This blog recaps our January 23rd vLLM Office Hours, where our host Michael Goin was joined by Murali Andoorveedu, a vLLM committer from CentML, to discuss how distributed inference works within vLLM.
Murali’s company, CentML, simplifies model deployment with open-source compilers, profiling tools, and benchmarking capabilities to enhance efficiency.
Now part of Red Hat, Neural Magic remains the leading commercial contributor to vLLM, providing enterprise-ready optimized models and distributions that help businesses maximize GPU utilization for optimized deployments. Read on to learn more about vLLM and distributed inference. If you prefer, you can watch the full video recording and view session slides. If you are looking to take your vLLM usage to new levels, join us every other Thursday for vLLM office hours where we provide regular vLLM updates and dive into special topics to accelerate your inference.
About vLLM
vLLM is the de facto standard for open-source model serving. As an Apache 2.0 open-source inference server, vLLM offers a simple interface to spin up OpenAI-compatible servers, allowing users to host inference APIs on their own infrastructure.
The project builds upon pioneering work in distributed machine learning, including techniques first introduced by Megatron-LM for model parallelization, while introducing its own innovations for efficient inference serving at scale.
vLLM prioritizes model compatibility, with ongoing support for Hugging Face’s transformer backend to ensure seamless integration across a vast ecosystem. The framework not only enhances NVIDIA GPU performance through optimization with custom kernels, but also extends its capabilities to AMD GPUs, Google TPUs, Intel Gaudi, and other accelerators.
vLLM also supports system-level optimizations such as KV Cache quantization, prefix caching, and chunked prefill to enhance inference performance. It enables efficient deployment of not just text-based models but also multimodal models and embeddings, with plans to focus more on reinforcement learning from human feedback (RLHF) in the coming year.
Distributed inference with vLLM
Serving large models often leads to memory bottlenecks, such as the dreaded CUDA out of memory error. To tackle this, there are two main solutions:
- Reduce precision: Utilizing FP8 and lower-bit quantization methods can reduce memory usage. However, this approach may impact accuracy and scalability, and is not sufficient by itself as models grow beyond hundreds of billions of parameters.
- Distributed inference: Spreading model computations across multiple GPUs or nodes enables scalability and efficiency. This is where distributed architectures like tensor parallelism and pipeline parallelism come into play.
vLLM architecture and large language model inference challenges
LLM inference poses unique challenges compared to training:
- Unlike training, which focuses purely on throughput with known static shapes, inference requires low latency and dynamic workload handling.
- Inference workloads must efficiently manage KV caches, speculative decoding, and prefill-to-decode transitions.
- Large models often exceed single-GPU capacity, requiring advanced parallelization strategies.
To address these issues, vLLM provides:
- Tensor parallelism to shard each model layer across multiple GPUs within a node.
- Pipeline parallelism to distribute contiguous sections of model layers across multiple nodes.
Optimized communication kernels and control plane architecture to minimize CPU overhead and maximize GPU utilization.
GPU parallelism techniques in vLLM
Tensor parallelism
Problem: Model exceeds single GPU capacity
As models grow, a single GPU cannot accommodate them, necessitating multi-GPU strategies. Tensor parallelism (Figure 1) shards model weights across GPUs, allowing concurrent computation for lower latency and enhanced scalability.
This approach, originally developed for training in Megatron-LM (Shoeybi et al., 2019), has been adapted and optimized in vLLM for inference workloads.

