About two years ago, Red Hat IT finished migrating our customer-facing authentication system to Red Hat Single Sign-On (Red Hat SSO). As a result, we were quite pleased with the performance and flexibility of the new platform. Due to some architectural decisions that were made in order to optimize for uptime using the technologies at our disposal, we were unable to take full advantage of Red Hat SSO’s robust feature set until now. This article describes how we're now addressing database and session replication between global sites.
Lessons from our first deployment
Red Hat IT’s initial launch of multi-site SSO had each site completely independent of the other. While this facilitated the platform’s high uptime, it also resulted in a number of limitations hampering some new technologies.
The most problematic limitation was that active login sessions were stored only at a single site—the one where a user happened to authenticate. This meant that if that particular site had an outage, the user would have to reauthenticate upon redirection to another site. Reauthentication lead to a confusing and poor customer experience, especially during rolling site maintenance.
Furthermore, this architecture prevented the adoption of the OpenID Connect (OIDC) authorization code flow, regardless of it being fully supported in the Red Hat SSO product. The authorization code flow partially relies on server-to-server communication rather than on a user’s browser, as in the case of SAML or other OIDC flows. It was probable that the backend server request would not be routed to the same site that contained the active user session. This would result in the backend authorization code flow failing, leading to intermittent UI errors, at best.
Finally, other features of Red Hat SSO, such as offline OpenID Connect tokens and two-factor authentication (2FA) were simply unusable in this multi-site environment. By default, when a user associates an offline token or a new 2FA device with their account, Red Hat SSO persists this in the database. Without database replication between sites, this new association persists only in a single site, preventing the technology from correctly functioning in this environment.
Because of these and other issues, we knew that the next step forward would have to address database and session replication between sites.
Working toward our future multi-site solution
Working with the Red Hat SSO development team, the multi-site use cases and objectives were detailed. The team explored a number of potential solutions and ended up with the Cross-Datacenter Replication Mode.
Deploying Cross-Datacenter Replication Mode requires two major modifications to the existing architecture of a Red Hat SSO deployment. The first is migrating our database to Galera Cluster and the second is deploying Red Hat Data Grid (formerly known as Red Hat JBoss Data Grid).
Migrating to Galera Cluster
Red Hat SSO already supports a number of databases, but the cross-datacenter replication mode requires synchronous replication between sites, ensuring data integrity and consistency across the entire deployment. For example, new user registrations at site A need to be immediately available at sites B and C to prevent additional duplicate user registrations and conflicting database records.
As of Red Hat SSO 7.2, the two solutions that have been tested in conjunction with the cross-datacenter mode are Oracle Database 12c Release 1 (12.1) RAC and MariaDB server version 10.1.19 with Galera; Red Hat IT’s deployment is using MariaDB with Galera Cluster. Each of the three sites has a pair of MariaDB Galera servers, so even in the event of a single site outage, we can still maintain a quorum majority.
The SSO clusters were already leveraging MariaDB as the RDBMS, but multi-site active/active required switching the entire cluster to Galera for cross-datacenter mode. Initially, each of the three sites had a pair of multi-master database hosts. Upgrading SSO clusters to Galera without an outage involved rolling through sites. The standard MariaDB multi-master replication would be disabled on each site’s DB cluster, and then the remaining DB servers were added to the Galera cluster. Following this, the local Red Hat SSO nodes were updated to use the DB servers now part of the Galera cluster. Finally, the last DB server was reinitialized and added to the Galera cluster.
