Microservices Are Here, to Stay
A few years back, most software systems had a monolithic architecture and slow release cycle. In the recent years, there is a clear move towards Microservices architecture, which is optimized for scalability, elasticity, failure, and speed of change. This trend has been further enforced by the adoption of cloud and containers, which also enabled practices such as DevOps.
 |
| Trends in the IT Industry |
All these changes have resulted in a growing number of services to develop and an even bigger number of deployments to do. It soon became clear that the explosion in the number of deployments cannot be controlled using pre-microservices tools and techniques, and new ways have been born. In this article, we will see how Cloud Native platforms such as Kubernetes allow deployment of Microservices in high scale with minimal human intervention.
Cloud Native Deployment Traits
Self-Service Environments
Local, Dev, Test, Int, Perf, Stage, Prod.... are all environments, but what is an environment really? Usually, it is a VM or a group of VMs that represent an environment. For example:
Local is the developer laptop where the user has full freedom to experiment and break stuff. It still has to be similar to other environments to avoid the "it works on my machine" syndrome.
Dev is the very first environment where changes from all developers are integrated into one working application. It runs SNAPSHOT version of the services, has mocked external dependencies, and for most of the time, it is broken from constant change.
Once a service has been released, it is moved to a more stable environment such as Test. This environment may be slightly more powerful (maybe have more than one VM), may have more external services available rather than mocks, and it also has testers accessing it.
While the environments get closer to production environment such as Int/Stage/Perf, they get bigger, with more VMs and more external dependencies available. At some point, we probably need an environment that has resources quantifiable with the production environment so we can do performance tests that mean something in relation to the production environment.
The main difficulty with this model is that the concept of environment is mapped to physical or virtual VMs and as such, it is slow to alter. You cannot easily change the resource profile of an existing environment, create new environments, or give an environment per developer on the fly.
