In part one of this series of blog posts, we discussed the importance of the user experience within the mobile industry, and how your API has a significant role in this. We followed up with part two, which demonstrates how to make API responses smaller and therefore use less network and fewer battery resources for mobile consumers.
In this post, we’ll outline a number of techniques that you can leverage on an mBaaS solution such as Red Hat Mobile Application Platform to reduce request-processing time or even remove the need to make a request entirely. In doing so, you can provide a significantly better user experience since a user will spend less time waiting on your API to return data, and also experience less battery drain and bandwidth usage on their device.
To reduce request-processing or remove the need to make requests, we’ll cover how you can:
- Utilize cache-control headers to reduce incoming requests from devices
- Write data to queues to defer processing and respond to users immediately
- Cache entire API responses and reuse them for subsequent requests
- Cache slow changing data which forms part of API responses
A node.js application that will be used for code samples is available here with a README that has instructions on how you can run it on your own machine.
Reducing Incoming Requests
Cache-Control Headers
Adding a cache control header is a neat way to reduce the number of requests your API needs to serve. The Cache-Control header is used by a web server to communicate to a client if the client -- in a short timeframe, can use the same resource again. Alternatively, you can use this header to instruct a client not to cache a response! Typically, the time a response can be reused for is represented by a number of seconds in this header. Most content delivery networks (CDN) make use of this header to reduce the load on their servers and improve website load times.
If we take our previous example of the GET to /jobs, we can see how using cache-control could be a valuable optimization since this endpoint triggers a request to our dummy ESB and multiple requests to fetch weather information - not a cheap operation! Let's assume that the ESB only updates job information every 5 minutes at most and we make a request for the jobs at 3:30 PM, in this case, the server might return a cache control header to instruct a device not to request the jobs again for 5 minutes.
Setting this header is simple in an RHMAP application since it's built using express. Here's a modified version of our GET jobs/ route that sets the cache control header before responding:
esb.getJobs() .then(getWeatherForJobs) .tap(function () { log.info('got jobs and weather, now responding'); }) .then((jobsWithWeather) => stripUnusedFieldsFromJobs(jobsWithWeather)) .tap(() => { // This response can be considered stale after 5 minutes res.set('cache-control', `max-age=${(5 * 60)}`); }) .then((formattedJobs) => res.json(formattedJobs)) .catch(next);
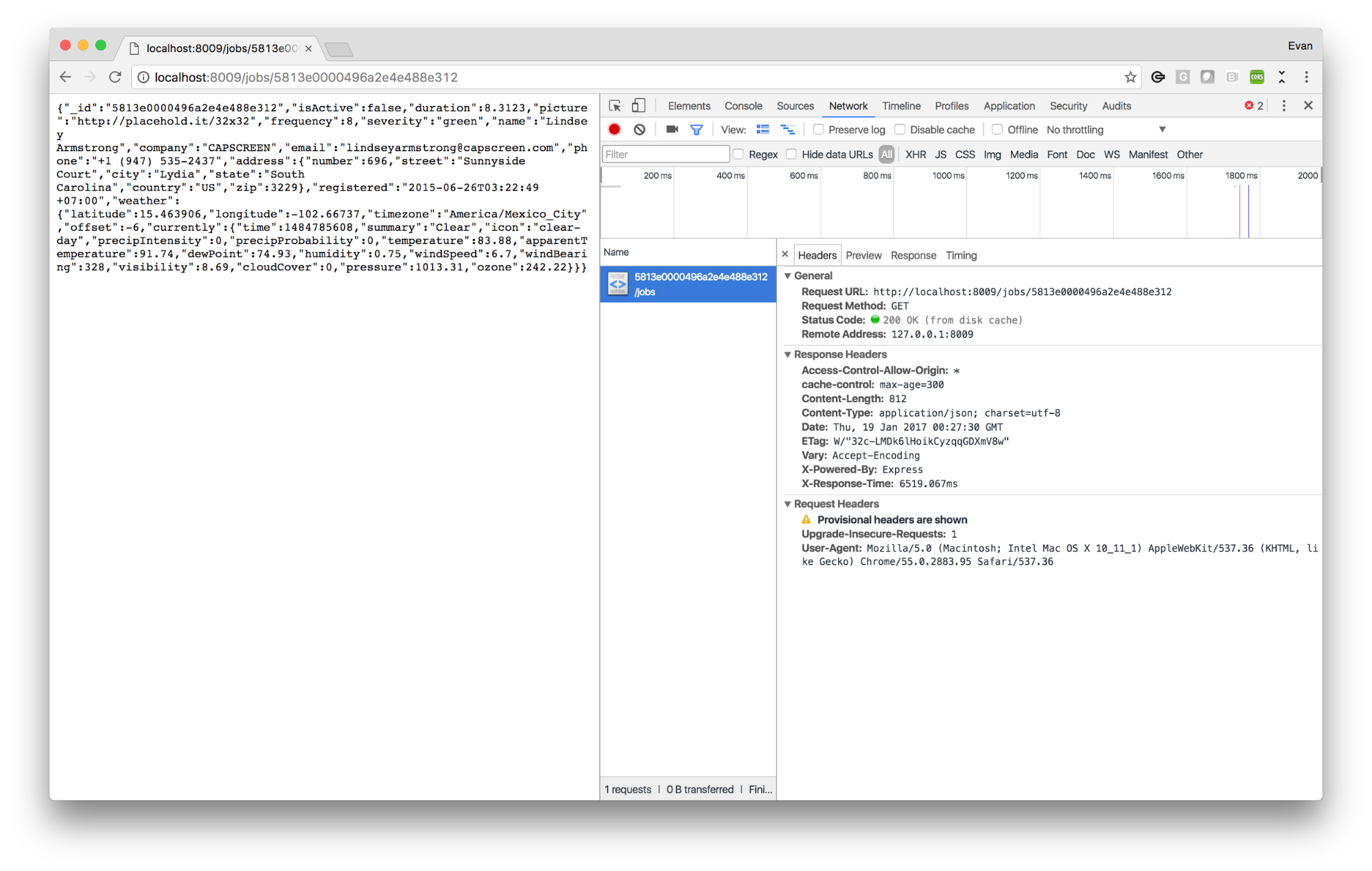
A browser that receives this response will not request this resource again for another 5 minutes (300 seconds), and will instead return a locally cached copy of the data when your application requests it. The result of this is the appearance of instantaneous response times for end users, reduced battery and bandwidth usage for mobile clients, and reduced load on your servers - a win/win situation! We can see this in action in Chrome using our Network inspector - note the “(from disk cache)” label next to the Status Code field in the image below:
