In the context of Kubernetes, the exposure of Secrets for connecting applications to external services such as REST APIs, databases, and event buses is manual and bespoke. This action is usually referred to as binding. The process of configuring and maintaining the binding is error-prone and can lead to challenges and debug failures. Indeed, each service provider suggests a different way to access their Secrets, and each application developer in turn consumes those Secrets in a custom way for their applications.
Service Binding Operator 1.0, now in general availability (GA), expands the developer capabilities available on Red Hat OpenShift. As we'll see in this article, Service Binding Operator makes it easy for developers to connect their applications to backing services like REST APIs, databases, event buses, and others, providing a consistent and predictable experience.
Service Binding Operator overview
Service Binding Operator manages the data plane for applications and backing services. The Service Binding Operator eliminates the need to manage the error-prone manual configuration of binding information. It also grants developers a consistent and predictable experience when connecting their applications to backing services.
Today, when developers connect an application to a backing service, there is a fair amount of manual work to identify how and where to pull the different binding data. Each backing service has a different method and approach, which can create many discrepancies. Usually, developers have to follow an unreliable process to manually define and manage a whole set of Kubernetes resources, binding Secrets, ConfigMap, volume mounts, etc., that are specific to the environment into which the application is getting deployed.
The administrative cost required to provision and manage access to the backing service is also another aspect where Service Binding Operator helps both the developers and operators. Depending on your organization, Ops might need to be engaged to grant the developers access to the backing services. The burden this creates can be significant and result in hard-to-debug issues as well.
With Service Binding Operator, developers benefit from a self-service experience that connects their applications to the different backing services they need. It becomes transparent—as soon as the binding data is made available to the Service Binding data plane, developers can leverage them without being required to interact with the service providers or operators. This low-touch administrative flow facilitates developers' consumption of services and simplifies the service provider or operators' experience. Another benefit is the lifecycle of the credentials or binding data, which get updated often; the updates will be automatically reflected in the application.
Example scenario
Let's look at a simple scenario, in which we have a Spring Boot application and want to connect to a PostgreSQL database instance. In this configuration, we will use the Service Binding Operator to collect the binding data from the PostgreSQL database and project them into the Spring Boot application.
Note: In this example scenario, the PostgreSQL and Spring Boot applications have been both deployed before applying the binding.
Service Binding Operator introduces a new custom resource: ServiceBinding. In this resource, we can define the contract between the application and the backing service, and that's all that is needed.
apiVersion: binding.operators.coreos.com/v1alpha1
kind: ServiceBinding
metadata:
name: spring-petclinic-rest
namespace: my-postgresql
spec:
services:
- group: postgres-operator.crunchydata.com
version: v1beta1
kind: PostgresCluster
name: hippo
application:
name: spring-petclinic-rest
group: apps
version: v1
resource: deploymentsThis custom resource is enough to indicate to the Service Binding Operator to collect the binding data from the PostgreSQL database, create the binding secrets, and then inject the binding information into the applications.
Suppose that the Service Binding Operator was not present; the service provider's ops would need to extract all the configuration details and create a Secret resource to expose it to the application through volume mount in Kubernetes. Finally, the service provider's ops would have to make that available to the application developers. The steps are as follows:
- Identify the required values for connecting the application to the database.
- Locate the resources where the values are present.
- Take the values from different resources and create a Secret resource.
- Mount the Secret resource into the application.
- Depending on the application requirement, the values will be exposed as either environment variables or files.
Let’s see how it works with this intro video.
The Service Binding Operator projects the binding data into your application. To make this possible, the Service Binding Operator acts as a data plane between backing services and applications with the following two steps (illustrated in Figure 1):
- Extracting the binding data from the backing services.
- Projecting the binding data into the applications targeted.
