The idea for writing this article came about after a conversation with colleagues in the architect community reporting the difficulty of implementing a distributed transaction solution. The complaints were basically due to the complexity of implementing all the components necessary to deal with standards such as Saga, for example.
It is important to note that it is not the purpose of this article to make a comparison between distributed transaction handling models, especially the Saga pattern. Likewise, this article should not be taken as a criticism of the Saga pattern or the non-recommendation of its adoption.
My father was an excellent auto mechanic, and one of the things he taught us was that "to deal with every screw there is an appropriate tool." To paraphrase a more famous saying that warns of the danger that when we are convinced that a hammer is the best tool, we treat everything as if it were a nail.
Saga and other models for handling distributed transactions have their advantages and disadvantages. Knowing each model and standard well is essential for its proper adoption or adaptation. It is essential that the terms and requirements of the business are properly raised and clarified so that a decision on which approach to adopt, as well as which technology, is more successful and actually solves the business problem.
Why not use Jakarta EJB for distributed transactions?
Back to the conversation with my colleagues. After a few minutes of discussion, the question arose: "Why not use Jakarta Enterprise Beans (EJB) for distributed transactions?"
The answer was something extremely curious and revealing. The architectural team replied with clarity and serenity: "We didn't even think about it, since we don't hear about it anymore nowadays in the world of microservices."
This is a natural consequence of the famous waves of technology. New trends appear, new patterns, and new models, and they bring with them an avalanche of articles and blogs that eventually dominate the debate and in a way monopolize discussions about architectural decisions or which technologies to adopt to develop a new solution. In some cases, they force many teams to change the technology stack, without any need from the business. Naturally, it is necessary to evaluate and take the advantages that new technologies and methodologies bring us. What is sought is a balance between the temptation to adopt something that is hyped and the need to adopt something because it brings a real advantage to the business.
First, let's contextualize the world of enterprise applications a little and then we will demonstrate how using the good old stable EJB it was possible to solve this problem in an elegant and simplified way, taking advantage of all the potential and ease offered by the application server.
Enterprise applications
I wouldn't dare define exactly what enterprise applications are. Indeed, several definitions can be found in academic articles, blogs, and articles on specialized websites without mentioning companies that provide business management consultancy services.
However, we can agree on some elementary factors:
- These applications are essential for the corporation to function.
- They play a fundamental role in business strategy.
- They must be:
- Secure
- Resilient
- Reliable
- Stable
- (The list can be extensive…)
We can see that when we talk about enterprise applications we are not talking about "Hello World" style solutions, applications that require continuous "improvements" or "testing" platforms.
These are solutions that normally took years to become stable and adapt to the company's business. And even more so, they must remain flexible so that they can at least keep up with changes in the business environment.
During the computerization process of companies, it was an absolutely natural movement that these applications emerged to solve a problem in the accounting sector and a few years later the same application managed the warehouse in addition to controlling entrances to the company building.
With the improvement in our understanding of software engineering and technological advances, the way in which these applications are developed has evolved significantly.
Microservices, nanoservices, macroservices, anysizeservices, and distributed transactions
In this "new" model of applications (explaining in a very simplified way) is based on separate, decoupled, and desirably independent parts, it is necessary to adopt practices and strategies to deal with distributed transactions. One of the most widely used is the Saga pattern.
Although it is a highly scalable and stable model, the Saga pattern is often used in contexts where its full potential is not used and in many cases is not even needed. One big advantage of the Saga pattern is its support for long-lived and decoupled transactions. However, the pattern is now being applied in scenarios that do not even make use of this type of strategy. As expected, after investing time, effort and money the end result is often frustrating as very little is achieved when using a solution that delivers much more than expected. This often results in unfair criticism and negative opinions about the pattern that have nothing to do with a mistaken or at least ill-informed decision.
One of the most common scenarios is related to the concept of Online Transaction Processing (OLTP). This model assumes that all actors involved in a transaction are active and functional. An OLTP transaction is processed and terminated immediately, or almost, since all members of the transaction are able to process or abort the executing operation.
Let's take the example of e-commerce platforms that process transactions for buying and selling products and services online. They must handle a high volume of purchase transactions, managing inventory, processing payments, and providing order confirmations to customers in real-time (or near real-time). It is essential to respect the fundamental properties set out in the atomicity, consistency, isolation, and durability (ACID) model. This is because many applications that work in this model seek for strong consistency and are composed of services that assume that they are active while the solution is working. With this premise it is possible to work with direct calls between these services and thus obtain the result immediately.
What does EE mean?
The EE of the Jakarta specification stands for Enterprise Edition. Jakarta EE provided a robust platform for distributed transactions, allowing to create dynamic web applications and incorporating features like security, scalability, component management, and concurrency, to name a few.
It was the Java community's answer to problems faced by enterprise applications. As mentioned in the introduction to this article, these problems already existed, whether to a lesser or greater extent, but there had been concerns and needs for many years.