How it works
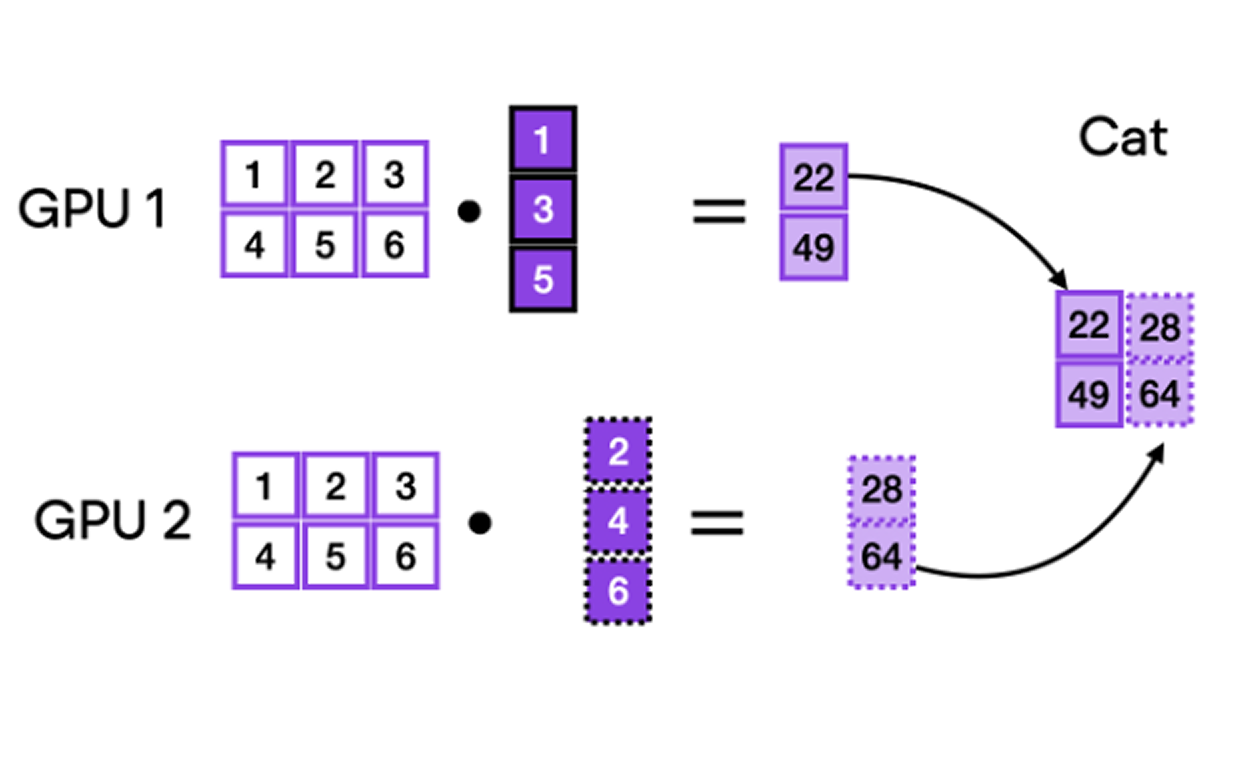
Tensor parallelism relies on two primary techniques, illustrated in Figure 2:
- Column parallelism: Splitting weight matrices along columns and concatenating results after computation.
- Row parallelism: Splitting matrices along rows, summing partial results post-computation.

As a specific example, let’s break down how this parallelism works for the MLP (multi-layer perceptron) layers in Llama models:
- Column parallelism applies to up-projection operations.
- Element-wise activation functions (e.g., SILU) operate on sharded outputs.
- Row parallelism is used in down-projection, with an all-reduce operation to aggregate final results.
Tensor parallelism ensures that inference computations are distributed across multiple GPUs, maximizing the memory bandwidth and compute available. When used, we can achieve latency improvements from effectively multiplying memory bandwidth. This occurs because sharding model weights allows multiple GPUs to access memory in parallel, reducing bottlenecks that a single GPU might encounter.
However, it requires high-bandwidth interconnects between each GPU, like NVLink or InfiniBand, to minimize overhead from the increased communication costs.
Pipeline parallelism
Problem: Model exceeds multi-GPU capacity
For extremely large models (e.g., DeepSeek R1, Llama 3.1 405B), a single node may not suffice. Pipeline parallelism shards models across nodes, each handling specific contiguous model layers.
How it works
- Each GPU loads and processes a distinct set of layers.
- Send/Receive Operations: Intermediate activations are transmitted between GPUs as computation progresses.
This results in lower communication overhead compared to tensor parallelism since data transfer occurs once per pipeline stage.
Pipeline Parallelism reduces memory constraints across GPUs but does not inherently decrease inference latency as tensor parallelism does. To mitigate throughput inefficiencies, vLLM incorporates advanced pipeline scheduling, ensuring that all GPUs remain active by optimizing micro-batch execution.
Combining tensor parallelism and pipeline parallelism
As a general rule of thumb, think of the applications of parallelism like this:
- Use pipeline parallelism across nodes and tensor parallelism within nodes when interconnects are slow.
- If interconnects are efficient (e.g., NVLink, InfiniBand), tensor parallelism can extend across nodes.
- Combining both techniques intelligently reduces unnecessary communication overhead and maximizes GPU utilization.
