

When it comes to the process of optimizing a production-level artificial intelligence/machine learning (AI/ML) process, workflows and pipelines are an integral part of this effort. Pipelines are used to create workflows that are repeatable, automated, customizable, and intelligent.
An example AI/ML pipeline is presented in Figure 1, where functionalities such as data extract, transform, and load (ETL), model training, model evaluation, and model serving are automated as part of the pipeline.

Figure 1: AI/ML example pipeline.">
The attributes and features of an AI/ML pipeline are many, including the following:
- Automation: The ability to automate the workflow steps without any manual intervention.
- Repeatability: The ability to repeat steps such as re-training a model or re-evaluating a model with only input parameter changes.
- Artifact passing (input, output): The ability to pass data between workflow steps, sometimes if conditions and loops are dependent on this data.
- Triggers: The ability to automate triggering a workflow, without manually starting the pipeline. Triggers such as calendar events, messaging and monitoring events are used in many use cases.
- Multi-cluster: The ability to run a pipeline spanning multiple clusters such as the case in Hybrid Clouds. In many use cases, data resides in a different cluster than where processing takes place.
- Step or DAG (Directed Acyclic Graph) features: Most comprehensive pipelines require a DAG structure with features such as targets, parallel processing, conditionals, loops, pause/resume, timeouts, and retries.
There are many AI/ML pipeline tools today, and the most popular native Kubernetes tools are Argo and Kubeflow pipelines. In the next sections, we will describe using Open Data Hub and Kubeflow pipelines, both of which use Argo as the AI/ML pipeline tool.
Open Data Hub
Open Data Hub (ODH) is an open source end to end AI/ML platform that runs native to Red Hat OpenShift. Open Data Hub is a meta operator that includes many tools needed for end-to-end AI/ML development and production workflows and can be installed from Openshift 4.x Catalog Community Operators. For pipeline development, ODH includes an installation of the Argo workflow tool.
Argo workflow is an open source Kubernetes container-native workflow engine for orchestrating pipelines on Kubernetes. Pipeline steps are defined as native Kubernetes containers using YAML. A multi-step pipeline can be defined as a DAG with features such as input/outputs for each step, loops, parameterization, conditionals, timeouts (step & workflow level), and retry (step & workflow level). Argo defines a Kubernetes custom resource called workflow to create pipelines.
Integrating Argo into the ODH operator required writing an Ansible role that installs the required manifest for Argo. It also includes specific role-based access control (RBAC) for namespace bound installation and specifically uses “k8sapi” as executor as opposed to docker, as the default registry in Openshift is CRI-O. (CRI-O replaced the previously provided Docker engine in Openshift 4.x.) In the next section, we define the steps to install ODH and run an example Argo workflow.
Installing and Running ODH Argo
The basic requirement to install ODH is Red Hat Openshift 3.11 or 4.x. For step-by-step instructions, please follow the Open Data Hub Quick Installation Guide. However, in Step 4 for creating an instance of ODH, make sure to set “true” for Argo components are shown in Figure 2 below.

Figure 2: Specify "true" for Argo component in the CR(Custom Resource) file.">
After installation is complete, verify that Argo installed by checking the two pods created for Argo: argo-ui and workflow-controller. To launch the Argo UI portal, click on the Argo UI route in the networking section. For a simple test, we can run the "hello world" example provided by the Argo project. Create a hello-world.yaml file with the code below.
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: hello-world- spec: entrypoint: whalesay templates: - name: whalesay container: image: docker/whalesay:latest command: [cowsay] args: ["hello world"]
From a terminal, make sure you are in the ODH namespace and run:
oc create -f hello-world.yaml
Check the Argo portal to see the workflow progress and see the "hello world" log message. For a more comprehensive example, we provide an example DAG pipeline that includes a for loop, a conditional loop, parallel processing, and artifact access for remote S3 buckets. The workflow is shown in Figure 3, and the YAML file is also provided.