The first version of Java EE was released in 1999 and already addressed many of the problems we continue to face today. From the beginning, the purpose of the Java EE specification, now Jakarta EE, was to provide a platform that could solve many of the problems faced by enterprise applications and offer a range of resources and services that could be consumed by applications in a transparent way.
This idea drove the multiplication and emergence of famous application servers.
In the enterprise Java world, these servers needed to comply with at least one specification and according to the specification management committee, it was established that a certain degree of backwards compatibility should be respected.
This is an issue that divides opinions to this day, because some see an advantage in reusing projects that have already been implemented and that have consumed a lot of money from companies. After all, we are talking about applications that survive for decades.
For others, it is a disadvantage because a lot of effort is invested in implementing backward compatibility with very old versions and this consumes time and effort that could be invested in new functionalities and resources, as well as making servers more difficult to manage and consuming more resources.
Because it is a specification, the intention has always been that applications developed in accordance with a specification could be deployed on any application server that complies with that specification.
The example solution
Instead of going straight to the code and demonstrating the solution, I made a point of contextualizing a little about the technology that we will use to solve the problem. As good history teachers say: "Knowing the past should help us not make the same mistakes in the future."
To demonstrate, we will create three distinct services: A, B, and C. Each service has a connection to a separate database and is deployed on a different application server, thus simulating a very common task distribution scenario.
Our goal is to guarantee that a transaction initiated by service A will respect the ACID criteria when failures occur in services A, B, or C. The execution order will be A->B->C. Lastly, we will prove that even after processing C, if there is an error in A, the entire transaction must be undone. All this in a transparent way for the application. See Figure 1.
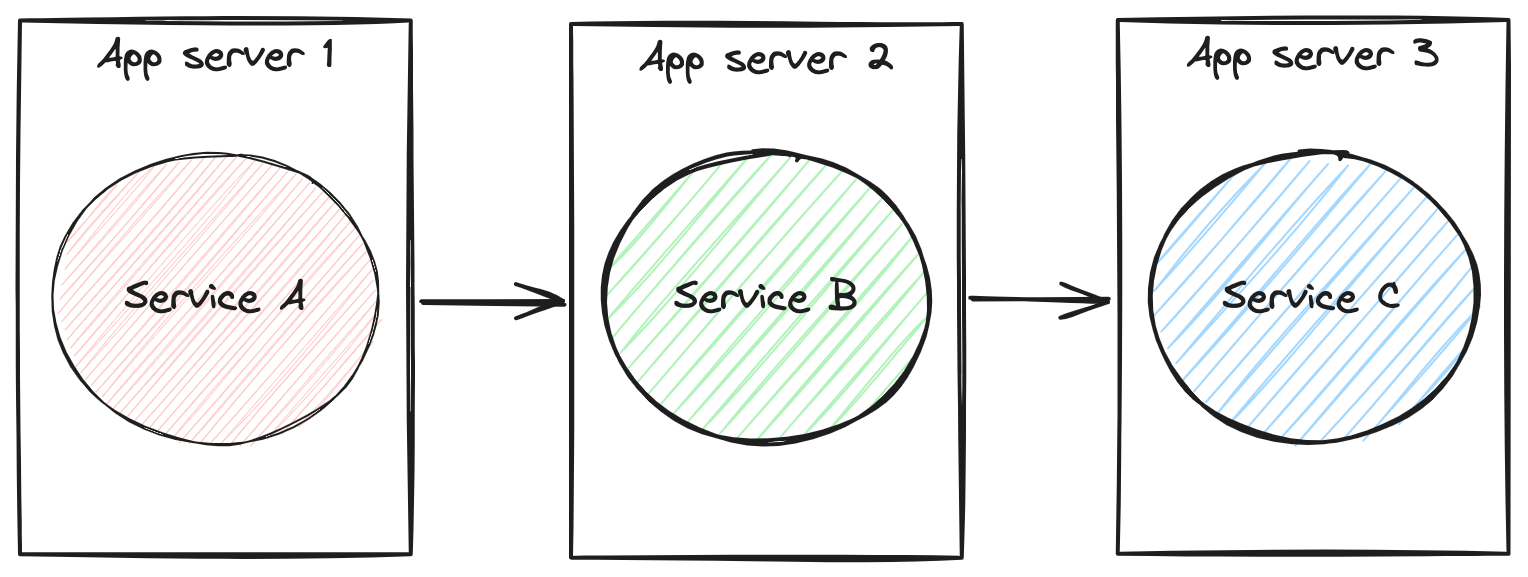
Let's go to the example.
Explaining the project
This is the basic structure of our example project:
├── service-api
├── service-a
├── service-b
├── service-c
├── service-utilsThis is a typical multi-module maven project consisting of three web applications and two support projects.
service-api represents a project with the APIs of the services that will be shared. Both clients and servers know the services' API. Clients need the API to create remote instances while service providers implement the interface defined by the API.
The code snippet below demonstrates theRemoteServiceBinterface which is consumed by service-a and implemented by service-b:package com.redhat; import com.redhat.exception.BusinessException; public interface RemoteServiceB { String DEFAULT_BEAN_NAME = RemoteServiceB.class.getSimpleName() + "Bean"; String ping(); Long createRegistry(String txtId); Long failOnC(String uuid) throws BusinessException; }
Figure 2 depicts the remote interface between client and server.