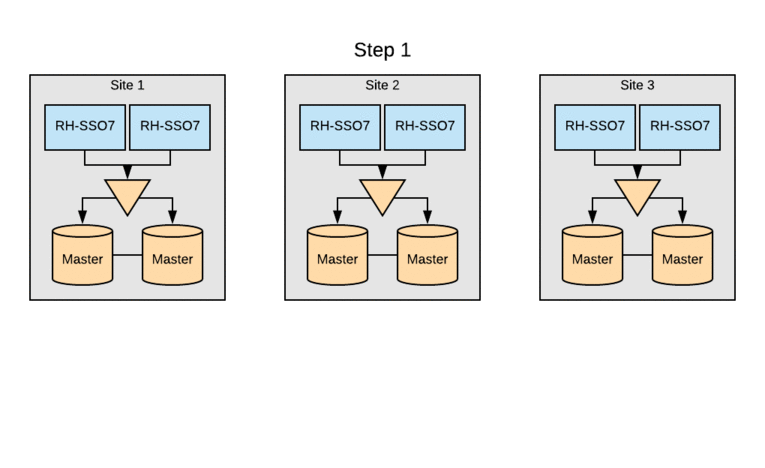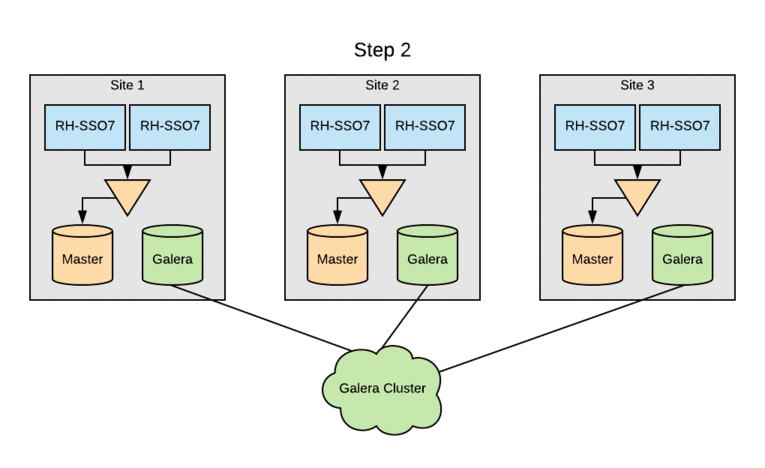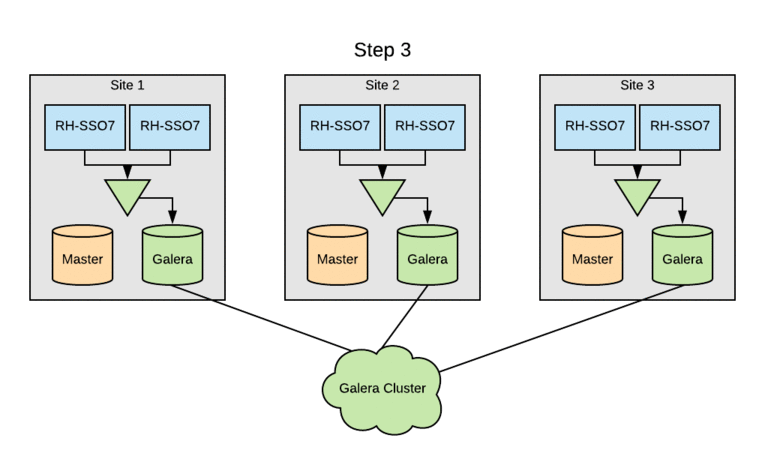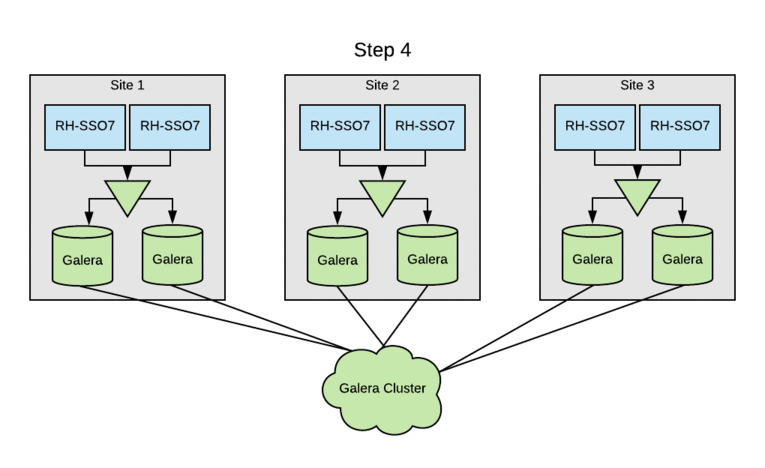
This process was done so that we could perform the upgrade with zero downtime in any of our sites. This was made possible because the user data is handled by a distinct service and not mastered within Red Hat SSO. Had this not been true, the upgrade would have been more complicated. The Galera DB upgrade was done prior to implementing Red Hat Data Grid, so system performance could be closely monitored and backed out, if necessary.