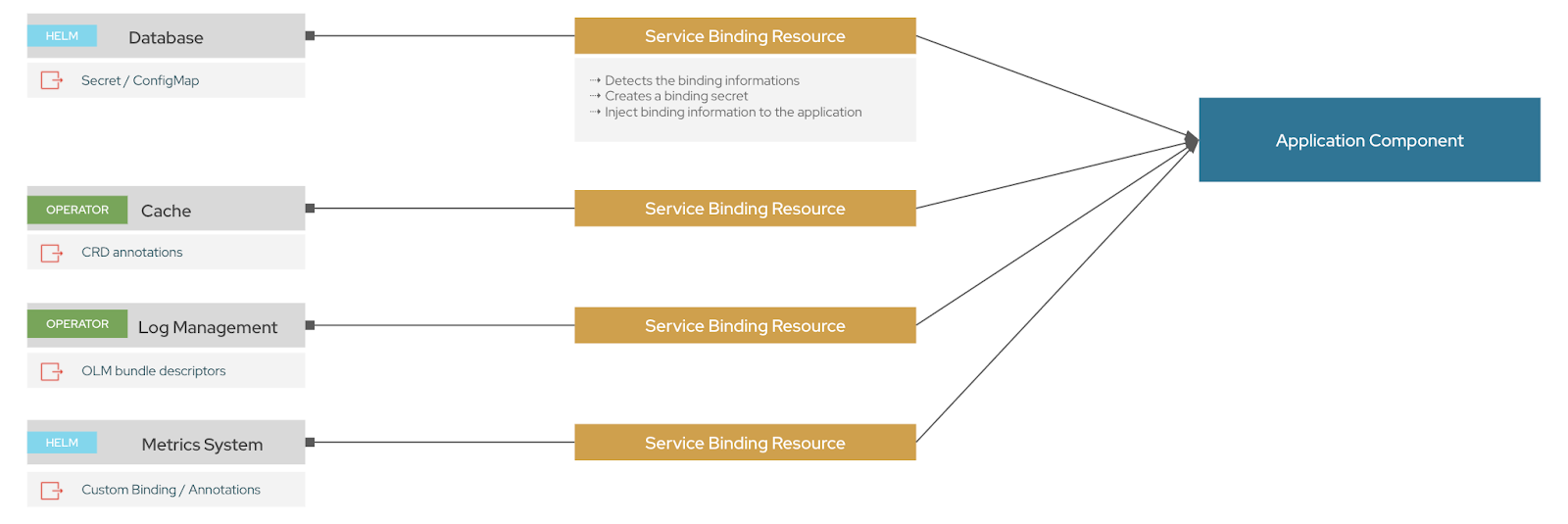
Extracting the binding data from backing services
To identify the binding data, the Service Binding Operator introduces different ways for a service provider or an administrator to provide the data considered to be "binding data":
- Annotations present in custom resource definitions (CRDs)/custom resources (CRs): Backing services can expose binding data by adding annotations to the description of the service. (Learn more.)
- Annotations present as Operator Lifecycle Manager (OLM) descriptors: Backing services provided by operators can describe the binding data directly in OLM descriptors. (Learn more.)
- Direct Secret Reference: When all the binding data is available in a Secret, it’s possible to just reference it in the binding definition. (Learn more.)
- Detection of binding data from resources: When the backing service owns Kubernetes resources such as Service, Route, ConfigMap, or Secret, the Service Binding Operator will look for those resources and detect the binding data. (Learn more.)
- Provisioned Service: The service you intend to connect to is compliant with the Service Binding specification and the detection of all the binding data values is automatic.
Using one of the proposed methods, an administrator can enable the different services managed to be more easily consumable by application developers.
We expect more and more services to provide those capabilities out-of-the-box with their Kubernetes Operators and to become Provisioned Services, compliant with the Service Binding specification. The services will need to be built with the proper annotation and descriptions that will enable the Service Binding Operator to detect the binding data. If you are interested in learning how you can make your service compliant with the Service Binding specification and become a Provisioned Service, please reach out to our team.
New Service Binding Operator capabilities enable it to automatically recognize certain well-known and frequently used services without requiring an administrator to alter the description of the service. We call this the Registry for the Service Binding. Here is the initial list of operators that the Service Registry for Service Binding provides compatibility with:
- Percona Distribution for MongoDB: Bindable with
PerconaServerMongoDB.psmdb.percona.com/v1-9-0andv1-10-0services.- Note: Provides administrative access to the cluster by default.
- Crunchy Postgres for Kubernetes: Bindable with
PostgresCluster.postgres-operator.crunchydata.com/v1beta1services. - OpsTree Redis: Bindable with
Redis.redis.redis.opstreelabs.in/v1beta1services. - RabbitMQ Cluster Kubernetes: Bindable with
RabbitmqCluster.rabbitmq.com/v1beta1services. - Cloud Native PostgreSQL: Bindable with
Cluster.postgresql.k8s.enterprisedb.io/v1services. - Percona XtraDB Cluster: Bindable with
PerconaXtraDBCluster.pxc.percona.com/v1-8-0andv1-9-0services.