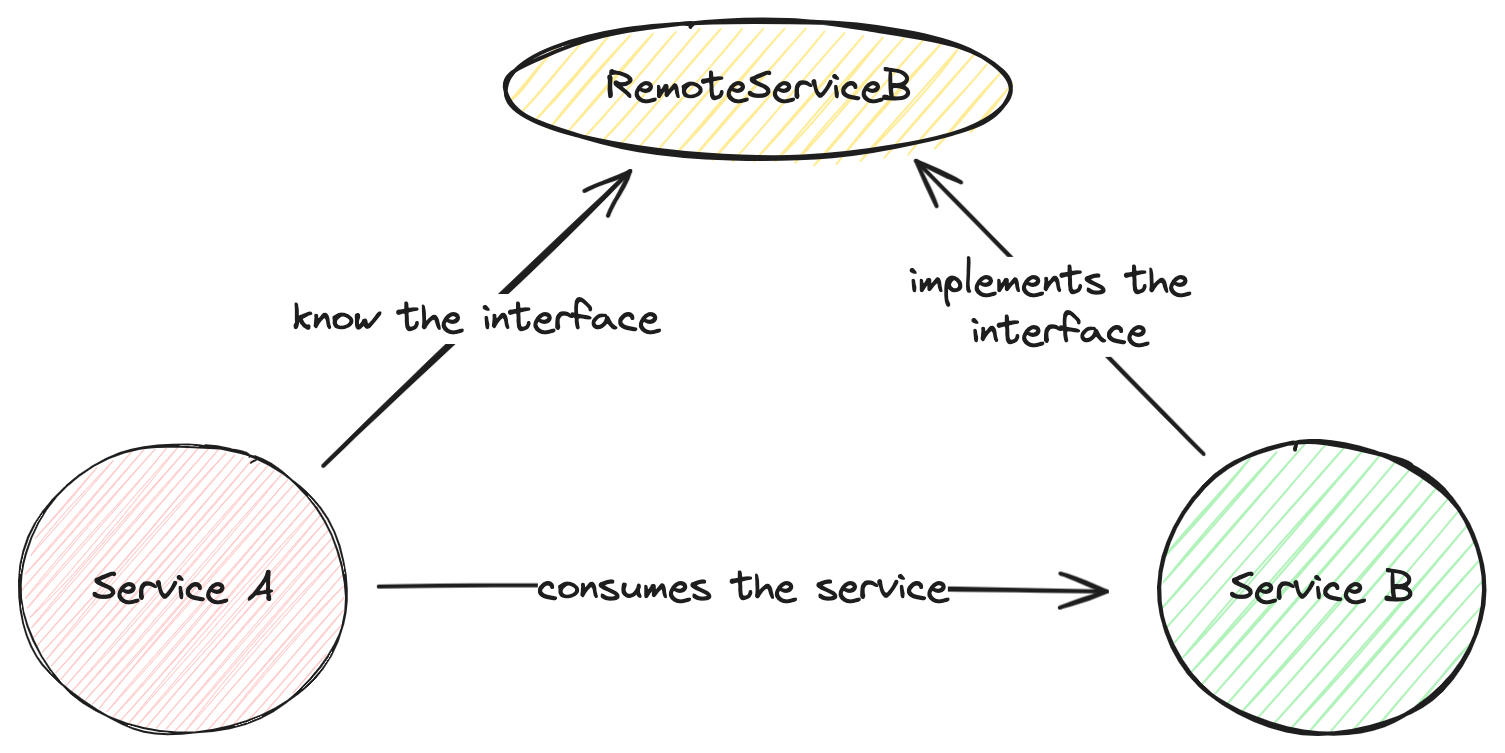
- service-a represents the service that will be the gateway to test requests. It is a web application that exposes a Rest API and consumes Remote EJB services with and without transactional context. It is important to mention that this application does not perform the role of a transaction orchestrator. We simply chose this service as the initiator of operations. There is nothing in the code that addresses orchestration requirements. Although it consumes and uses EJBs, we make use of the web profile as it is also capable of using EJBs. It has its own database and manages a simple entity that we call a registry. The registry id is obtained from service-b. Service-a only knows about service-b. Service-a generates a transaction identifier so that we can trace the result.
- service-b performs the role of a simple service for saving and retrieving registry in its own database. It is the service responsible for assigning an identifier to the registry. Receives requests from service-a and consumes service-c. Service-a sends the transaction identifier so that all services reference the same transaction. It is important to mention that the transaction identifier has no relationship with the transactional context or with application server functionalities. It is simply a string field in the registry entity generated from a UUID.
- service-c plays the role of another service in the transaction chain. It receives the transaction identifier (a simple UUID) and the registry identifier from service-b and saves the record in its local database.
- service-utils offers auxiliary functions and methods to avoid code duplication and promote reuse. One of the functions is to obtain an instance of a remote EJB in a transparent way for the application.
Figure 3 depicts a diagram of the basic operation of the example application.
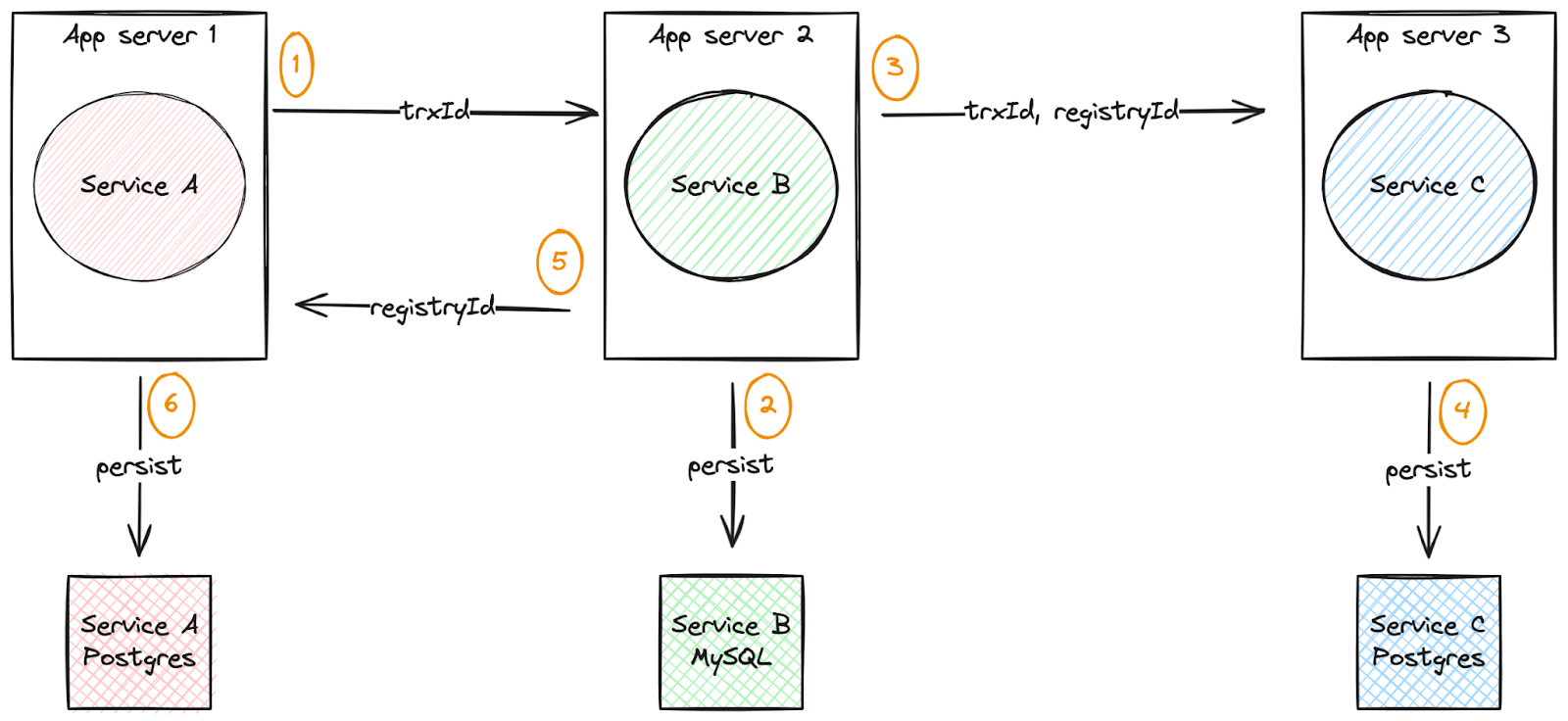
- service-a receives the rest request, generates an identifier for the transaction (
trxId) and sends it to service-b. - service-b creates a registry instance with the transaction identifier (
trxId) and saves the registry in the local database. The registry identifier (registryId) is an auto-incrementing field in the service-b mysql local database. - service-b invokes operation in service-c passing the transaction identifier (
trxId) and the registry identifier (registryId) as parameters. - service-c creates a registry instance and saves it in its own local postgres database.
- service-b returns the identifier of the registry created for service-a.
- service-a creates a registry instance and assigns the identifier received from service-b. Saves the registry to the local postgres database.
The role of the database in distributed transactions
In order to guarantee the atomicity of database operations, we are using the two phase commit pattern. In this model, the database plays a fundamental role in preparing and then consolidating the transaction state. Postgresql allows us to configure the database in a very simple way, simply by entering some parameters when starting the database instance. MySQL does not require any additional configuration to take advantage of this feature.
We’re using the max_prepared_transactions parameter during postgres startup to enable this feature. In order to demonstrate that the transaction is managed by the application server, we are using a mix of postgres and MySQL servers, both managed transparently by the application server.