Deploying Red Hat Data Grid
Red Hat SSO utilizes Infinispan for session storage, which comes bundled with Red Hat JBoss Enterprise Application Platform. Red Hat Data Grid is the Red Hat supported version of Infinispan and has a standalone server distribution that is used in conjunction with JBoss EAP’s Infinispan to replicate cache data across all sites. Red hat Data Grid has explicit support for Cross Datacenter Replication and offloading the replication concerns to a separate server helps minimize performance impact. Each Red Hat SSO instance is configured to use a local Red hat Data Grid cluster as a remote store for Infinispan. In turn, each Red Hat Data Grid cluster is aware of all the other Red Hat Data Grid clusters at the other sites. The Red Hat Data Grid clusters in each site form a grid, as the name implies, and replicate the SSO session cache among all sites. The Red Hat Data Grid data replication can be asynchronous, if you have an active/passive multi-site Red Hat SSO deployment, or synchronous for active/active deployments. Each of the Red Hat SSO sites has a three-node Red Hat Data Grid cluster, which ensures cross-site replication survives any single node failing.
Deploying Red Hat Data Grid required building net-new clusters of Red Hat Enterprise Linux servers. Red Hat SSO does not support concurrently running Red Hat Data Grid and SSO on the same servers, nor would you want to do this. Creating and configuring these hosts was straightforward following the basic setup steps, with a few minor modifications for our own purposes. One of the modifications was using a separate TCP stack—running on different ports for the local channel rather than using UDP, because some cloud providers don’t support multicast. Another modification was the use of asymmetric encryption and authentication, ensuring that user session data was encrypted and never exposed on the wire.