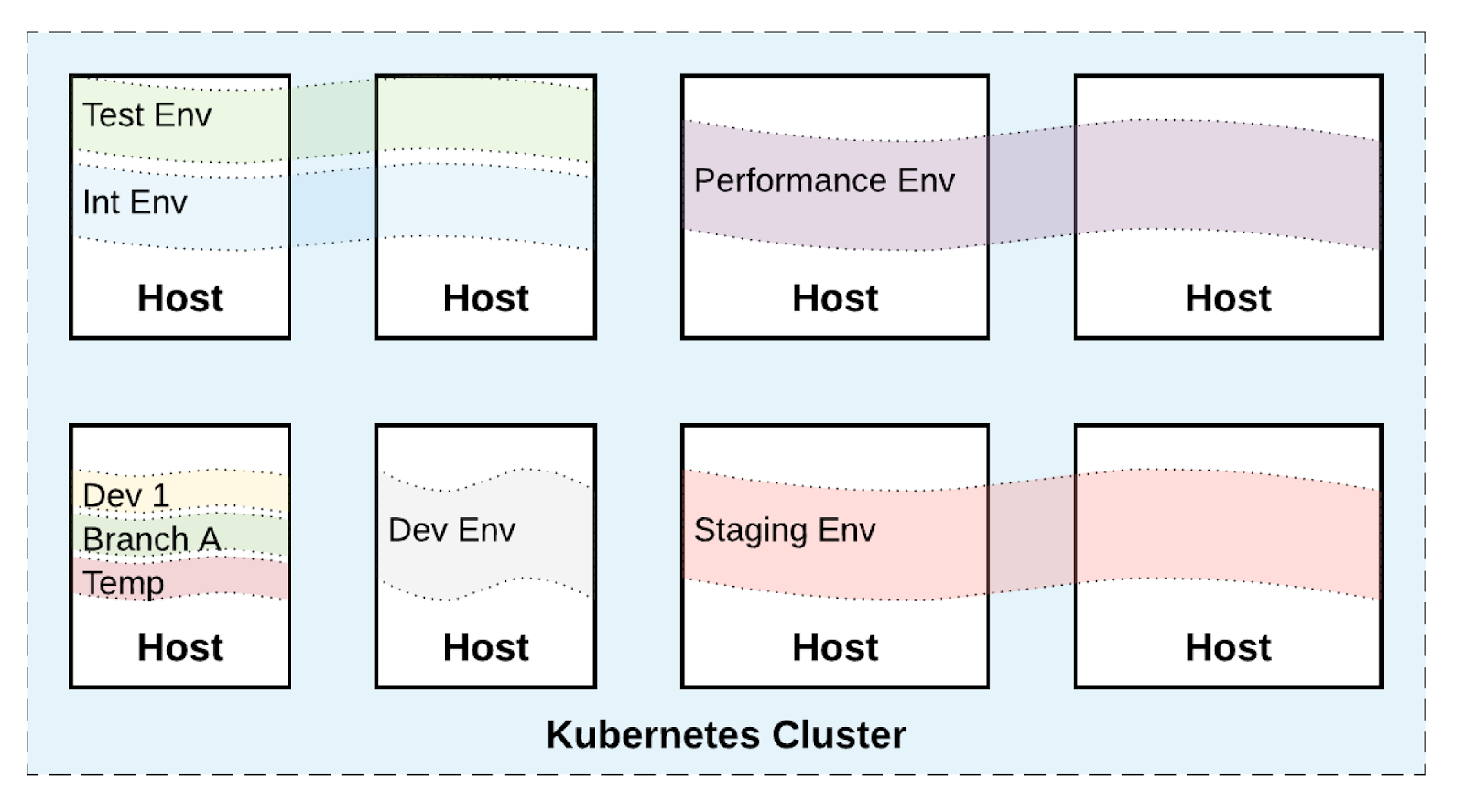 |
| Environments managed by Kubernetes |
In the Cloud Native world, an environment is just an isolated, controlled and named resource collection. For example, given a pool of 8 VMs, you can chunk and use that resource pool for different environment instances depending on the needs of the various teams. And those chunks don't map to VMs, which means it may be that multiple environments are collocated and share few of the VMs. Creating, editing, destroying an environment is achieved with one command, instantly, w/o a request for VMs and waiting for days or even weeks. This allows teams to change their environment profiles based on their changing needs in a self-service manner, easier and faster.
Dynamically Placed Applications
We can see how a self-service platform for managing environments can ease the onboarding of new developers, services, projects, and even enable custom release strategies, which may require temporary environments on the fly. Once an environment is ready, the next task is choosing a strategy for placing our Microservices on the environments.
One of my favorite Microservices related books is Building Microservices by Sam Newman. In the book, Sam approaches Microservices from all possible angles and one of those is deployment. In the Deployment chapter, the author describes few strategies for mapping services to hosts and their pros and cons.
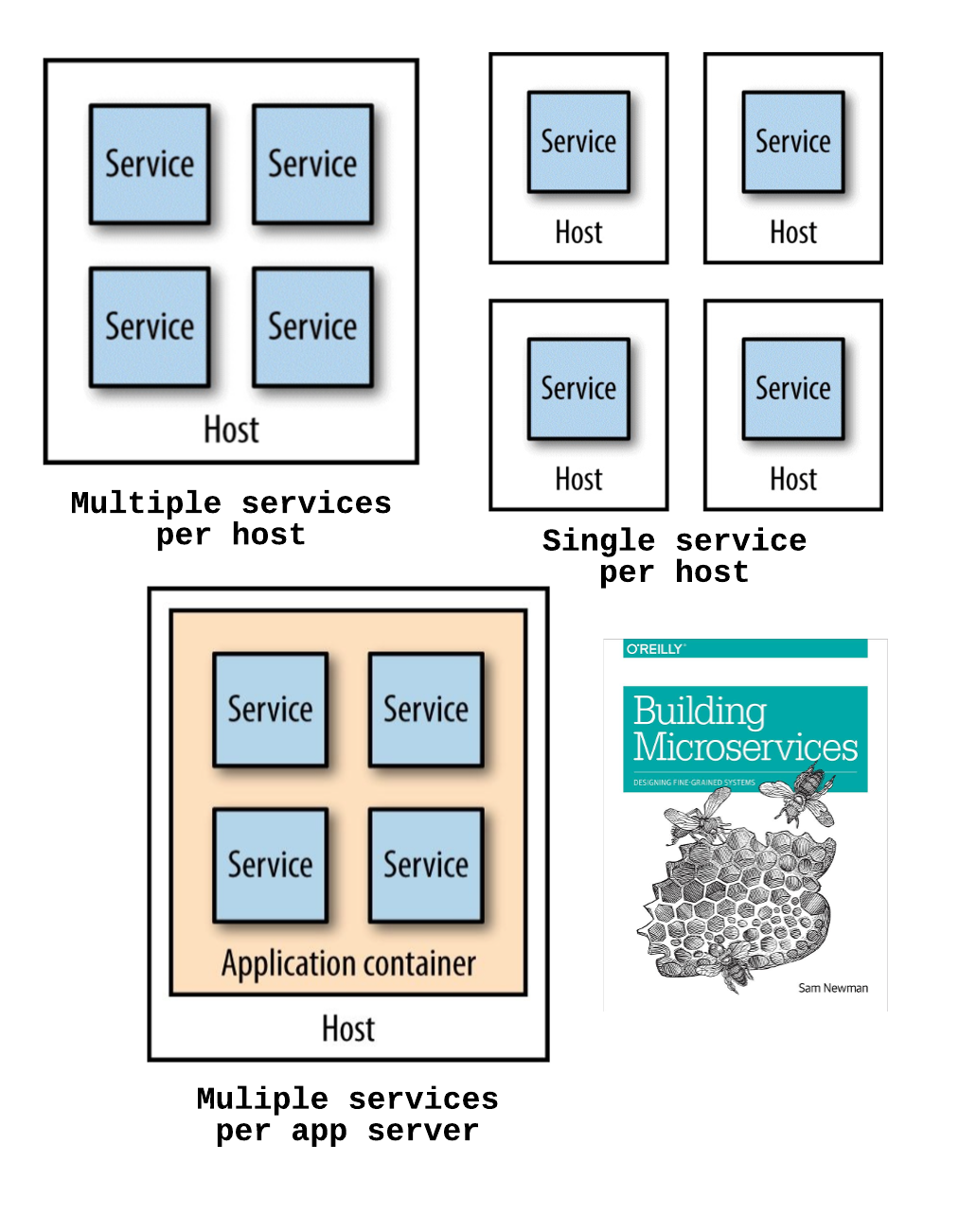 |
| Service to Host Mapping Strategies |
I have also described this approach in painful details for Apache Camel based applications in my Camel Design Patterns book. Basically, it comes down to choosing a way to package your services and grouping them on the available hosts considering all kind of service and host dependencies. Luckily, for us, the industry has moved forward quickly and containers have been accepted as the standard for packaging Microservices. Unless you are Netflix and have over 100K Amazon EC2 instances, you shouldn't look for quick ways for burning EC2 images for each service, and instead just use Docker. Even Netflix has moved on and they are experimenting with containers and even developing open source container scheduling software, so no more a VM per service, and no more service to host mapping