The role of the application server in distributed transactions
As mentioned earlier, application servers offer a number of features and functionalities for applications. We will make use of some of these resources:
- Database connection management:
- It is the server's responsibility to manage connections to the database and make use of advanced features such as connection pool recreation and exception translation, to mention the least. The server exposes a Java Naming and Directory Interface (JNDI) resource and that's all the application needs to know. In an environment where a single application server is shared by several applications, instead of allowing each application to make connections to a database, the application server itself takes care of these connections and performs maintenance tasks, thus preventing applications from having to deal with these responsibilities.
- Transaction management:
- WildFly, as well as other application servers that support Jakarta EE specifications, offer a number of features for managing transactions. In this way, it is possible to configure an application server that will guarantee transactional behavior between all applications hosted on it.
- Therefore, our applications do not need to perform practically any management over the process of finalizing or aborting a transaction.
According to the EJB specification, it is the responsibility of the application server to ensure that a transaction initiated in service-a, which is running on App server A, is extended to service-b, which is running on App server B, and likewise to the service-c that is running on the server C. All this in a transparent way for the application.
Below is an example of how we configure server A to obtain EJB instances running on server B. The instructions make use of the management client jboss-cli:
/subsystem=transactions:write-attribute(name=node-identifier,value=service-a)
/subsystem=transactions:write-attribute(name=recovery-listener,value=true)
:write-attribute(name=name,value=service-a)
/subsystem=elytron/authentication-configuration=ejb-user:add(authentication-name=wildfly, authorization-name=wildfly, credential-reference={clear-text=R3dH4t1!}, realm="ApplicationRealm", sasl-mechanism-selector="DIGEST-MD5")
/subsystem=elytron/authentication-context=ejb-context:add(match-rules=[{authentication-configuration=ejb-user}])
/socket-binding-group=standard-sockets/remote-destination-outbound-socket-binding=remote-ejb-service-b:add(host=localhost, port=8180)
/subsystem=remoting/remote-outbound-connection=remote-ejb-service-b-connection:add(outbound-socket-binding-ref=remote-ejb-service-b, authentication-context=ejb-context)
/subsystem=remoting/remote-outbound-connection=remote-ejb-service-b-connection/property=SASL_POLICY_NOANONYMOUS:add(value=false)
/subsystem=remoting/remote-outbound-connection=remote-ejb-service-b-connection/property=SSL_ENABLED:add(value=false)
/subsystem=remoting/remote-outbound-connection=remote-ejb-service-b-connection/property=SASL_DISALLOWED_MECHANISMS:add(value=JBOSS-LOCAL-USER)The links in the references below provide detailed information on how to configure WildFly servers for the mentioned configurations.
Accessing and testing the apps
The application source code can be accessed here. The README.md file has detailed information on how to replicate the environment used for testing.
A possible configuration to demonstrate our applications working would be the configuration of six machines, real or virtual, being:
- 3 machines for the databases.
- 3 machines for the services.
To simplify things, we will use an environment based on containers and we will manage them using Podman compose.
As an alternative to installing WildFly on a host, we chose to use a container instance containing WildFly and the service already deployed. We use the Galleon tool that allows us to create a customized application server version for our application.
Each service instance has been created and is published in this container repository.
Below is the docker-compose.yml file that we will use to start all services and the respective databases.
docker-compose.yml:
services:
serviceadb:
image: postgres:16-alpine
container_name: postgres-service-a
hostname: postgres-service-a
command: postgres -c 'max_connections=300' -c 'max_prepared_transactions=150'
ports:
- 15432:5432
environment:
- TZ=Europe/Madrid
- POSTGRES_DB=service
- POSTGRES_USER=wildfly
- POSTGRES_PASSWORD=password
servicebdb:
image: quay.io/demo-ejb-wildfly-xa/mysql-service-b:latest
container_name: mysql-service-b
hostname: mysql-service-b
ports:
- 3306:3306
environment:
- TZ=Europe/Madrid
- MYSQL_DATABASE=service
- MYSQL_USER=wildfly
- MYSQL_PASSWORD=password
- MYSQL_ROOT_PASSWORD=password
servicecdb:
image: postgres:16-alpine
container_name: postgres-service-c
hostname: postgres-service-c
command: postgres -c 'max_connections=300' -c 'max_prepared_transactions=150'
ports:
- 15434:5432
environment:
- TZ=Europe/Madrid
- POSTGRES_DB=service
- POSTGRES_USER=wildfly
- POSTGRES_PASSWORD=password
servicea:
image: quay.io/demo-ejb-wildfly-xa/service-a:latest
container_name: service-a
hostname: service-a
ports:
- 8080:8080
environment:
- TZ=Europe/Madrid
depends_on:
- serviceadb
serviceb:
image: quay.io/demo-ejb-wildfly-xa/service-b:latest
container_name: service-b
hostname: service-b
ports:
- 8180:8080
environment:
- TZ=Europe/Madrid
depends_on:
- servicebdb
servicec:
image: quay.io/demo-ejb-wildfly-xa/service-c:latest
container_name: service-c
hostname: service-c
ports:
- 8280:8080
environment:
- TZ=Europe/Madrid
depends_on:
- servicecdbWe start the environment using the podman compose up command.