The configuration changes to the existing Red Hat SSO hosts followed the basic setup steps with little-to-no modifications. The cleanest way to deploy these changes in this environment was to bring down a single site entirely, stopping the Red Hat SSO service across all SSO servers within a site. Configurations were then updated and the Red Hat SSO service was brought back up one host at a time. This procedure ensured that all entries in the local cluster cache would be present in the Red Hat Data Grid cache. Otherwise, errors were occasionally encountered when starting hosts, because they could not reconcile local cache contents with the remote-store Red Hat Data Grid contents. Following this procedure, active sessions were lost on a rolling basis, but no customer-facing outage was incurred.
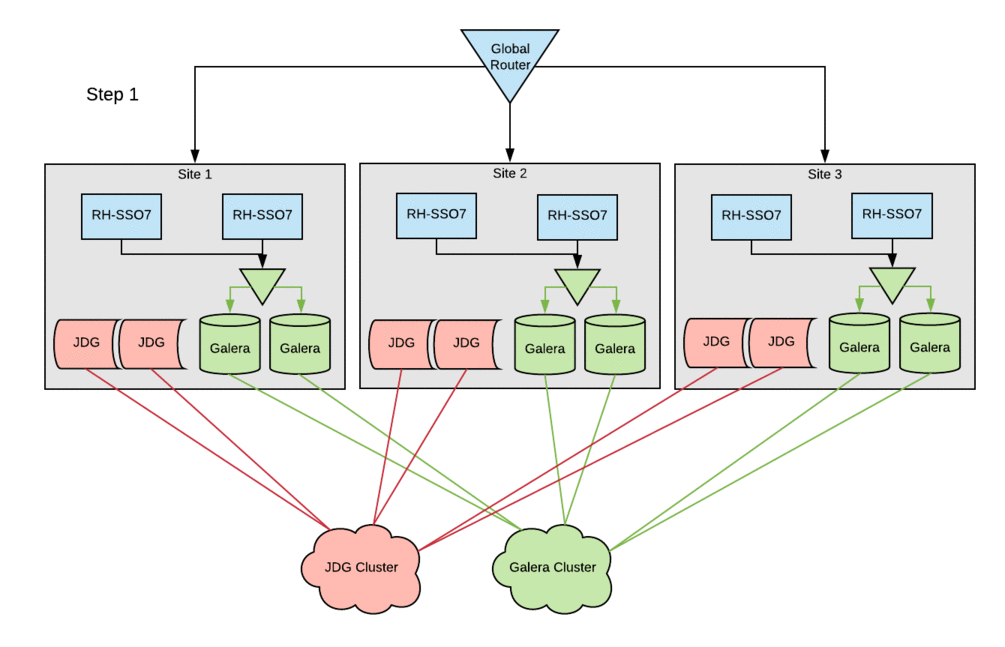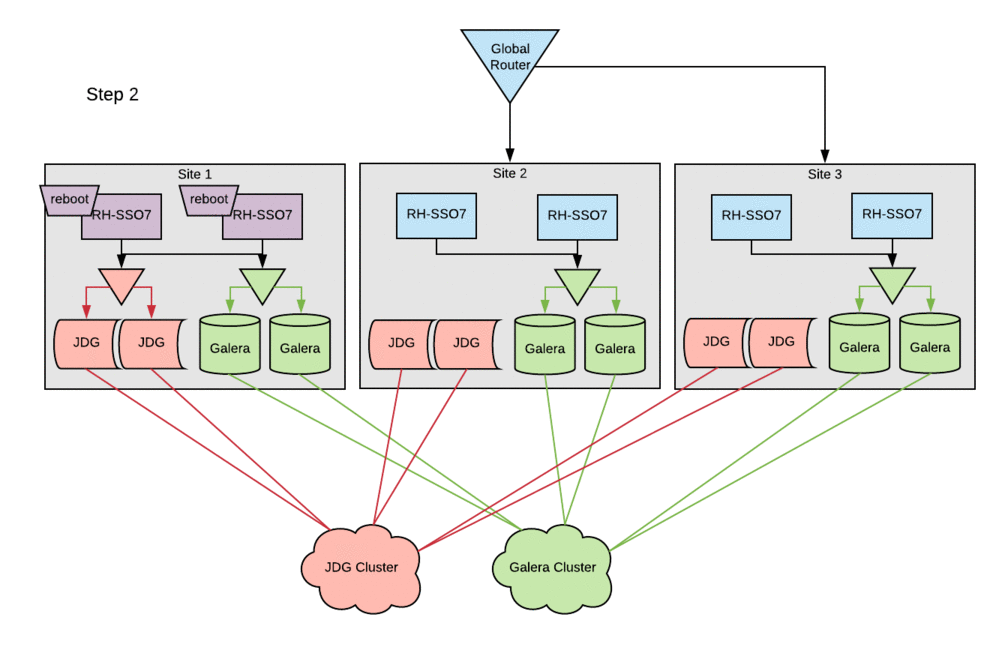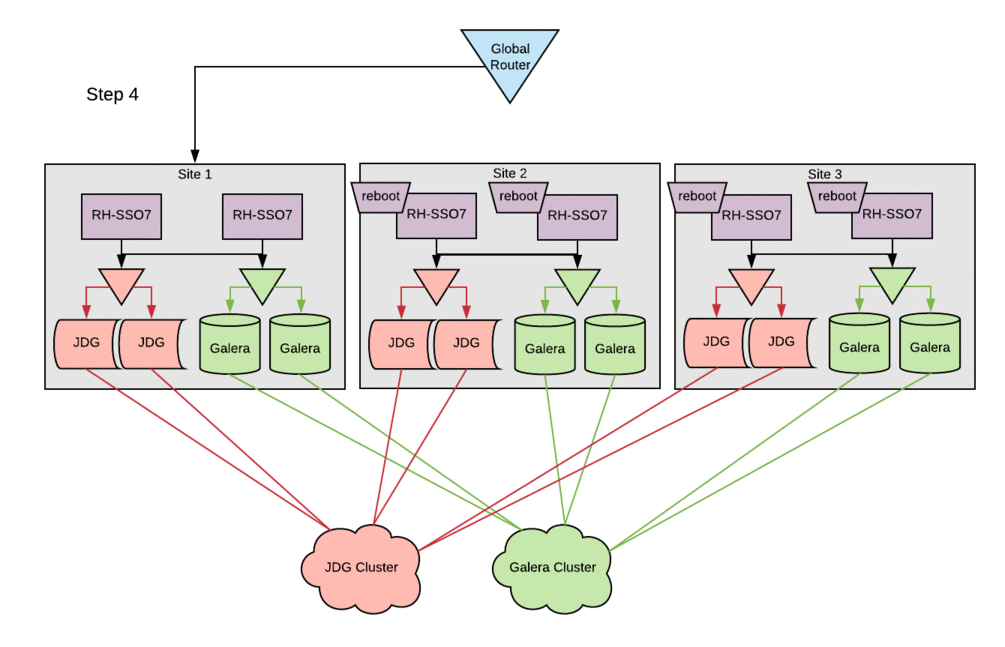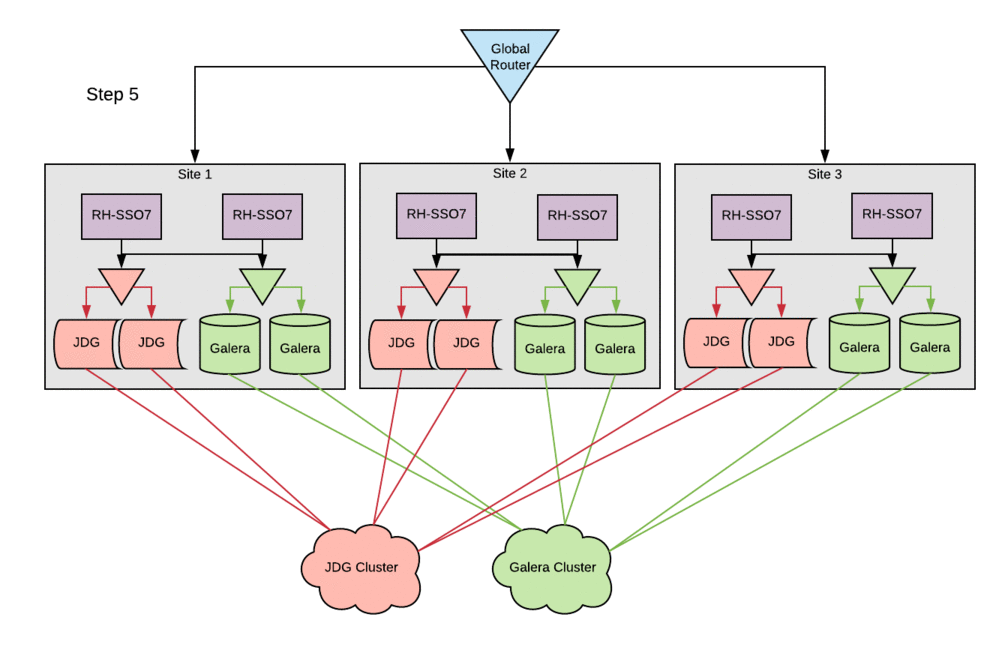
Measuring and monitoring performance
There were some initial concerns about the performance and stability of cross-site synchronous replication—both on the database level, as well as on the application cache level. Sufficient monitoring had to be in place to create an alert if performance degrades.
JMXtrans Agent is very useful for taking metrics typically exposed only via JMX Infinispan cache performance, garbage collection, and memory/thread utilization and aggregating them in a tool like Graphite. In combination with collectd and the Graphite plugin, it was easy to snapshot all relevant host statistics. Moreover, combining this with Dropwizard Metrics for instrumentation of all Red Hat SSO customizations gives a comprehensive view into the complete stack.