Performance scaling and memory effects
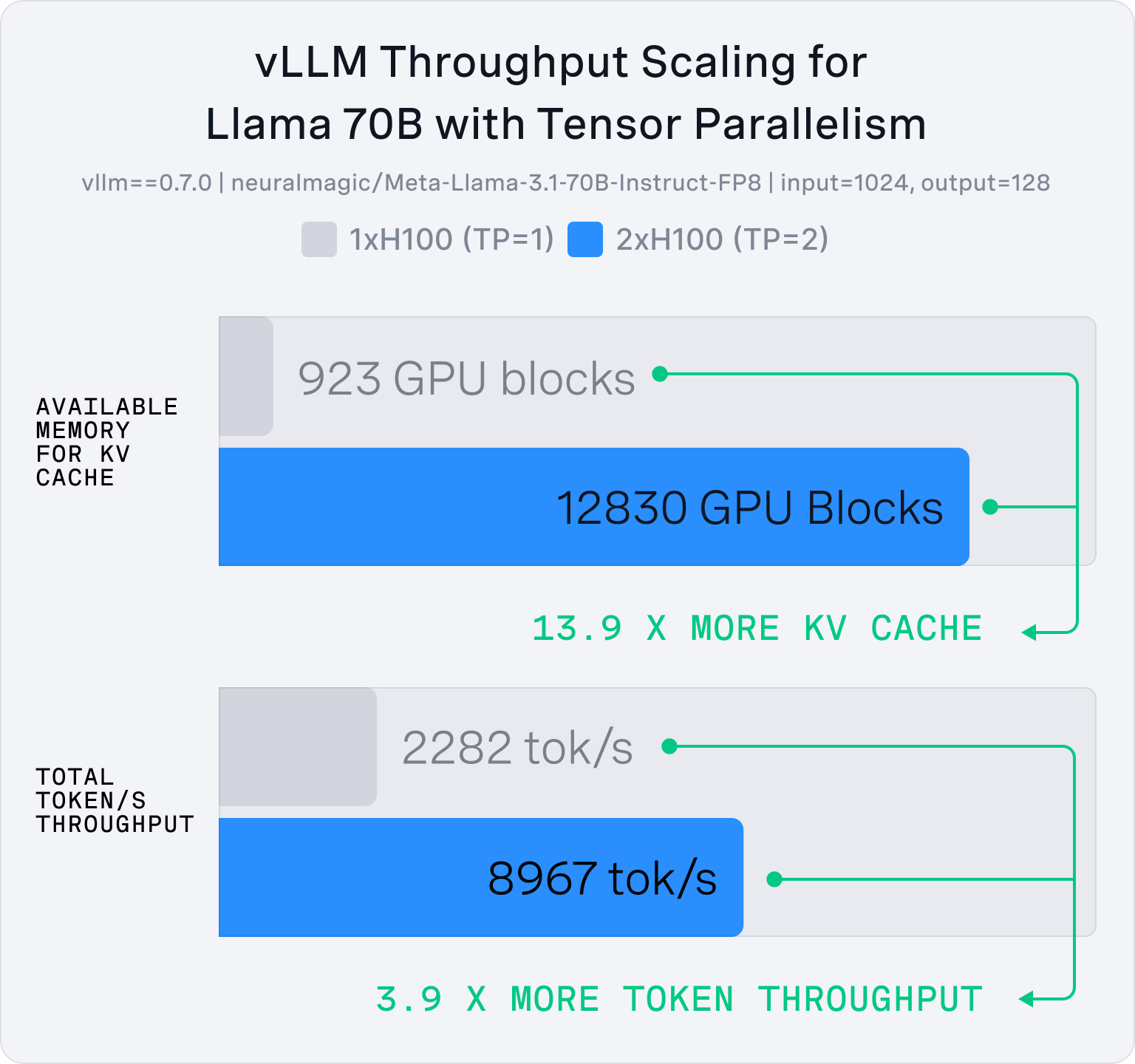
While the basic principles of parallelization suggest linear scaling, in practice, the performance improvements can be super-linear due to memory effects. With either tensor parallelism or pipeline parallelism, throughput improvements can arise in non-obvious ways due to the memory available for KV Cache increasing super-linearly.
This super-linear scaling effect occurs because larger caches allow for larger batch sizes for processing more requests in parallel and better memory locality, resulting in improved GPU utilization beyond what might be expected from simply adding more compute resources. In Figure 4, you can see between TP=1 and TP=2, we are able to increase the amount of KV Cache blocks by 13.9x which allows us to observe 3.9x more token throughput—much more than the linear 2x we would expect from using 2 GPUs instead of 1.
Further reading
For readers interested in diving deeper into the techniques and systems that influenced vLLM's design:
- Megatron-LM (Shoeybi et al., 2019) introduces the foundational techniques for model parallelism in large language models
- Orca (Yu et al., 2022) presents an alternative approach to distributed serving using iteration-level scheduling
- DeepSpeed and FasterTransformer provide complementary perspectives on optimizing transformer inference
Conclusion
Serving large models efficiently requires a combination of Tensor Parallelism, Pipeline Parallelism, and performance optimizations like Chunked Prefill. vLLM enables scalable inference by leveraging these techniques while ensuring adaptability across different hardware accelerators. As we continue to enhance vLLM, staying informed about new developments such as Mixture of Experts (MoE) and expanded quantization support will be crucial for optimizing AI workloads.
Last updated: March 26, 2025