The test scenarios
Once we have our environment up and running we will run some test scenarios.
Happy path flow
The first will be the happy path, that is, the flow where all services execute successfully and no expected and predictable errors occur.
First, let's ensure that service-a can communicate with service-b, which can also communicate with service-c:
╰─❯ curl -s -w '\n\nResponse Code: %{response_code}\n' -X GET http://localhost:8080/api/remote
Pong from com.redhat.servicea.service.LocalService host: service-a/10.89.0.122, jboss node name: service-a
Pong from com.redhat.serviceb.service.RemoteServiceBBean host: service-b/10.89.0.123, jboss node name: service-b
Pong from com.redhat.servicec.service.RemoteServiceCBean host: service-c/10.89.0.124, jboss node name: service-cNow, let's create a registry in each of the services by calling the REST endpoint of service-a:
╰─❯ curl -s -w '\n\nResponse Code: %{response_code}\n' -X POST http://localhost:8080/api/process-all
The transaction 89c7c7f8-15e8-4679-9890-b7f37402901f was concluded with the Id 1
Response Code: 201We can make sure that services are working by making a call to each service's REST endpoint:
╰─❯ curl -s -X GET http://localhost:8080/api/listAll | jq .
[
{
"id": 1,
"info": "Registry created after service B",
"opDate": "2024-05-02T08:25:01.014982",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8180/api/listAll | jq .
[
{
"id": 1,
"info": "Service B entity info",
"opDate": "2024-05-02T08:25:00.814476",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8280/api/listAll | jq .
[
{
"id": 1,
"info": "Service C entity info",
"opDate": "2024-05-02T08:25:00.940941",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]Last service failed
Figure 4 depicts a scenario in which the failure occurs in the last service.
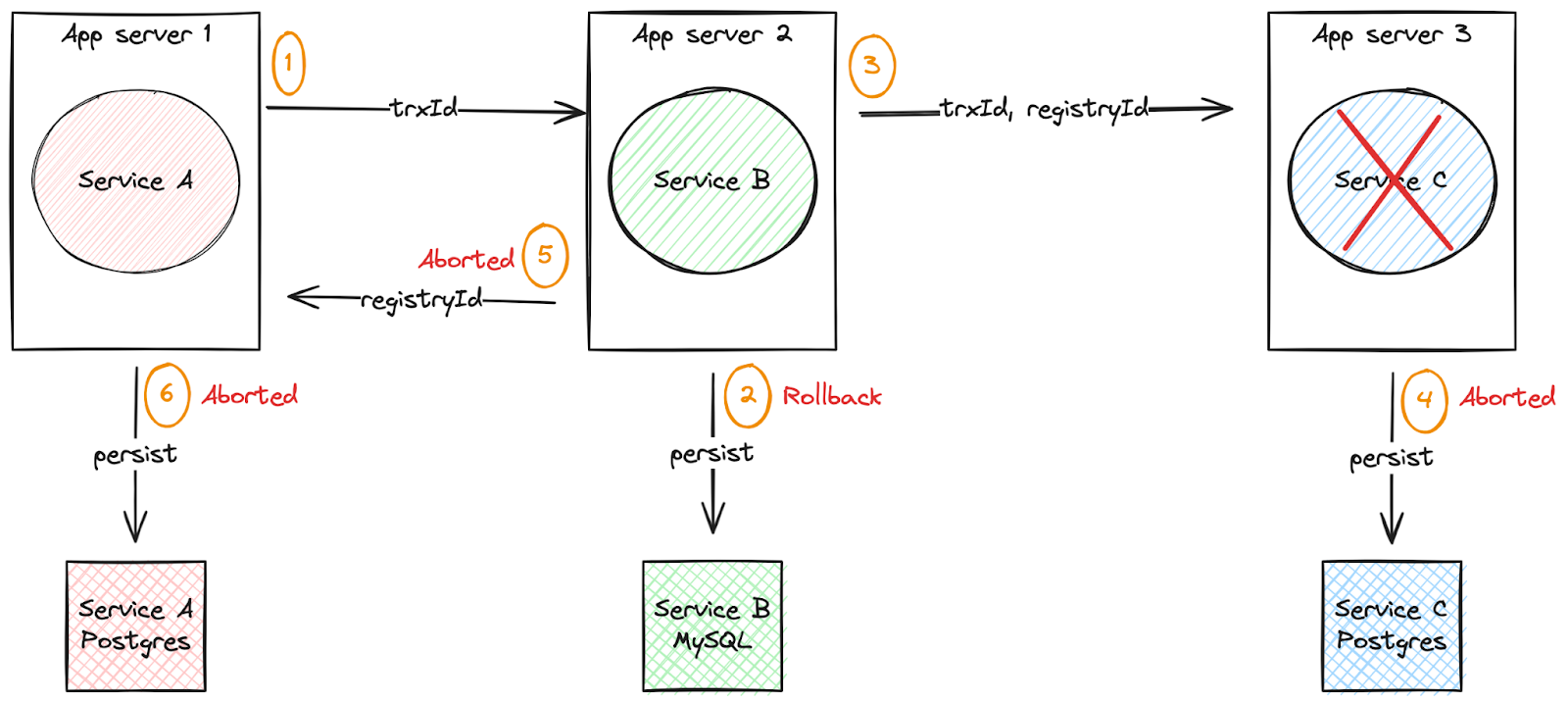
In this scenario, let's force an exception in service-c and prove that:
- Step 4 should not be performed.