Groovy scripts are also a great way to quickly leverage any attributes or operations exposed via a JMX MBean. For example, internally we utilize a number of Groovy scripts. These are tied into monitoring and reporting the status of the CacheContainerHealth component, monitoring the memory levels, and alerting if garbage collection isn’t able to reclaim sufficient space, as well as checking the cross-site replication status for all the configured caches. These result in quick action if servers are suddenly unavailable. Groovy scripts also make it simple to automate more-complex procedures, such as initiating state transfer between sites after recovery has completed.
In conclusion, Cross-Datacenter Replication Mode for Red Hat SSO allows Red Hat IT to scale its authentication systems globally while providing an extremely high level of resiliency and availability. By leveraging supported, open source technologies, Red Hat has built a true multi-site single sign-on authentication platform capable of handling next-generation applications.
Additional resources
- Single Sign-On Made Easy with Keycloak/Red Hat SSO
- Securing apps and services with Keycloak/Red Hat SSO (DevNation Live Video)
- A deep dive into Keycloak/Red Hat SSO (DevNation Live Video)
- Red Hat Single Sign-On: Give it a try for no cost!
- How Red Hat re-designed its Single Sign On (SSO) architecture, and why
- Red Hat Single Sign-On Server Administration Guide
- Red Hat Single Sign-On Securing Applications and Services Guide
- Using a public certificate with Red Hat Single Sign-On/Keycloak
About the Author
Jared Blashka is a Senior Software Applications Engineer on the Red Hat IT Identity and Access Management team. He is a Red Hat Certified Engineer and has 8 years of experience, focusing on identity management, application lifecycle management, and automation.
Last updated: November 29, 2023