Reducing Request Processing Time
If we think about a very simplified lifecycle of an HTTP request it might look a little like this:
- DNS Lookup
- Sending the HTTP payload to a resolved address
- Waiting for the server to process the response
- Server sends a response to the client
- Client parses and uses the response
Our web server can only influence step 3 here, everything else is beyond its control. Typically, applications running on RHMAP communicate with external systems of record such as an ESB, Mongo database, and the file system on the application container. Performing I/O to these components has a direct effect on the overall response time you can provide. In this section, we'll cover some techniques you can use to reduce request processing time in your RHMAP application.
Queue Operations for Later Execution
For most API calls you need to perform a number of I/O bound operations to generate a response to the calling client. In some scenarios, it isn’t necessary for a client to wait for these to complete. Often, the client simply needs acknowledgment that the server has received the request and will process the payload, so why make a client wait for the actual processing to complete? Let’s take an example of a notification endpoint that sends a text message on behalf of the client. It might look something like so:
route.post('/:number', function (req, res, next) { const number = req.params.number; if (!req.body.message) { return res.status(400).json({ status: 'please include a "message" in the request body' }); } log.info('sending text to %s', number); text.sendText(number, req.body) .then((successStatus) => res.json(successStatus)) .catch(next); });
Using the above code, a device might need to wait a significant amount of time if the system invoked by text.sendText is experiencing high load. Ultimately, the mobile device does not care to wait all this time if the server can acknowledge it received the payload and will send the text within a reasonable period.
Node.js applications running on RHMAP have a dedicated MongoDB, so instead of waiting on the text.sendText function before responding to a client HTTP request, we can write the request to MongoDB and have a timed job that will frequently attempt to send any queued texts in the database.
// Queue the message in the database and respond once we’ve done so // to let the device know we’ll send it ASAP text.queueMessage(number, req.body) .then((status) => res.json(status)) .catch(next);
The end result here is the same for our users, but the response time from your chosen text messaging provider will no longer negatively affect your ability to provide reasonable response times for users. In the screenshot of a Postman HTTP request below, we can see it took just 37ms to post our message to the server and get a response saying the message would be sent.

Caching HTTP Responses
Simple and seamless is the easiest way to describe HTTP caching for an RHMAP application. Since our node.js applications are built using express, it's trivial for us to include a middleware in our application that will cache responses and return them for subsequent calls for the same resource. This means the processing time for a request is eliminated since loading from an in-memory cache is orders of magnitude faster than performing disk or HTTP I/O. For a visualization of the speed difference, check out this link, in particular, the time difference when reading from memory vs. disk.