strategies. Instead, based on your service requirements/dependencies and the available host resources, your Cloud Native platform should find a host for every service in a predictable manner defined by policies. That requires an understanding of each service and describing its requirements such as storage, CPU, memory, etc but later the benefits are huge. Rather than manually orchestrating and assigning each service to a host in advance, the Kubernetes scheduler performs a choreography of services and places them on the hosts dynamically when requested.
As you can see the concept of VM/Host disappears with environments spanning multiple hosts, and services being placed on hosts dynamically. We don't care and we don't want to know the actual hosts where our environments are carved and where the Microservices are placed (except when predictable performance is critical and shared host resources and platform resources should be avoided).
Declarative Service Deployments
We can provision environments in a self-service manner and have services placed on the environments with a minimal effort. But when we have multiple instances of a service, how do we deploy the new instances? Do we first have to stop an instance, then upgrade, and when things go wrong we rollback? Cloud Native platforms (and Kubernetes specifically) have thought about this too. Using the concept of Deployment Kubernetes allows describing how the service upgrades should be performed.
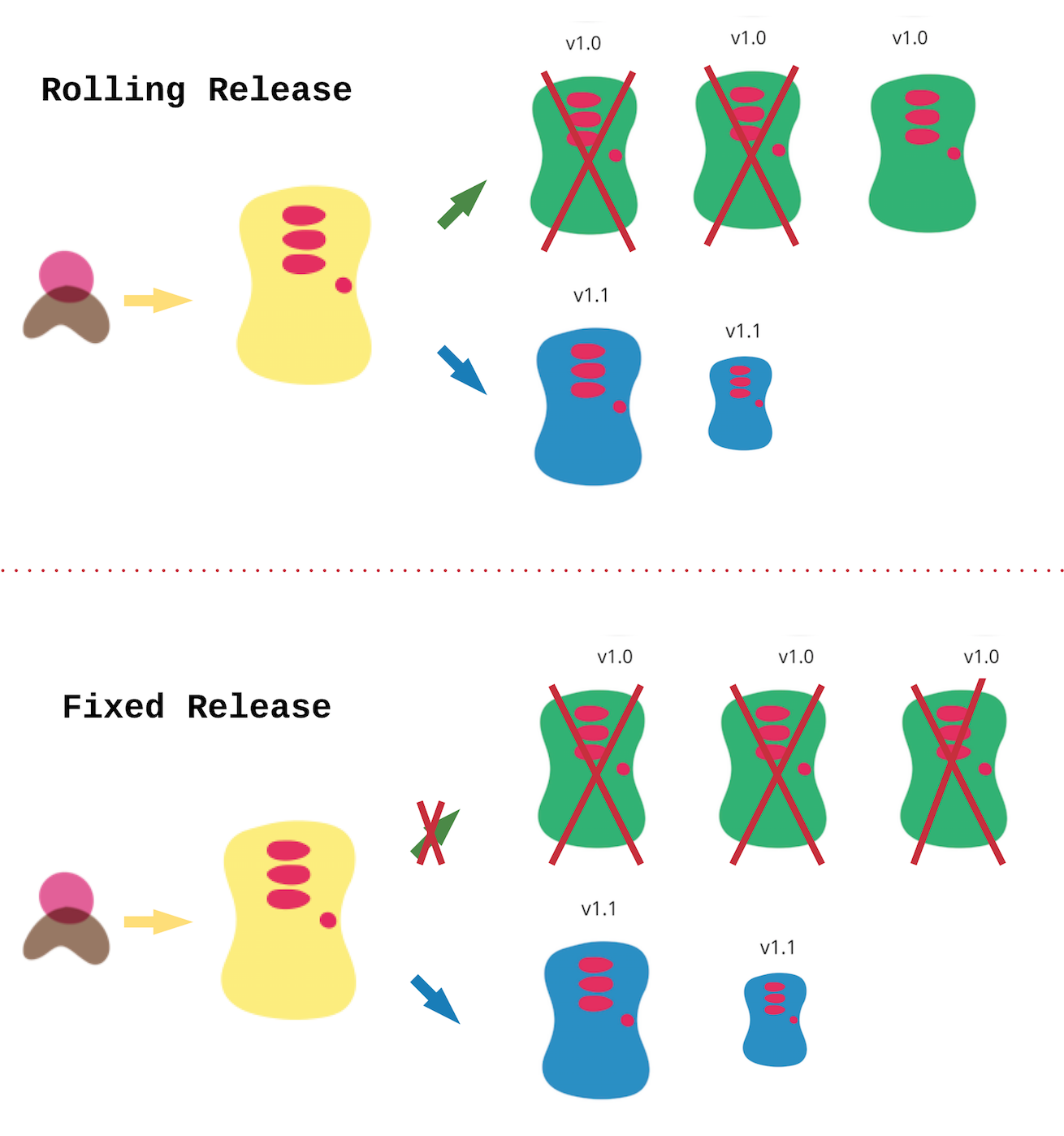 |
| Rolling and Fixed Deployment |
The Rolling Update strategy of the Deployment, updates one pod at a time, rather than taking down the entire service at the same time and ensures zero downtime. This Fixed (or Recreate as it is named) strategy, on the other hand, brings downs all service instances, and then gradually starts new versions. In both cases, the Deployment will declaratively update the deployed application progressively behind the scene.
Additional Benefits
Having a platform that is capable of managing the full life cycle of services offers also additional deployment related benefits.
Blue-Green and Canary Releases
The Blue-Green release is a way for achieving rapid rollback in case anything goes wrong with the new release.
The Canary release is a technique for reducing the risk of introducing a new software version in production by introducing change only to a small subset of users before rolling it out to everybody.