The Registry for Service Binding is provided as a tech preview component in the Service Binding Operator.
Red Hat OpenShift Streams for Apache Kafka is also compliant with the Service Binding Operator, making it easier for application developers to leverage those in their applications. You can learn more about it and try it out on the free Developer Sandbox for Red Hat OpenShift.
Projecting and using the binding data in the application
To project the binding data in an application, a developer needs to express the binding intent by creating the ServiceBinding resource. At that moment, the Service Binding Operator will create a binding Secret and inject it into the application.
There are two ways the injection can be done:
- As files, which is the default behavior; or
- As environment variables, if the value for the
.spec.bindAsFilesparameter is set tofalsein theServiceBindingresource.
The primary mechanism of projection is through files mounted at a specific directory. The binding data directory path can be discovered through the SERVICE_BINDING_ROOT environment variable injected in your application.
Within this service binding root directory, there can be multiple binding data projected through different ServiceBinding resource reconciliations. For example, an application requires a connection to a database and a cache server. In that case, one Service Binding could provide the database, and the other Service Binding could provide binding data to the cache server.
$SERVICE_BINDING_ROOT
├── account-database
│ ├── type
│ ├── provider
│ ├── uri
│ ├── username
│ └── password
└── transaction-event-stream
├── type
├── connection-count
├── uri
├── certificates
└── private-keyIn the previous example, there are two binding data directories under the SERVICE_BINDING_ROOT directory. The account-databaseand transaction-event-stream are the names of the binding data.
For accessing binding data within SERVICE_BINDING_ROOT, language or framework-specific libraries have been made available by the community:
- Python: https://github.com/baijum/pyservicebinding
- Go: https://github.com/baijum/servicebinding
- Java/Spring: https://github.com/spring-cloud/spring-cloud-bindings
- Quarkus: https://quarkus.io/guides/deploying-to-kubernetes#service-binding
- JavaScript/Node.js: https://github.com/nodeshift/kube-service-bindings
- .NET: https://github.com/donschenck/dotnetservicebinding
Availability
The Service Binding Operator is now available as GA. It is supported on Red Hat OpenShift 4.7, 4.8, and 4.9. On Red Hat OpenShift, the Service Binding Operator is available from the Red Hat Catalog.
The Service Binding Operator is also compatible with Kubernetes and available to the community through OperatorHub.
List of features in Service Binding Operator 1.0
Service Binding Operator includes the following capabilities:
Application projection:
- Projection of binding data as files, with a volume mount.
- Projection of binding data as environment variables.
Extracting binding data from Services:
- Extract binding data based on annotations present in CRDs/CRs/resources.
- Extract binding data based on annotations present in OLM descriptors.
Service binding options:
- Cross-namespace binding.
- Binding to a specific container of an application.
- Custom path projection.
- Secret substitution and mappings with Go Template.
- Auto-detection of bindings in the absence of binding decorators.
- Binding of
PodSpecor non-PodSpecworkloads. - Custom binding variables composed from one or more backing services.
Security:
- Role-based access control (RBAC) support.
Service Binding Operator and OpenShift developer tools
Service Binding Operator is leveraged in the different tools provided for Red Hat OpenShift. Developers can benefit from a simplified experience when binding their applications to backing services. This can be accomplished with different tools, such as the developer command-line interface (CLI), IDE plug-ins for OpenShift, and the OpenShift developer console.
odo: The OpenShift developer CLI
odo is the Red Hat OpenShift CLI for developers. It lets developers concentrate on creating applications without needing to administer an OpenShift Container Platform cluster itself. Creating deployment configurations, build configurations, service routes, and other OpenShift Container Platform elements are all automated by odo.
You can use odo to create a Binding connection from the CLI between your application’s components and backing services:
First, you need an application component:
$ odo create my-nodejs-appSecond, get the list of different services that are available for the application component:
$ odo catalog list services$ odo service create postgresql-operator my-postgresqlFinally, link the backing service to the application component:
$ odo link my-postgresql --component my-nodejs-app
Red Hat OpenShift developer console
For developers using the Red Hat OpenShift developer console, the Service Binding Operator is made available from the topology view. That view allows you to visualize your application's component and the different services you are using.
