
The simple programmer's model of processor executing machine language instruction is a loop of the following steps each step finished before moving on the the next step:
- Fetch instruction
- Decode instruction and fetch register operands
- Execute arithmetic computation
- Possible memory access (read or write)
- Writeback results to register
At a minimum it takes one processor clock cycle to do each step. However, for steps 1 and 4 accessing main memory may take much longer than one cycle. Modern processors typically have a clock cycle of 0.5ns while accesses to main memory are 50ns or more. Thus, an access to main memory is very expensive, over 100 clock cycles. To get good processor performance the average times to fetch instructions and to access data from memory must be reduced.
Assume that every instruction needs to be fetched from memory, every memory reference instruction needs one memory access, and one third of the instructions are a memory reference, and step 4 for instruction that do not have a memory reference takes one cycle. The average clock per instructions (CPI) would be computed with the following formula:
CPI = (step 1 cost) + (steps 2,3,5 cost) + (step 4 cost)
= 100 cycles + 3*(1 cycle) + ((1 cycle * 2/3) + (100 cycles * 1/3))
= 100 cycles + 3 cycles + (.6667 cycles + 33.33 cycles)
= 137 cycles per instruction
In the computation above the slow memory access times dominate the overall time to execute an instruction. Reducing the memory access time by just using faster memory is not usually an option. The fastest memory chips are still much slower than the processor. Also high-speed memory is expensive and power hungry. Most people would like to have machines with gigabytes of memory using watts of power costing a few hundreds of dollars rather than machines with megabytes of memory using kilowatts of power and costing many thousands of dollars.
Instead of a brute-force approach of making all memory fast processor designer include a cache mechanism in the processor which is checked to see if a copy of a particular memory location is available in the cache before initiating the actual memory access. If the cache holds a copy of the memory location, the slow access to main memory can be skipped. The cache is small and fast, usually tens or hundreds of kilobytes in size accessible in just a few clock cycles.
If most of the accesses are satisfied by the cache (a cache hit), then the cycles per instructions can be significantly reduced. Assuming that 95% of the memory reference are satisfied by the cache and the cache accesses are a single cycle the CPI formula becomes:
CPI = (step 1 cost) + (steps 2,3,5 cost) + (step 4 cost)
= (1 cycle * (0.95) + 100 cycles * (1-0.95)) + (3 cycles) + ((1cycles * (2/3 + 0.95/3)) + (100cycles * (1-0.95) 1/3))
= (0.95 cycles + 5 cycles) + 3 cycles + (0.9833 cycles + 1.667 cycles)
= 5.95 cycles + 3 cycles + 2.6533 cycles
= 11.60 cycles
This last calculation above shows that the cache has a huge impact on processor performance. In this example the cache enables the processor to be over ten times faster. This is why every modern processor includes a cache. Without the cache it make little sense to have the processor clock running at gigahertz frequencies. The processor would just be waiting for the memory access to complete. The 11.60 cycles per instruction still is a bit higher than desired. Let's recompute the average instruction cost if the cache satisfied 99% of the instruction fetches and data memory references.
CPI = (step 1 cost) + (steps 2,3,5 cost) + (step 4 cost)
= (1 cycle * (0.99) + 100 cycles * (1-0.99)) + (3 cycles) + ((1cycles * (2/3 + 0.99/3)) + (100cycles * (1-0.99) 1/3))
= (0.99 cycles + 1 cycles) + 3 cycles + (0.9966 cycles + 0.3333 cycles)
= 1.99 cycles + 3 cycles + 1.3299 cycles
= 6.3199 cycles
Because the cost of accessing main memory is so high improving the cache hit rate 4% from 95% to 99% almost halves the average clock cycles required to execute an instruction. Maximizing the percentages of memory references that the cache can satisfy is essential to getting good performance out of modern microprocessors. Even improvements of 1% in the cache hit rate can significantly help processor performance.
The cache's operation is designed to be invisible to normal application code and hardware manages data in the cache. The hardware manages the cache as a number of individual cache lines. Each cache line has two parts: a tag that identifies which part of main memory it currently handles and the actual data for that region of memory. The tag is a portion of the address, enough to allow the hardware to determine whether a line in the cache is holding the contents for a particular memory location. When the processor requests access to a memory location that is not yet in cache the cache flushes one of the occupied cache lines writing its modified contents back to memory if required to make room for the newly fetched data.