 |
| Blue-Green and Canary Releases |
Both of these techniques can be easily achieved using Kubernetes with minimal human intervention.
Self-Healing
The Cloud Native platform is able not only detect failure but also act and heal it. Kubernetes will regularly perform health checks for your application and if it detects something wrong, it will restart your service and even go further and move it to a different healthier host if required.
Auto Scaling
In addition to self-healing, the platform is also capable of auto scaling of services and even the infrastructure. That is a very powerful feature giving the platform some Antifragile characteristics.
DevOps and Antifragile
If we look at all the benefits provided by Kubernetes, I think it is fair to say that it offers primitives and abstractions that are better suited for managing Microservices at scale. With such a tool, it becomes easier for teams and organizations to use practices such as DevOps and focus on improving the business processes towards Antifragility.
Closing Thoughts
Not a Free Lunch
We have seen many of the benefits of Cloud Native platforms in regards to Microservices deployments but have not discussed any of its cons in this article on purpose. As you may expect, there is a steep learning curve for Kubernetes, and also a need for a change in the patterns, principles, practices and processes when developing such applications. Basically, that is the move to Cloud Native applications.
Change is Inevitable
This may sound too strong, but if you are doing Microservices, and that is Microservices at scale, using a Cloud Native platform (such as Kubernetes) is a must.
 |
| Picture from Wikipedia. Wisdom from W. E. Deming |
If you are using pre-microservices tools, techniques, and practices for developing Microservices, it will hit you back, and Microservices may not work for you.

About the author:
Bilgin Ibryam is an Apache Camel committer, integration architect at Red Hat, a software craftsman, and blogger. He is an open source fanatic, passionate about distributed systems, messaging and application integration. He is the author of Camel Design Patterns & Instant Apache Camel Message Routing books.
Download and learn more about the Red Hat Container Development Kit, designed to help you develop container-based applications quickly.
