Situation: You’re a great software developer and a fearless leader. Your CEO bursts into your cubicle and he is giving you vast amounts of investment capital, no data center, and limited staff. Your task: build a multi-region, highly available presence in AWS (or your favorite cloud provider) that can be maintained by minimal man-power. Your multi-tier Java EE app is almost ready. You are going to be required to create, maintain, and monitor a large amount of servers, RDS instances, S3 buckets, queues, public DNS entries, private DNS entries, etc. This series of articles aims to provide some ideas that help you go to market without a snag.
You heard multiple servers and you started to build your Ansible tower, puppet master, chef recipes, glue scripts. STOP!
Before you get yourself into a situation where your company is paying your favorite coffee shop’s franchise fee in cloud services and is getting the functionality of a french press, let’s think this through. There are a few things you need to consider. Are you creating EC2 instances manually? What is your staging environment like? Do you have one? Where should it live? Let’s take a few moments and discover the steps we need to take using the flowchart in Figure 1.
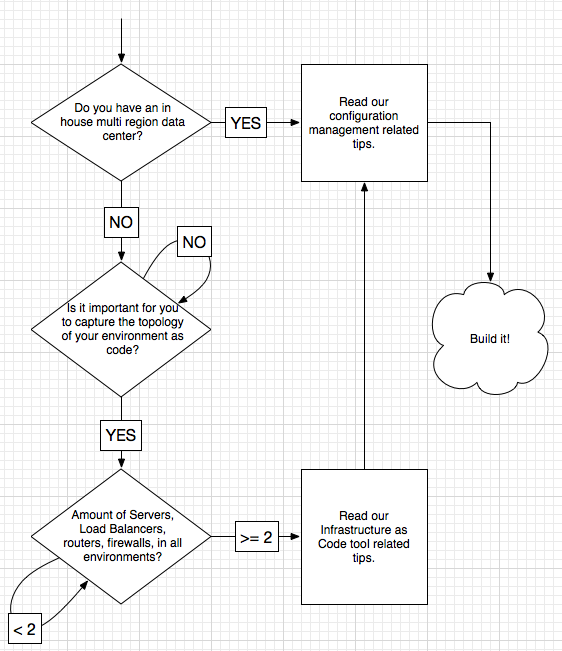
- Figure 1: HA Cloud build out demands the use of an IAC tool set.
Note: The toolset we chose is Hashicorp Terraform [http://www.terraform.io] as our Infrastructure as Code (IAC) tool, and puppet community [http://puppet.com] for configuration management. If you choose a different set of tools, the principles in this series will still apply. As an obvious caveat, some scripts may not work, and please substitute your tools’ names in your head while following along.
Figure 2 describes how things fit together now that you are prepared to handle the tasks ahead of you.

- Figure 2
Depending on the size of your site and the array of software stacks you need to support, the implementation of the final state in Figure 2 could take anywhere between days and months. After all, you will be trying to build out a subset of functionality in Figure 3.
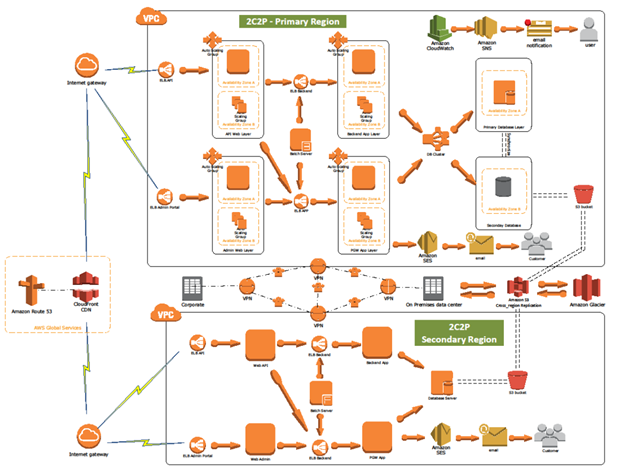
- Figure 3 [borrowed from https://aws.amazon.com/solutions/case-studies/2c2p/]
There is ample documentation and code samples for AWS, Terraform, and puppet on the internet. Please take the time and familiarize yourself with the basics of these tools, we’ll wait. As a general rule of thumb for both tools, you need to be familiar with the concepts of the environments you are trying to provision in order to be successful. In other words, both in puppet and Terraform, in order to configure resources, you need to know how to accomplish what you are trying to do without the tools first.
Designing your next HA Cloud with these tips in mind will help prevent some issues down the road, save you from losing revenue, or your client base losing confidence.
AWS and Terraform related tips:
1. Plan your Terraform project carefully. You don’t get do-overs after go live.
Terraform is an incredible resource for rapid infrastructure development. However, as of the 0.6+ releases, refactoring, or evolving an existing infrastructure usually requires destroying most of it. There are a few ‘advanced’ user solutions to this, but “tfstate file hacking” is definitely an area where “There Be Dragons”. Hashicorp provides a good starting point for a multi-cloud, multi-environment, and multi-region project that you should definitely consider.
