The simple programmer's model of a processor executing machine language instructions is a loop of the following steps with each step finished before moving on the the next step:
- Fetch instruction
- Decode instruction and fetch register operands
- Execute arithmetic computation
- Possible memory access (read or write)
- Writeback results to register
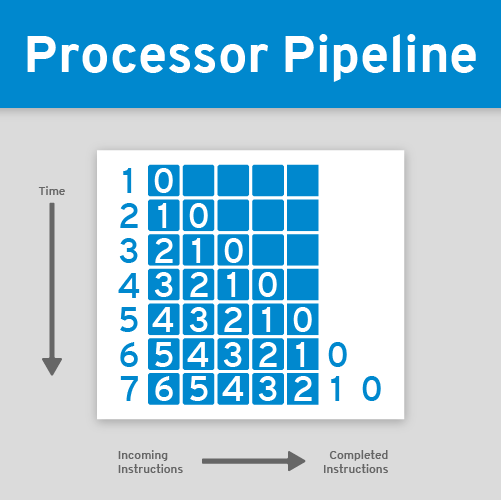
As mentioned in the introduction blog article even if the processor can get each step down to a single cycle that would would be 2.5ns (5*0.5ns) for a 2GHz (2x10^9 cycles per second) processor, only 400 million instructions per second. If the instructions can be processed in assembly-line fashion and the steps of instructions be overlapped, the performance could be significantly improved. Rather than completing one instruction every 2.5ns, the processor could potentially complete an instruction every clock cycle, a five-fold improvement in speed. This technique is known as pipelining.
Possible Performance Issues of Pipelines
Although pipelining instruction execution has the potential to greatly improve the processors performance there are a number of situations than can limit performance. This isn't an exhaustive list, but will give you some ideas why you might not be getting an instruction completed every clock cycle.
- true dependencies (interlocks)
- multi-cycle instructions stalls
- branches
- pipeline flushes
True Dependencies (Interlocks)
The assemly-line nature of pipelined instruction works very well if the instructions in the sequence are independent of of all the other instructions. If the results of one instruction are used by a following instruction, then there is a true dependency between the instructions. The following instruction stalls until the result is available because of the interlock. Take the simple statement that increments the variable i below:
++i
It might be converted in the following sequence of instructions:
ldr x1, [i]
add x2, x1, 1
str x2, [i]
On each clock cycle an attempt is made to move each instruction down the pipeline. However, after the add instruction is fetched the pipeline will stall until the value is loaded by the ldr instruction into x1. The store performed by the str instruction has a similar interlock waiting for the results of the add instruction to be written in x2.
The compiler may attempt to order the instruction sequences so that instructions with true dependencies are not right next to each other to avoid these pipeline stalls due to interlocks.
Multi-Cycle Instructions Stalls
The pipeline can only advance as fast as the slowest step in the pipeline. Ideally each step in the pipeline is designed to take about the same amount of time. However, there are some instruction steps that might take multiple cycles. For example on most processors the divide operation takes multiple cycles and would stall the pipeline until it completes. Although caches attempt to minimize the impact memory reads and writes of the memory access step could take multiple cycles.
Branches
The basic assumption is that each cycle the processor is fetching the next instruction to put into the pipeline for processing. This works great for a linear sequence of instructions. In this case processor can easily fetch the next instruction in the sequence. However, all code has conditional branches to implement if-then-else statements, switch-case constructs, and loops. Which instruction is next depends on the result of a calculation. The pipeline must stall until the processor can determine what is the next instruction to fetch.
Conditional branches are very common in code and they can have a significant impact in performance. Some processors with pipelines such as MIPS and SPARC tried to hide some of that overhead using delayed branched where the instruction following the branch instruction would always be executed to give the processor time to fetch the destination of the branch. However, delayed branches did not work so well when the processor pipelines got longer and multiple clock cycles were required for the processor to fetch the branch destination. An alternative approach, branch prediction, was developed to address this and it will be discussed in a following blog article.
Pipeline Flushes
In some cases the pipeline will start processing instructions, but it will need to stop the processing of the instructions and discard the completed work. The processor preserves the behavior of the simple model presented to the programmer. For example, when a processor does a memory access that causes an exception indicating that kernel assistance is required the work done on following instructions must be discarded. The exception may be just a simple fixup to properly map a page of memory or it could be a program-ending illegal memory access. The processor needs to play it safe and make it look like the instructions following the one that caused the exception never executed. The times when the stages of the processor pipeline are emptied will increase the average number of cycles per instructions (CPI).
Where to get additional information
Both Intel and AMD have documentation discussing performance tuning for their processors which includes suggestions on how to address some of these performance issues:
Last updated: February 22, 2024