You can actually use the topology view to create the binding connection between the application and the backing service. To do that, you can simply hover your application component, select the arrow that appears once hovered, and drag-and-drop it onto the backing service or component you want to connect to (see Figure 2).
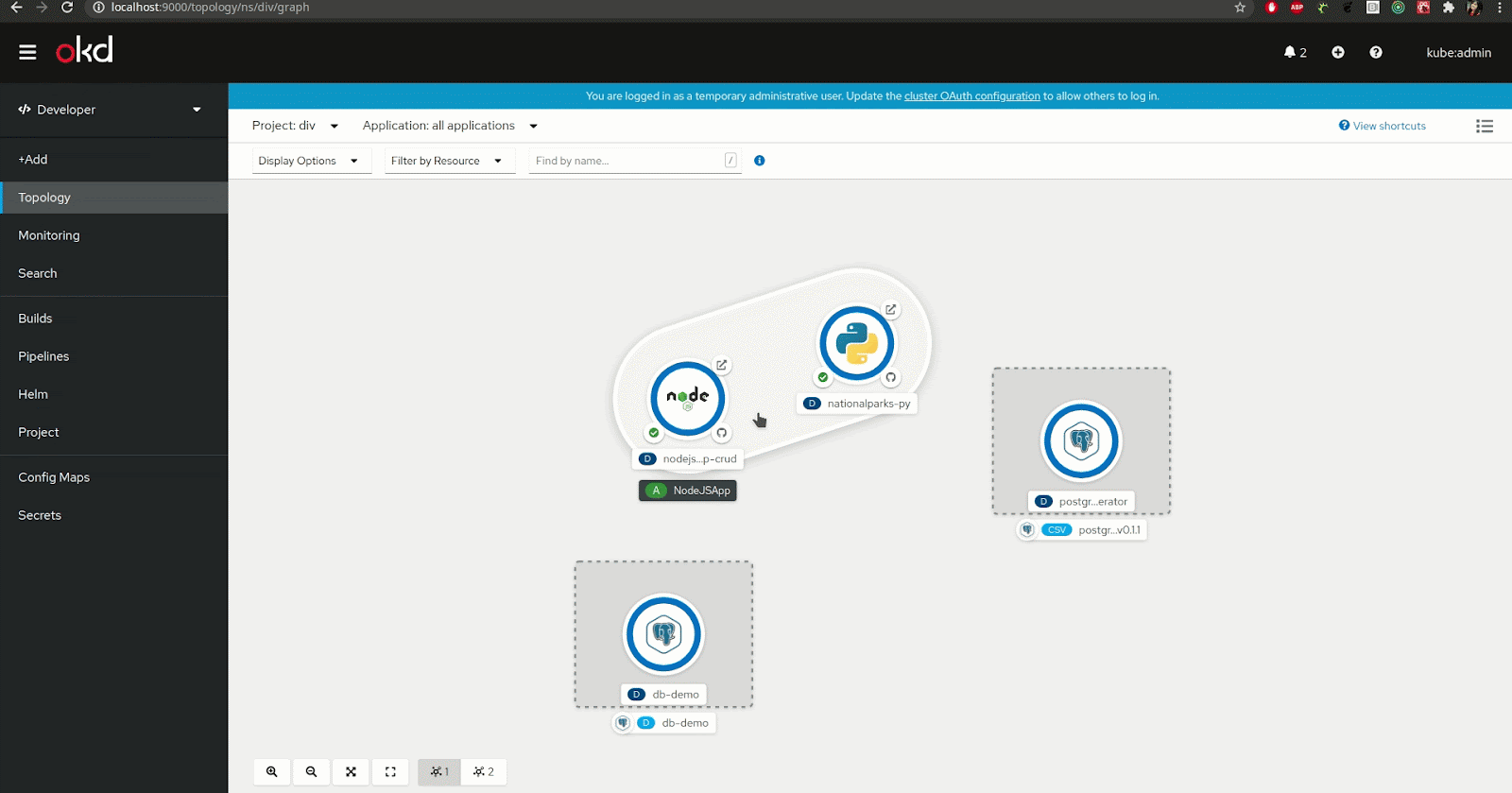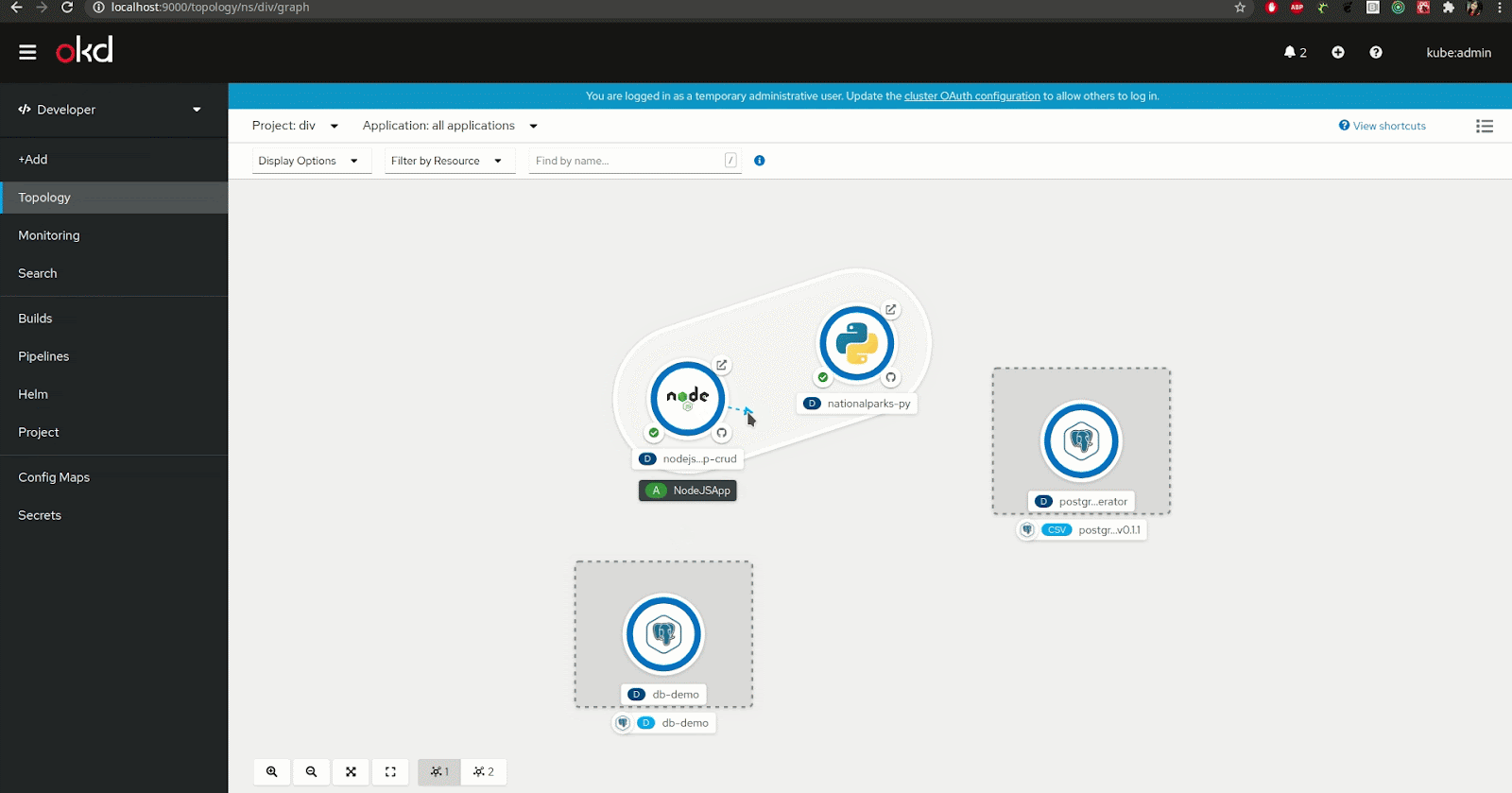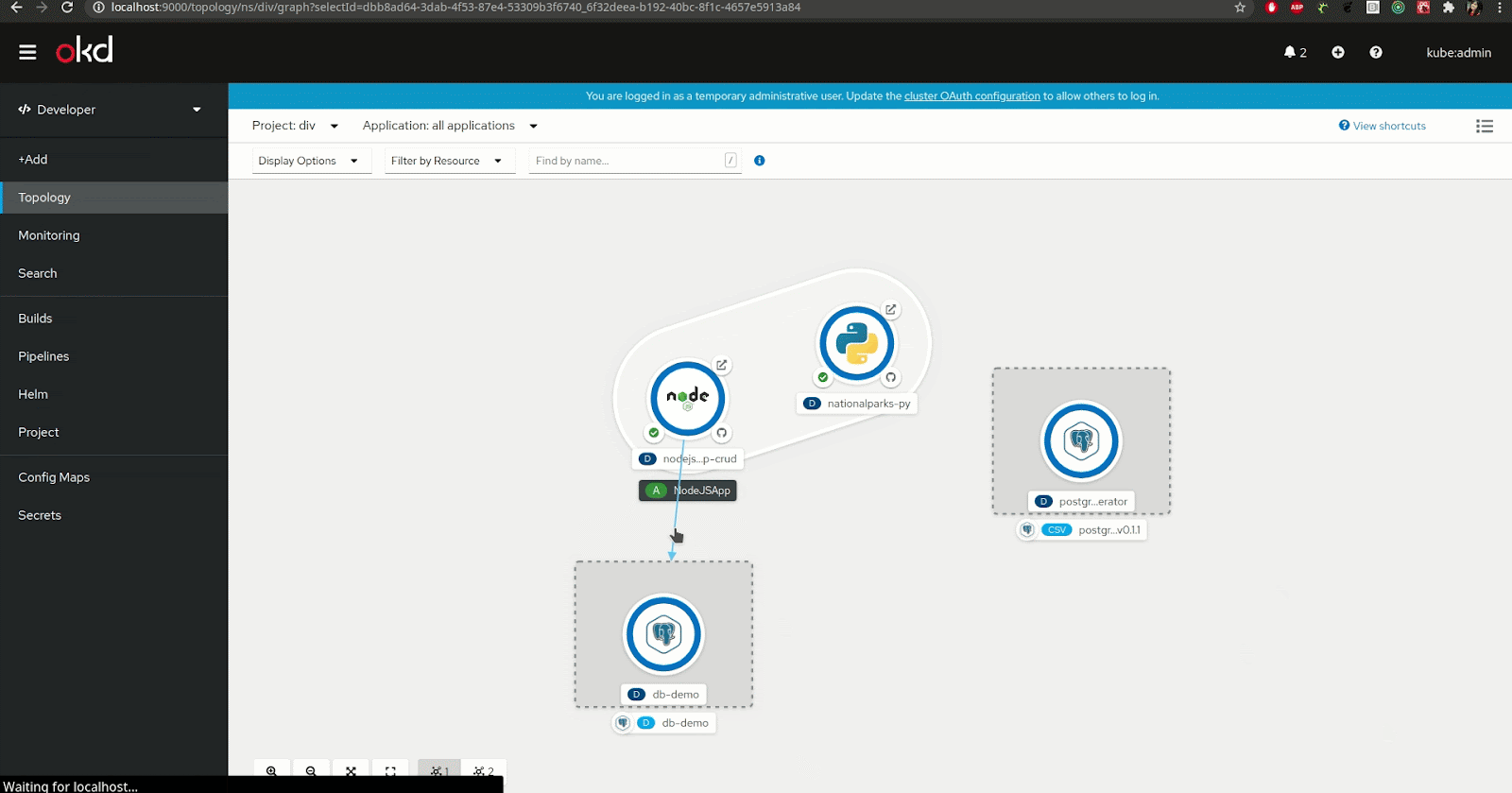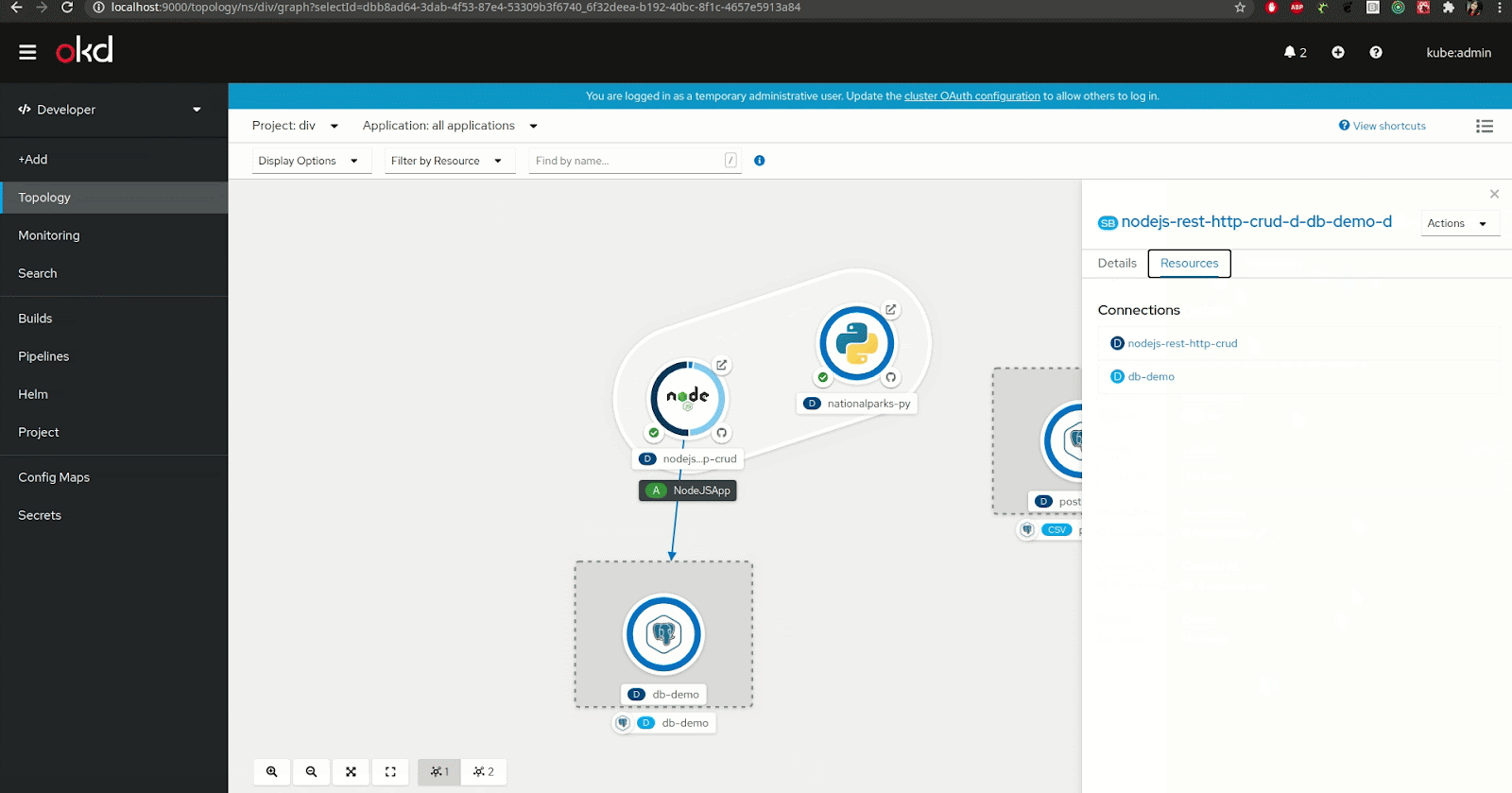
Note: The creation of this binding connection is only available when the backing service is "Service Binding compliant," meaning that it is either a service that is recognized automatically by Service Binding Operator or the definition of the binding data has been added to the resource description of the service.
The future of Service Binding Operator
We believe Service Binding Operator provides a great way to improve the developer experience when an application needs to be connected to backing services in the context of Kubernetes. There is a certain level of complexity and manual effort required today—and that's even more challenging in the context of applications leveraging more and more of the managed services.
As a result, the Service Binding Operator will become a core building block for how services are exposed and consumed by the developers on OpenShift. More tools, experiences, and developer-centric workflows will rely on it in the future.
Service Binding community
At Red Hat, we believe in creating better technology through the open source model and the innovation driven by the open source community. Red Hat is an active participant in the Service Binding working group that is working on a core specification around Service Binding on Kubernetes. Together, with the help of engineers from VMware, IBM, and other companies, we aim to make Service Binding a core citizen of the Kubernetes ecosystem.
The Service Binding Operator 1.0 is compliant with the Service Binding Specification.
If you are interested in getting involved with this effort, you can start with the following resources:
- Check out the Service Binding Specification repository.
- Join the biweekly working group call.
- Follow the discussions on GitHub issues and the #bindings-discuss channel in the Kubernetes Slack channel.
Getting started with the Service Binding Operator
Install the Service Binding Operator through the OperatorHub in OpenShift 4.9 and follow this Getting Started guide for a quick introduction.
For more details, check out the following resources:
Last updated: September 26, 2024