To make the search and selection of the appropriate cache line for the memory access faster the cache lines are grouped into sets. Each set typically contains one to eight cache lines. A portion of the memory address is used to select which set in the cache should contain that memory address. Limiting the number of cache lines to search simplifies the matching circuitry and the logic to determine which cache line to return to memory. This allows the cache to operate at a higher speed and not slow down the processor.
Another cache design trick the processors designers use is to make each cache line hold multiple bytes (typically between 16 and 256 bytes), reducing the per byte cost of cache line bookkeeping. Having multiple bytes in the cache line may also help performance by eliminating cache misses for those neighboring bytes in later memory accesses.
Possible Performance Issues of Caches
Caches make it possible to use relatively slow, low cost memory with high speed processors, but there are a number of ways that caches may not get ideal performance. Many theses, articles, and books have been written about caches, their performance, and design tradeoffs. This blog article cannot go into great depth, but give it can give you an idea of a few common performance issues that can hurt the caches effectiveness:
- capacity misses
- conflict misses
- false sharing
- forced flushing and invalidation of cache
Capacity Misses
Capacity misses occur when the cache is too small to hold all the cache lines needed for a region of code. This could occur with repeated passes through a data array that is larger than the cache size. The array cannot fit entirely in the cache causing elements to be repeatedly flushed and reloaded for each pass. Capacity misses may also happen in instruction caches where the there is a very long sequence of instruction in loop due to the compiler inlining other functions into the loop to eliminate function call overhead. To address this problem for loops with large arrays the loops should be broken down into units of work that fit in the cache. Similarly, too large loop bodies might be broken into a sequence of smaller loops, each one able to fit in the instruction cache.
Conflict Misses
Each address is mapped to one set in the cache and each set in the cache will only have a limited number of cache lines in it, typically between one and eight lines. With certain memory access patterns the active number of memory addresses mapping to the same set will exceed the number of cache lines in the set. Lines in the set will need to be flushed from the cache set to make room for the more recent accesses, causing conflict misses. This differs from capacity misses in that the problem is caused by the limited number of lines in the set rather than the total size of the cache.
A portion of the address bits are used to determine which set a particular address belongs to. The picture below shows how the bits of the address are divided up. For example the processor has a 32KB cache with 2 lines in each set and 64 bytes in each line. The least significant 6 bits (5-0) would indicate which byte in the 64 byte cache line is being addressed. There is a total of 512 cache lines (32KB total/64B per line) and there are 256 sets (512 lines/2 lines per set). Bits 13-6 of the address would be used to select the set this address should be in. All the addresses with the same values for bits 13-6 end are mapped to the same set. The remaining most significant bits (31-14) would be used as a tag to identify where in memory this cache line came from. Thus, if more than two addresses are being used with multiples of 16384 bytes between them, there will be conflict misses. One could attempt to eliminate this problem by changing the location of the data so they fall into different sets.
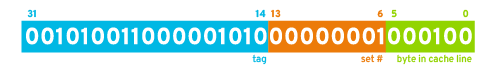
False sharing
As mentioned earlier each cache line is made of multiple bytes. A cache line is large enough that it can hold several unrelated data structures from a region of memory. False sharing occurs when two processors are modifying the values in non overlapping parts of memory that would be contained in a single cache line. When the processor modifies the value in a cache line it needs to get exclusive access to the line. The result in this situation is that a cache line may be moved repeatedly between processors. If the separate data structures were laid out in memory so they did not end up in a single cache line, the overhead of moving the data between the processors can be eliminated.
Forced Flushing and Invalidation of Cache
There are conditions when the contents of the cache must be invalidated for correct operation of the machine. One example of where this occurs is for Just-In-Time (JIT) translators in runtime system such as Java. The JIT translator generates a sequence of instructions in a regions of memory that is data which could be stored in the data cache or main memory. Processors have another cache for instructions. The code needs to take steps to invalidate any stale values in the instruction cache to ensures that newly generated code gets pulled in the instruction cache. On some processors the cache flushing and invalidation operations are very coarse-grained causing entire caches to be flushed which triggers many expensive cache refill operations on later memory fetches.
Investigating Cache Performance Further
Ulrich Drepper's paper "What Every Programmer Should Know About Memory" provides a great deal of information about how the memory hierarchy works in processors.
There are a couple Red Developer Blog articles discussing cache issues:
- Determining whether an application has poor cache performance
- False cacheline sharing: New tool to pinpoint where it’s happening – DevNation talk
Both Intel and AMD have documentation discussing performance
tuning for their processors which includes suggestions on how to
address some of the cache performance issues: