Backstory
First, a brief backstory on the storage situation for Docker since it was open-sourced in early 2013. At that time, Docker relied on a filesystem called AUFS (advanced multi layered unification filesystem). This Union filesystem provided the necessary features to support several of Docker's main selling points:
- container creation speed
- copy-on-write image->container
![]()
Docker still supports the AUFS backend, but Ubuntu has disabled it and moved the AUFS kernel module to linux-image-extra. The fact that AUFS never made it into the upstream Linux kernel poses a problem for Red Hat, where the policy is upstream first, and, out-of-tree bits are not included. Of course, that doesn't preclude experiments of all shapes and sizes!
The Search for an Alternative
We knew we needed an alternative to AUFS, something upstream, stable, maintainable, supportable long-term, and performant. The litmus test for anything we evaluate.
Interestingly enough, a solution that meets the above criteria had already been invented by Red Hat kernel engineers (Joe Thornber and Mike Snitzer) for different applications: device mapper thin provisioning. Several Red Hat engineers (especially Alex Larsson) worked extensively planning and writing a new storage driver for Docker, based on device mapper, which was included in Docker 0.7. If you are using Docker as packaged by Fedora, CentOS or RHEL, the default will be device-mapper using something called a loopback mounted sparse file.
Device mapper thin provisioning plus this loopback mounted device keeps with the tradition of being able to simply install Docker and begin using it, with no configuration. That's awesome for nimble developers iterating on projects. Nothing to get in the way of productivity. Excellent. This capability is truly one of the major wins for Docker. I love it.
However, as an enterprise software company, we're responsible for more than the developer use-case. Therefore we deeply evaluated storage options for Docker, and realized there needed to be some site-specific customization, especially around storage and networking, when customers started using Docker in actual production.
Engineers also realized (before any device mapper code was written) that the additional code paths and overhead introduced by loopback mounted thinp volumes may not suit I/O heavy workloads, and that we would need an alternative.
Further, regarding union filesystems, memory use drove exploration of alternatives to dm-thinp and btrfs (because neither solution provides page cache sharing across the snapshot volumes used by the containers). AUFS is pretty much a non-starter. OverlayFS (and in the future, unionmount) are on the radar.
On went the evaluation...
We looked at different storage backend variations that met the basic criteria of Docker - fast CoW. The kernel got patched. Many times. Out came several things:
- A more scalable and performant kernel and device-mapper thinp ... massive impact.
- Enabling btrfs in Fedora-packaged Docker
- PoC code to support OverlayFS in Docker (kernel support required)
- Verification that Docker "volumes" provided near bare metal performance.
- Scoped effort necessary to bring proper security, isolation and SELinux support
This left us with several storage options for Docker images/containers:
- Device Mapper loopback (aka loop-lvm)
- Device Mapper (aka direct-lvm)
- BTRFS (Docker's upstream default)
On Fedora, you have one additional choice, provided you were running the playground kernel:
- OverlayFS (not in the upstream linux kernel or Docker, yet)
Neither Fedora or CentOS distribute a kernel with AUFS support. If unspecified, Docker chooses a storage driver in this priority order:
// Slice of drivers that should be used in an order
priority = []string{
"aufs",
"btrfs",
"devicemapper",
"vfs",
"overlayfs",
Again, depending on what's provided by the host kernel, or obeying the '-s' daemon startup option.
Overview of each storage option
Device Mapper loop-lvm
From the documentation: The device mapper graphdriver uses the device mapper thin provisioning module (dm-thin-pool) to implement CoW snapshots. For each devicemapper graph location (typically /var/lib/docker/devicemapper, $graph below) a thin pool is created based on two block devices, one for data and one for metadata. By default these block devices are created automatically by using loopback mounts of automatically created sparse files.
For example:
# ls -alhs /var/lib/docker/devicemapper/devicemapper 506M -rw-------. 1 root root 100G Sep 10 20:15 data 1.1M -rw-------. 1 root root 2.0G Sep 10 20:15 metadata
See how it's a 100GB file, yet on-disk usage is only 506MB. That's a sparse file. Same with metadata - also sparse.
Look at lsblk output. Two loop devices are mounted. One for the container storage, one for metadata used by device-mapper thinp.
loop0 7:0 0 100G 0 loop └─docker-252:3-8532-pool 253:0 0 100G 0 dm └─docker-252:3-8532-base 253:1 0 10G 0 dm loop1 7:1 0 2G 0 loop └─docker-252:3-8532-pool 253:0 0 100G 0 dm └─docker-252:3-8532-base 253:1 0 10G 0 dm
As above, the defaults for the loop-lvm configuration are for a 100GB pool (total max across all containers). If you need more than 100GB, adjust the systemd unitfile or /etc/sysconfig/docker. If you choose the systemd route, ensure that you create an override file in /etc/systemd/system/docker.service rather than editing /usr/lib/systemd/system/docker.service.
# ExecStart=/usr/bin/docker ... --storage-opt dm.loopdatasize=500GB --storage-opt dm.loopmetadatasize=10GB And you'll need to reload systemd: # systemctl daemon-reload # systemctl start docker
Device Mapper: direct-lvm
The "direct-lvm" variant continues to use LVM, device mapper, and the dm-thinp kernel module. It differs by removing the loopback device, talking straight to a raw partition (no filesystem). The performance advantages are measurable at moderate load and high density.
Using LVM, create 2 devices, one large for Docker thinp data, one smaller for thinp metadata. i.e. 100G and 4G respectively. Let's assume you're using /dev/sdc and want LVM devices named /dev/direct-lvm/data and /dev/direct-lvm/metadata.
# pvcreate /dev/sdc # vgcreate direct-lvm /dev/sdc # lvcreate --wipesignatures y -n data direct-lvm -l 95%VG # lvcreate --wipesignatures y -n metadata direct-lvm -l 5%VG This next step is not necessary the first time you set it up. It re-initializes the storage, making it appear blank to Docker. This would be how you "wipe" direct-lvm (since there's no filesystem, you can't exactly mkfs ;) # dd if=/dev/zero of=/dev/direct-lvm/metadata bs=1M count=10
The device mapper storage driver for Docker is configured by appending individual --storage-opt flags to the Docker daemon command line. Available options are:
- dm.basesize: Size of the base dm device (10G by default)
- dm.loopdatasize: Initial size of the data looback file
- dm.loopmetadatasize: Initial size of the metadata loopback file
- dm.fs: The filesystem to use for the base image (xfs or ext4)
- dm.datadev: Set raw block device to use for data
- dm.metadatadev: Set raw block device to use for metadata
- dm.blocksize: Custom blocksize for the thin pool. Default is 64K.
To use direct-lvm, use the dm.datadev and dm.metadatadev options in the systemd unitfile, or /etc/sysconfig/docker:
ExecStart=/usr/bin/docker ... --storage-opt dm.datadev=/dev/direct-lvm/data --storage-opt dm.metadatadev=/dev/direct-lvm/metadata And you'll need to reload systemd: # systemctl daemon-reload # systemctl start docker
I often add dm.fs=xfs to the mix, as XFS has repeatedly been proven the most performant filesystem in our testing.
Note that the loop-lvm device does not respect O_DIRECT, so it will look like it's getting several GB/s throughput. But then, if you watch iostat on the host, you'll see the kernel's VM subsystem flushing according to it's normal routine. direct-lvm supports O_DIRECT.
btrfs
btrfs seems the most natural fit for Docker. It meets the basic requirements of supporting CoW, it's moderately performant, and actively developed. It has had it's share of bumps in the road over the years, leaving it in a mixed state of support depending on what distribution you're running. btrfs does not currently support SELinux, nor does it allow page cache sharing.
Assuming you want the btrfs filesystem on /dev/sde:
# systemctl stop docker # rm -rf /var/lib/docker # yum install -y btrfs-progs btrfs-progs-devel # mkfs.btrfs -f /dev/sde # mkdir /var/lib/docker # echo "/dev/sde /var/lib/docker btrfs defaults 0 0" >> /etc/fstab # mount -a
You can now inspect the filesystem:
# btrfs filesystem show /var/lib/docker
Label: none uuid: b35ef434-31e1-4239-974d-d840f84bcb7c Total devices 1 FS bytes used 2.00GiB devid 1 size 558.38GiB used 8.04GiB path /dev/sde Btrfs v3.14.2
# btrfs filesystem df /var/lib/docker Data, single: total=1.01GiB, used=645.32MiB System, DUP: total=8.00MiB, used=16.00KiB System, single: total=4.00MiB, used=0.00 Metadata, DUP: total=3.50GiB, used=1.38GiB Metadata, single: total=8.00MiB, used=0.00 unknown, single: total=48.00MiB, used=0.00
# btrfs device stats /dev/sde [/dev/sde].write_io_errs 0 [/dev/sde].read_io_errs 0 [/dev/sde].flush_io_errs 0 [/dev/sde].corruption_errs 0 [/dev/sde].generation_errs 0
Now configure Docker unitfile or /etc/sysconfig/docker to use btrfs:
ExecStart=/usr/bin/docker -d -H fd:// -b br1 -D -s btrfs # systemctl daemon-reload # systemctl start docker # docker info|grep Storage Storage Driver: btrfs
Start a few containers...4400 should do it ;)
# btrfs subvolume list /var/lib/docker | wc -l 4483
# btrfs subvolume list /var/lib/docker | head -5 ID 258 gen 13 top level 5 path btrfs/subvolumes/4e7ab9722a812cb8e4426feed3dcdc289e2be13f1b2d5b91971c41b79b2fd1e3 ID 259 gen 14 top level 5 path btrfs/subvolumes/2266bc6bcdc30a1212bdf70eebf28fcba58e53f3fb7fa942a409f75e3f1bc1be ID 260 gen 15 top level 5 path btrfs/subvolumes/2b7da27a1874ad3c9d71306d43a55e82ba900c17298724da391963e7ff24a788 ID 261 gen 16 top level 5 path btrfs/subvolumes/4a1fb0a08b6a6f72c76b0cf2a3bb37eb23986699c0b2aa7967a1ddb107b7db0a ID 262 gen 17 top level 5 path btrfs/subvolumes/14a629d9d59f38841db83f0b76254667073619c46638c68b73b3f7c31580e9c2
OverlayFS
OverlayFS is a modern union filesystem that also meets the basic Docker requirements. The quick description of OverlayFS is that it combines a lower (let's call this the parent) an upper (child) filesystem and a workdir (on the same filesystem as the child). The lower filesystem is the base image, and when you create new Docker containers, a new upper filesystem is created containing the deltas. For more information, check out the kernel documentation.
OverlayFS has several major advantages:
- It's fast
- It allows for page cache sharing (data below).
OverlayFS also has several drawbacks:
- It is not included in the upstream Linux kernel.
- It is also not supported by Docker
- Like btrfs, it also does not currently support SELinux (an active investigation)
But part of my job is to create Frankenkernels (and more recently, Frankendockers). In this case my hero Josh Boyer of Fedora Kernel Maintainership fame is maintaining a Fedora rawhide kernel that includes OverlayFS support. It's called the Fedora Playground Kernel.
So we need to be running that. We also need a build of Docker that includes OverlayFS support. In comes Alex Larsson (again) and poof we have experimental OverlayFS support in Docker. Good enough for me!
Here are the setup steps for OverlayFS and Docker.
- Create a "lower" filesystem for OverlayFS, for example, this can be a logical volume with an XFS or ext4 filesystem on it.