So, how does our dummy server perform without any caching implemented? We can see that in a load test using the loadtest module from npm our server averaged 2.84 requests per second where we were running at a concurrency level of 25 requests for a total time of 49.67 seconds to serve 150 requests. The shortest request was 7.5 seconds and the longest was 10.2 seconds. Remember this is due to our simulated delays and not an issue with node.js or JavaScript!
$ loadtest -n 150 -c 25 http://127.0.0.1:8009/jobs/5813e000f10440718b6744a5 Target URL: http://127.0.0.1:8009/jobs/5813e000f10440718b6744a5 Max requests: 150 Concurrency level: 25 Agent: none Completed requests: 150 Total errors: 0 Total time: 49.676784575999996 s Requests per second: 3 Mean latency: 7686.8 ms Percentage of the requests served within a certain time 50% 7550 ms 90% 9831 ms 95% 10132 ms 99% 10206 ms 100% 10209 ms (longest request)
Let’s add a caching layer to our application and see how much better we can do! We’re going to use the expeditious module, but other great alternatives such as apicache exist. Adding expeditious to an express application is simple since an express middleware named express-expeditious already exists. We create a file named router-cache.js and add the following:
// cache instance that our middleware will use const expeditiousInstance = require('expeditious')({ namespace: 'httpcache', // needs to be set to true if we plan to pass it to express-expeditious objectMode: true, // Store cache entries for 1 minute defaultTtl: 60 * 1000, // Store cache entries in node.js memory engine: require('expeditious-engine-memory')() }); module.exports = require('express-expeditious')({ expeditious: expeditiousInstance });
Then we require this file and apply it to our express jobs router as a middleware:
const cache = require('lib/router-cache'); app.use('/jobs', cache, require('lib/routes/jobs'));
Now our server will cache the responses for any GET call to the /jobs endpoint and automatically respond with the cached data for the time we configured as the defaultTtl for expeditious.
After we add caching the results become significantly better allowing for throughput of 24 requests per second and the entire test completes within 6.25 seconds. We’ve effectively increased throughput by a factor of 8 thanks to reduced request processing time. The response time for most requests is also less than 5 milliseconds!
$ loadtest -n 150 -c 25 http://127.0.0.1:8009/jobs/5813e000f10440718b6744a5 Target URL: http://127.0.0.1:8009/jobs/5813e000f10440718b6744a5 Max requests: 150 Concurrency level: 25 Agent: none Completed requests: 150 Total errors: 0 Total time: 6.2454407430000005 s Requests per second: 24 Mean latency: 249.2 ms Percentage of the requests served within a certain time 50% 3 ms 90% 6 ms 95% 7 ms 99% 6178 ms 100% 6215 ms (longest request)
Caching Calls to a System of Record
As an mBaaS, RHMAP is often tasked with integrating with multiple systems of record to serve just a single HTTP request for a mobile device. While data in some of these systems might change frequently, other pieces of data can remain unchanged for extended periods. This means we cannot cache the entire HTTP response as we did in the above example, but we can still cache parts of the request to reduce overall processing time.
In our sample repository, the GET /jobs/:jobId endpoint is a typical candidate for this partial caching since it does not just talk to the ESB, but also requests weather from the Dark Sky weather API. A customer might always want the latest job data returned, but for weather, we might only care about seeing updates every 15 minutes so it’s almost obvious we should cache the weather!
To do this we’ll modify our getWeatherForJob function to first check if the RHMAP cache contains the weather for a given job location and use that if it exists, otherwise we will fall back to calling the Dark Sky API.
exports.getWeatherForJob = function (job) { const url = buildRequestUrl(job); log.info('getting weather for job via url %s', url); return loadWeatherFromCache(url) .then((weather) => { if (weather) { log.debug('got weather from cache - %s', url); // Weather came from redis - nice! return weather; } else { log.debug('getting weather from ds api - %s', url); // Need to get weather from the ds api return requestWeather(url) .then((weather) => saveWeatherToCache(url, weather)); } }); };
Summary
Utilizing these techniques can significantly reduce the load on your servers, reduce response time, and improve the user experience for API consumers as a result. Better yet, it doesn’t require a significant amount of effort to implement these techniques for many APIs so it’s a worthy investment of development time.
If you’d like to see the code after adding the enhancements in this post you can find it here. For a change set between the initial code and final code look here.
Join Red Hat Developers, a developer program for you to learn, share, and code faster – and get access to Red Hat software for your development. The developer program and software are both free!
Red Hat Mobile Application Platform is available for download, and you can read more at Red Hat Mobile Application Platform.
Last updated: October 31, 2023