- Step 2 must be reversed.
- Step 5 and 6 should not be performed.
See below:
╰─❯ curl -s -w '\n\nResponse Code: %{response_code}\n' -X POST http://localhost:8080/api/failOnC
Service C raise an Exception, trxId: 3fe0116b-54cf-4a77-918b-6a29109d23a8
Response Code: 500The code snippet below shows part of the code that forces an error in service-c:
public class RemoteServiceCBean implements RemoteServiceC ...
@TransactionAttribute(TransactionAttributeType.REQUIRED)
@Logged
@Override
public void raiseError(Long id, String txtId) throws BusinessException {
createRegistry(id, txtId);
throw new BusinessException("Service C raise an Exception",txtId);
}
...As expected, when we repeat the query for registries in the services, it is not expected that service-a or service-b or service-c will have a new registry in its database:
╰─❯ curl -s -X GET http://localhost:8080/api/listAll | jq .
[
{
"id": 1,
"info": "Registry created after service B",
"opDate": "2024-05-02T08:25:01.014982",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8180/api/listAll | jq .
[
{
"id": 1,
"info": "Service B entity info",
"opDate": "2024-05-02T08:25:00.814476",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8280/api/listAll | jq .
[
{
"id": 1,
"info": "Service C entity info",
"opDate": "2024-05-02T08:25:00.940941",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]This is exactly the expected result. When an error occurs in one of the transaction participants, the entire transaction must be canceled. This objective is achieved through the management of the transaction carried out by the application server, that is, completely transparent to the application.
First service failure
Figure 5 depicts a scenario where the failure occurs in the first service.
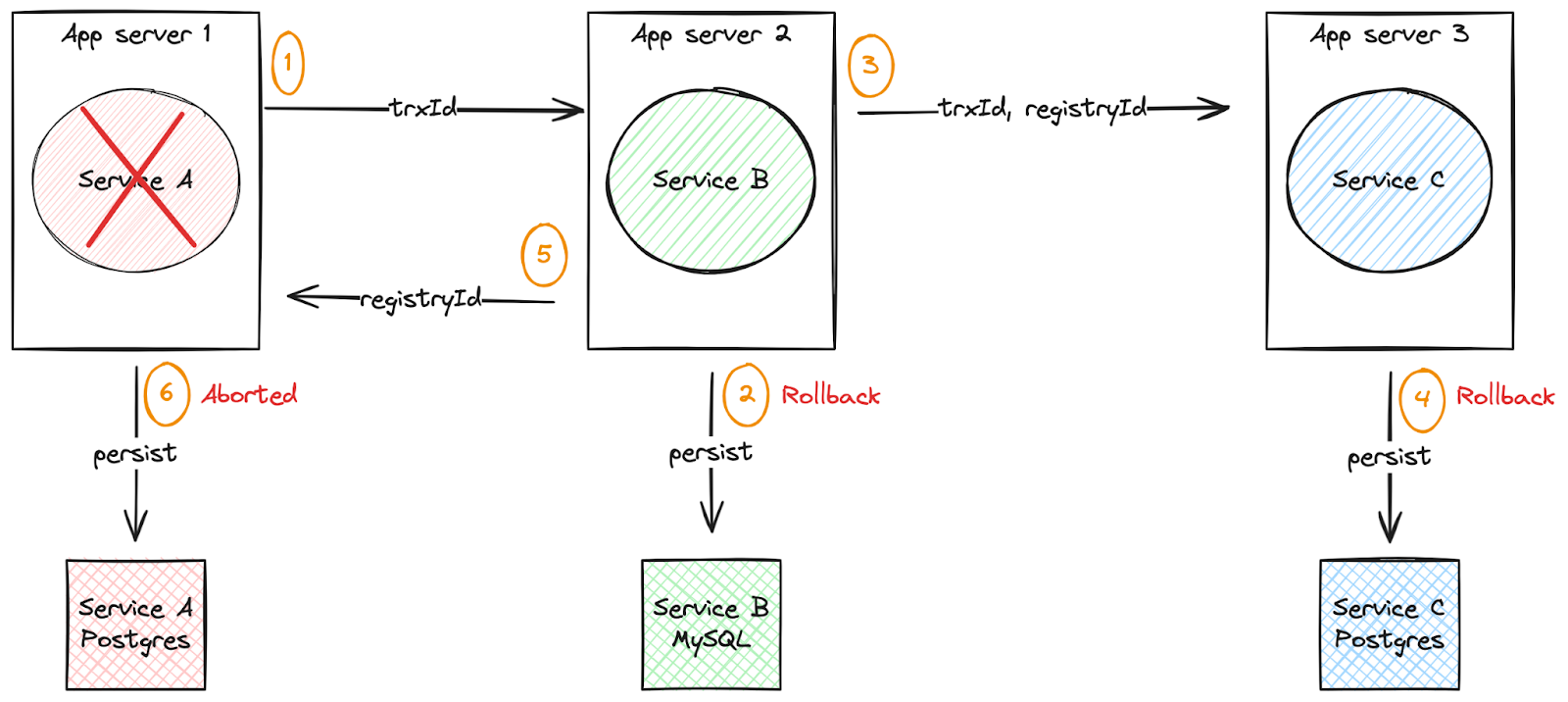
Another scenario for dealing with distributed transactions is dealing with errors and failures occurring in the service that initiated the transaction. In our example, we will force an error in service-a after the transaction has been executed in service-b and service-c.