- Build Docker from Alex's tree:
# git clone -b overlayfs https://github.com/alexlarsson/docker.git ...
- Configure Docker to use OverlayFS backend:
ExecStart=/root/overlayfs/dynbinary/docker ... -s overlayfs
- Verify using 'docker info' and run containers as normal:
# docker info Containers: 1 Images: 28 Storage Driver: overlayfs Execution Driver: native-0.2 Kernel Version: 3.17.0-0.rc1.git0.1.playground.fc22.x86_64 Debug mode (server): true Debug mode (client): false Fds: 19 Goroutines: 28 EventsListeners: 0 Init SHA1: 2fa3cb42b355f815f50ca372f4bc4704805d296b Init Path: /root/overlayfs/dynbinary/dockerinit
Verifying your config
Use iostat to ensure container I/O is going to your new storage:
# docker run -d fedora dd if=/dev/zero of=outfile bs=1M count=2000 oflag=direct && iostat -x 1|grep sdc
Why does anyone care about union filesystems...
Supposedly a union filesystem such as OverlayFS will provide more efficient memory usage, by allowing the kernel to include only a single copy of a file read from multiple containers in it's page cache. And in fact, this is true. With non-union filesystems, files from the same base container image have different inodes and thus the kernel treats them differently. OverlayFS also allows quicker create/destroy times, although not as dramatic an impact as the potential memory savings. This memory savings is also nearly free, as compared to memory de-duplication techniques like KSM which costs a bit of CPU to scan/merge duplicate pages.
Scalability
Speed to create and destroy 1000 containers (each running Apache in it's default Fedora config).
+volume means a volume was attached to each container. We'd previously identified (and resolved) some kernel mount scalability issues. This +volume test continues because we do expect each container to use at least one volume mount.
Page Cache Re-use (shared inodes)
- vmstat-cache: the amount of memory used as cache...amount of page cache consumed when reading the same file from 3 different containers, across the 4 different storage possibilities:
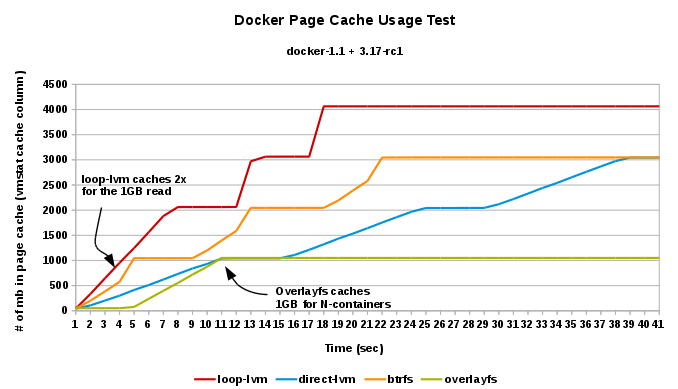
- vmstat-bi: Blocks received from a block device (blocks/s)...amount of actual data read from disk/memory to read the same file from 3 different containers, across the 4 different storage possibilities
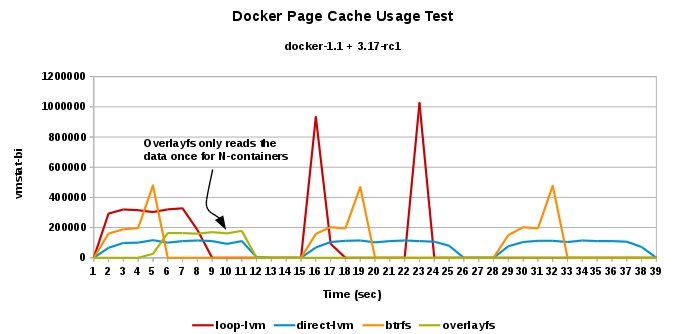
Pretty cute :-)
You can see the choice of storage affects scalability, container start up time, stability, supportability, etc.
Last updated: February 23, 2024