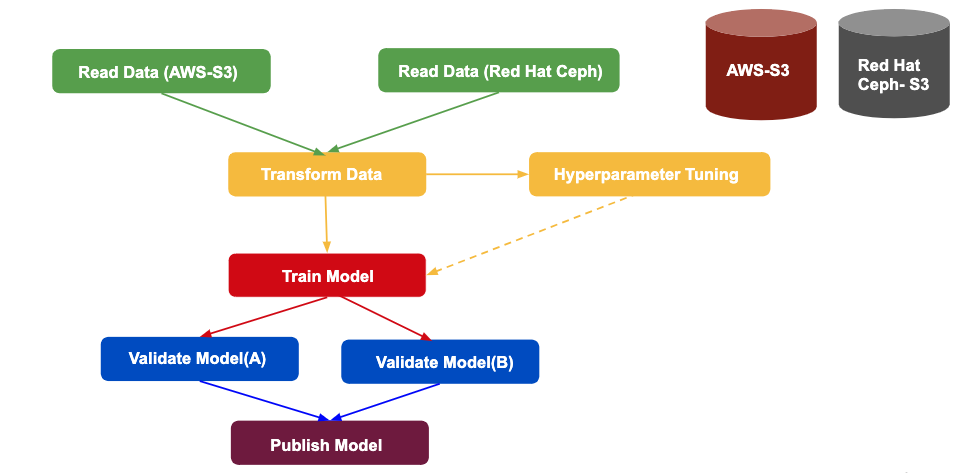
Figure 3: Example pipeline with for loop, a conditional loop, parallel processing, and artifact access for remote S3 buckets.">
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: frauddetection
spec:
entrypoint: fraud-workflow
serviceAccountName: argo-workflow
volumes:
- name: workdir>
emptyDir: {}
templates:
- name: echo
inputs:
parameters:
- name: message
container:
env:
- name: ACCESS_KEY_ID
valueFrom:
secretKeyRef:
name: keysecret
key: accesskey
- name: SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
name: keysecret
key: secretkey
- name: S3_ENDPOINT_URL
value: "insert s3 url"
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
- name: whalesay
container:
image: docker/whalesay:latest
command: [sh, -c]
args: ["sleep 1; echo -n true > /tmp/hyper.txt"]
- name: volumes-emptydir-example
container:
image: debian:latest
command: ["/bin/bash", "-c"]
args: ["
vol_found=`mount | grep /mnt/vol` && \
if [[ -n $vol_found ]]; then echo \"Volume mounted and found\"; else echo \"Not found\"; fi; sleep 1; echo -n true > /mnt/vol/hyper.txt"]>
volumeMounts:
- name: workdir
mountPath: /mnt/vol
outputs:
parameters:
- name: should-hyper
valueFrom:
path: /mnt/vol/hyper.txt
- name: fraud-workflow
dag:
tasks:
- name: Read-Data-AWS
template: echo
arguments:
parameters: [{name: message, value: Read-Data-AWS}]
- name: Read-Data-Ceph
dependencies:
template: echo
arguments:
parameters: [{name: message, value: Read-Data-Ceph}]
- name: Transform-Data
dependencies: [Read-Data-Ceph,Read-Data-AWS]
template: volumes-emptydir-example
- name: Hyper-Tuning
dependencies: [Transform-Data]
template: echo
when: "{{tasks.Transform-Data.outputs.parameters.should-hyper}} == true"
arguments:
parameters: [{name: message, value: Hyper-Tuning}]
- name: Train-Model
dependencies: [Transform-Data,Hyper-Tuning]
template: echo
arguments:
parameters: [{name: message, value: Train-Model}]
- name: Validate-Model
dependencies: [Train-Model]
template: echo
arguments:
parameters: [{name: message, value: "{{item}}"}]
withItems:
- hello world
- goodbye world
- name: Publish-Model
dependencies: [Validate-Model]
template: echo
arguments:
parameters: [{name: message, value: Publish-Model}]
From the workflow description, we can see that S3 settings are passed to template "echo" from an OpenShift secret. The if condition is implemented for the “Hyper-Tuning” step on condition that parameter “should-hyper” is true. This parameter is specified by the “Transform Data” step. The for loop example is shown in the “Validate model” step that runs twice, once with “hello world” and once with “goodbye world” as parameters to the container.
Using Kubeflow Pipelines
Kubeflow is an open source AI/ML project focused on model training, serving, pipelines, and metadata. The Kubeflow pipeline tool uses Argo as the underlying tool for executing the pipelines. However, Kubeflow provides a layer above Argo to allow data scientists to write pipelines using Python as opposed to YAML files. The project provides a Python SDK to be used when building the pipelines. Kubeflow also provides a pipeline portal that allows for running experiments with metrics and metadata for specific pipelines. This allows users to track and repeat experiments with specific metrics. For detailed information on Kubeflow project, please visit kubeflow.org.
As part of the Open Data Hub project, we have adapted and installed Kubeflow on OCP 4.x. Our work can be followed on the GitHub Open Data Hub project.
To run the "hello world" example workflow, there are two options: You can either run an experiment from the Kubeflow pipeline portal and upload the YAML file, or write the Python version of the workflow and compile it using the SDK then upload to the portal in an experiment.
For a comparison between a "hello world" example using YAML and Python, see Figure 4 below. As shown, every Python pipeline is translated to a YAML pipeline with metadata.
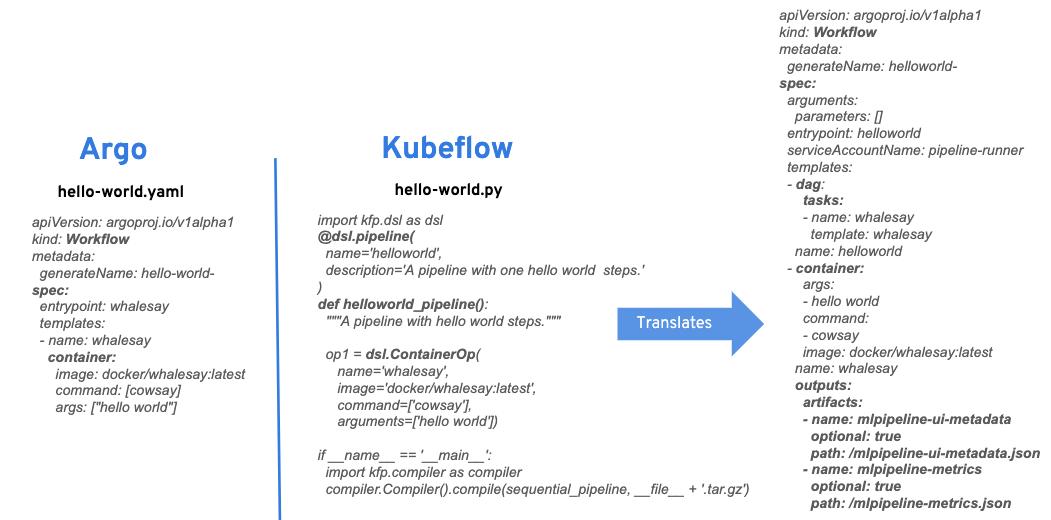
Figure 4: A comparison of the "hello world" pipeline between YAML and Python format.">
For a comparison between running YAML Argo workflows versus Kubeflow Python workflows, see Figure 5 with step-by-step instructions. As you can see, using Python requires compiling the code and storing it in a compressed tar.gz file that can then be uploaded to the Kubeflow portal.

Figure 5: Comparing Argo and Kubeflow pipeline creation.">
Future considerations
Many of the available AI/ML pipeline tools are missing some important features, such as triggers. The Argo project does include the Argo events tool that provides triggers to run workflows, but it is still in early stages. OpenShift cron jobs can be used to trigger workflows, but they do have limitations, such as triggering a workflow based on a messaging stream. Monitoring is also critical in managing a cluster and is provided by Argo as a metrics scraping interface for Prometheus; however, monitoring success or failure in a workflow is lacking. Multi-cluster pipelines are not currently available, but there is a tool from Argo in its early stages that allows running workflow steps in different clusters.
Last updated: July 24, 2023