The expected behavior is that:
- The persistence of the record in step 2 is undone.
- The persistence of the record in step 4 is undone.
- Record persistence in step 6 is aborted.
- No new records should be saved to any local database.
See below:
╰─❯ curl -s -w '\n\nResponse Code: %{response_code}\n' -X POST http://localhost:8080/api/failOnAafterBandC
This transaction should not be commited, trxId: 4a859089-9fbb-4c59-8faa-ea0c6943ba11
Response Code: 500Again, let's run a query on each service and check that no new registry were inserted into the local database:
╰─❯ curl -s -X GET http://localhost:8080/api/listAll | jq .
[
{
"id": 1,
"info": "Registry created after service B",
"opDate": "2024-05-02T08:25:01.014982",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8180/api/listAll | jq .
[
{
"id": 1,
"info": "Service B entity info",
"opDate": "2024-05-02T08:25:00.814476",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]
╰─❯ curl -s -X GET http://localhost:8280/api/listAll | jq .
[
{
"id": 1,
"info": "Service C entity info",
"opDate": "2024-05-02T08:25:00.940941",
"trxId": "89c7c7f8-15e8-4679-9890-b7f37402901f"
}
]We can do a check by repeating the happy path, that is, creating a new record in each of the services:
╰─❯ curl -s -w '\n\nResponse Code: %{response_code}\n' -X POST http://localhost:8080/api/process-all
The transaction 677b49cc-8739-4420-8f4b-c68b1fd51328 was concluded with the Id 4
Response Code: 201Note that the registry code generated was number 4. Remembering that the registry identifier created in the "Last service failed" scenario was number 1. This difference is due to the two intentional failures we tested. The registry identifier number is obtained from a sequence in the service-b database. This way, each time a transaction is carried out in the database, this number is increased by one. Even if the transaction is rolled back, the value of the sequence does not go back, thus proving the rollback operation performed in the database.
Considerations
The design of the solution above took into account a scenario, which despite being common, may not be the case for many projects.
We only work with the Java platform, and what's more, we are using an implementation of Jakarta Enterprise Beans, also known as EJB. In addition to working by combining transactions, each service is also capable of executing its actions completely independently, further favoring the reuse and portability of the solution.
The listed solution follows the premise of high data consistency and that all communications are made point-to-point, with no room for asynchronism. For a more polyglot and more flexible and event-driven implementation, we recommend that the reader check the saga pattern. However, we suggest that the reader only use it when you really need it, otherwise you will only accumulate frustration and end up with the feeling that you made a great effort and did not reap the due results.
Conclusion
There are many needs in the world of enterprise applications. Over the years, several solutions for these needs have been created and approved by the community. The Jakarta EE specification has a rich repertoire of features and functionality ready to be consumed by enterprise applications.
Knowing the business needs well helps to make a decision on which technological solution to adopt to solve these needs. Through this article we demonstrated that only via configuration on the application server and in a transparent way for the application we were able to solve a recurring problem in distributed applications. It's easy to forget about more traditional solutions when new technologies emerge and dominate the debate and flood our minds.
Red Hat offers a productized version of WildFly called Red Hat JBoss Enterprise Application Platform, or simply JBoss EAP. JBoss EAP version 8 was released on February 5th using WildFly 28 as a base with full support for the Jakarta EE 10 specification.
We encourage you to learn more about other capabilities offered by the Jakarta EE 10 specification and reuse proven and stable solutions that have been helping companies over several years. As demonstrated in this new version of the Jakarta EE specification, these technologies remain extremely relevant today and are far from being considered obsolete.
References
- Jakarta EE EJB XA Demo
- Red Hat JBoss Enterprise Application Platform
- WildFly
- WildFly Developer Guide
- WildFly Admin guide: Command Line Interface
- WildFly docs: ejb-txn-remote-call quickstart
- WildFly docs: Galleon Provisioning Guide
- Jakarta EE Web Profile 10
- Jakarta Enterprise Beans 4.0
- Article: Distributed transaction patterns for microservices compared
- Martin Fowler: Two-Phase Commit
- PostgreSQL docs: Two-Phase Transactions
- Microservices.io: Pattern: Saga
- Podman Desktop: Working with Compose
- Quay.io