2. Use a provider with specified region when creating resources.
As you start building out your terraform project and creating resources, terraform’s AWS provider has a few mechanisms that let you choose in which region your resources are created (per https://www.terraform.io/docs/providers/aws/). Terraform will observe the AWS_DEFAULT_REGION environment variable, but it’s best not to rely on it. Instead, rely on the provider syntax that uses an external credentials file (to prevent committing plaintext credentials to your source code repository). Create a provider for each region you intend to use. This way you are explicitly declaring in which region a resource is created. If you don’t specify the provider reference, you will receive an exception instead of creating resources in your default region.
3. Set up conventions and tag your resources.
AWS provides tags to categorize resources, we recommend at least these categories
- Environment or Stack, e.g. dev, int, prod
- Name, e.g. webserver-prod, the environment specific name
- Role, e.g. webserver, puppet related role, this will be used to create the host name, and provision your EC2 instances via puppet
4. Automate and standardize your development environment across the team
These days Vagrant (hopefully running containers) is become the gold standard for setting up shared developer environments, and the Cloud dev team should not be an exception. Take the time to ensure everyone is working on the same versions of Terraform, as well as any supporting toolsets you might be using. For example, we make heavy use of direnv in our Terraform projects, which is a fantastic environment variable management tool.
5. Create a base image (AMI) that includes your basic tool set, and clean up runtime configuration bits.
Before you start creating myriads of EC2 instances, create a small EC2 instance. Make sure that it has most of the basic tools you intend to use. For instance: AWS CLI, Python, custom init scripts. Then, clean up DHCP options (e.g. dhclient -r) unless you would like to have your machine potentially start with a stale DHCP search domain.
6. IP addresses between environments/regions shouldn’t overlap.
This rule is standard in traditional environments as well. Even if you don’t see a need for one VPC to communicate with another today, an overlapping IP network. If you choose the 172.16.0.0/12 CIDR to work in within your Virtual Private Clouds (VPC), please make sure that each VPC gets a different CIDR. For instance, if your west production region is 172.26.0.0/16, make sure that the east production region is 172.27.0.0/16, or something that doesn’t overlap. Setting up your VPC this way has no negative side effects and you need this in order to set up a VPN tunnel between the two environments. The more strongly you believe this will not be an issue in your environment, the more likely it will be that this will be an issue.
7. Consider name spaces for various AWS services.
The best example we’ve found so far; AWS S3 bucket namespaces are global, their locations are regional. Don’t expect to be able to create two buckets with the same name in different regions, your bucket naming scheme should include the region (i.e. my-fancy-bucket-us-west-2-dev), furthermore your application should be aware of region specific buckets. If you ever might need a multi-region infrastructure, make sure regions are in your bucket names.
- Build and test everything in more than one region, preferably somewhere other than us-east-1 first.
The default region is us-east-1 in the Java based SDK, as well as several other SDK’s. Unless you expect to access resources across regions in your HA Cloud, you should not rely on defaults and should instead explicitly set the region in your source code. There are some important caveats (VPN, RDS mysql cross-region replication), but the less you do this the better. If you build your cloud in us-west-2 region first, you have better guarantees that your development teams are setting the region explicitly in their codebase. For example, SQS namespaces are regional, so if your application logic doesn’t specify which region to use to consume messages from the queues, it may happen that the west region will consume east queue items. This is usually not what you want, and may be hard to debug (it was for us!).
9. Use source code versioning tools (e.g. git) for your terraform project.
Versioning brings tremendous value to the party. With terraform, everything you do to your environment is captured in your terraform file. Having the ability to revert and rebuild a specific configuration is invaluable.
10. Set up a remote terraform state file in a versioned S3 bucket, if you aren’t using Terraform Enterprise.
If you work in a team, it will become important that all of you have access to the latest version of the file that terraform uses to store its state. For this we recommend a versioned S3 bucket. More info here: https://www.terraform.io/docs/state/remote/s3.html
RHEL and Puppet related tips:
11. Create facter facts from AWS tags.
This gist provides a shell script that converts AWS Tags to facter facts. This only works on an EC2 instance that can access AWS instance metadata.The script should live in /etc/facter/facts.d/ and should be executable. The script requires the AWS client libraries and the ec2 instance configured t o be able to reach out the AWS Instance Metadata service.
12. Create unique hostnames on the fly.
Puppet relies on DNS for hostname resolution, and your environment needs to have a relatively predictable host naming scheme for puppet based provisioning. We advocate for designing your puppet roles ahead of time, making the instance id part of the name (i.e. webserver-<AWS instance id>), and adding/removing the DNS record from the zone part of instance startup and shutdown. This way you can be assured that if the IP address of the EC2 instance changes because the machine wasn't configured with a static private IP inside your VPC or a dedicated Elastic IP, when the EC instance restarts, your script "upserts" the new DNS record.
This article covered some basic tips that we recommend and the reasoning behind them. The next article in this series builds on these tips and provides more advanced tips for your next HA Cloud buildout.
Last updated: March 16, 2018