.12. This feature still requires some kind of opt-in: It is off by default, and the system administrator can enable it on a per-network device basis.
Shortly afterward, with version 5.14, Linux gained additional support for UDP over UDP-tunnel GRO, again an opt-in feature that a system admin could enable the same way as basic UDP GRO. All the pieces needed to leverage TSO/GRO end-to-end for UDP application were in place—almost: UDP applications still have to enable TSO on the transmit side explicitly.
What about the existing applications with no built-in TSO support? The complexity in the container virtual network setup can be of some help, for once. Packets generated inside the container have to traverse a veth pair. Virtual ethernet forwarding is usually a straightforward and fast operation, but it can also be configured to optionally trigger GRO. This is usually not needed for TCP packets because they reach the veth already aggregated. But few user-space applications aggregate UDP packets.
Before Linux 5.14, to enable GRO on veth devices, a system administrator was required to attach an eXpress Data Path (XDP) program to the veth pair. Linux 5.14 removes that constraint: Instead, by exploiting the GRO stage in the veth pair, the container virtual networking software can transparently aggregate UDP packets and forward them in the aggregate form for most of the virtual network topology, greatly reducing the overhead of forwarding.
Availability in Red Hat Enterprise Linux 8.5
So far, we have talked about the upstream Linux kernel project, but production deployments rarely use an upstream kernel. It's reasonable to ask when you'll be able to use all the enhancements described in this article in your preferred distro of choice? Very soon: All the relevant patches and features will land in the upcoming Red Hat Enterprise Linux 8.5.
Sounds great—your containerized UDP application will run twice as fast. Or not, since you have to enable something and you don't know what the heck to do. The next release of OpenShift Container Platform (OCP) will enable this feature, so the system administrator won't have to bother with additional setup. But if you can't wait, let's look at the gory configuration details.
Enabling UDP GRO hands-on
To enable GRO for UDP in a typical container virtual network setup, the sysadmin must:
Enable GRO on the veth peer in the main network namespace:
VETH=<veth device name> CPUS=`/usr/bin/nproc` ethtool -K $VETH gro on ethtool -L $VETH rx $CPUS tx $CPUS echo 50000 > /sys/class/net/$VETH/gro_flush_timeoutEnable GRO forwarding on that device:
ethtool -K $VETH rx-udp-gro-forwarding onEnable GRO forwarding on the NIC connected to the wire:
DEV=<real NIC name> ethtool -K $DEV rx-udp-gro-forwarding on
The first step requires some additional explanation. The veth device performs the GRO activity on a per receive queue basis. The ethtool -L command configures the number of active veth receive queues to match the number of CPUs on the host. That configuration prevents contention while scheduling and running GRO.
To allow the GRO engine to aggregate multiple packets, the veth needs to stage the eligible packets into the GRO engine. Traditional NICs implement this strategy in hardware on top of interrupt requests, but veth devices don't provide such a capability. Instead, with the provided settings, when a packet is staged into the GRO engine, the kernel sets a software timeout. When the timeout expires, the GRO engine is flushed. The echo command in step 1 configures the timeout in nanoseconds. The higher the timeout, the higher the chance that multiple packets will be aggregated—but at the expense of introducing a higher latency.
This example sets the timeout to 50 microseconds, which is high enough to aggregate a reasonable number of UDP packets under a significant load while keeping the added latency acceptably low for most applications. This value should likely work for all except strict, hard real-time environments.
After you issue the preceding commands, any containerized application using UDP transparently benefits from GRO forwarding.
Benchmarking GRO
We measured the gain of GRO by running the iperf tool at both ends of a connection in different compute nodes. Using a pair of nodes connected with a 10Gbps Ethernet link and a packet size equal to the allowed maximum transmission unit (MTU), we got the results shown in Figure 2. GRO showed a notable improvement in speed until we reached 16 or more concurrent flows, at which point even the vanilla kernel was able to reach the link speed limit. Even when the speeds were the same, CPU utilization with GRO forwarding was almost halved.

Conclusion
Successive Linux kernels have greatly reduced the penalty of using UDP, an improvement especially noticeable in containers. We recommend that you adopt Red Hat Enterprise Linux 8.5 or another distribution with an up-to-date Linux kernel and enable UDP TSO/GRO globally on your systems.
Last updated: October 8, 2024