Red Hat OpenShift Service on AWS (ROSA) is a turn-key and performant solution to run managed Red Hat OpenShift on Amazon Web Services (AWS). It lets users to focus more on their applications and less on the infrastructure or platform it runs on, helping drive developer innovation.
Ensuring that OpenShift is performant and scalable is a core tenant of the OpenShift Performance and Scale team at Red Hat. Prior to its release (and still to this day), ROSA undergoes a vast array of performance and scale testing to ensure that it delivers industry leading performance. These tests run the gamut from control plane and data path focus, to upgrades, to network performance. These tests have been used to help measure and better the performance of “classic” ROSA, but what happens when we move to hosted control planes?
What are hosted control planes?
Hosted control planes (HCPs) is a new deployment model for ROSA, delivering an innovative way to run the OpenShift control plane as hosted control planes with the power of the HyperShift open source project.
This deployment model allows the control plane pods to be run separately from the rest of the cluster and packed onto a single OpenShift management cluster (MC) which is managed by Red Hat and totally transparent to the user. From a customer point of view, you receive a more application optimized focus, faster deployment time, and a better value proposition as you are only paying a flat fee instead of running and managing the control plane when compared to classic ROSA. This is just the tip of the iceberg that ROSA with HCP provides (for additional information, give the announcement blog post a read).
Performance and scalability’s role
While ROSA with HCP is a great step forward, it was not without a lot of toil from countless folks from a wide range of teams. During the development of ROSA with HCP, the Red Hat OpenShift Performance and Scale team collaborated heavily cross-functionally for the early testing and successful general availability of hosted control planes. The team both developed new tools and leveraged existing tools that provided scalable and consistent testing options, crafted test cases optimized for managed service environments, performed end-to-end testing of the infrastructure for accurate capacity planning, and pushed the hosted control plane environment to its limits. All this was done to ensure that our customers have the best possible experience on ROSA with HCPs from day 1.
The right tool for the job
There has long since been a saying to "use the right tool for the job." If you are hanging a photo on a wall, you might need a hammer. If you are cutting a log, you might need a saw. At the core of our tooling is HCP-Burner and Kube-burner, two performance and scale test orchestration tools.
HCP-Burner was created as a wrapper to automate create-use-destroy of OpenShift clusters on different managed platforms like ROSA and Azure Red Hat OpenShift, and specifically HCP environments. Through the use of this tool we are able to spin up hundreds of HCPs, run a designated workload on them, and index their results to our ElasticSearch environment for storage, retrieval, and subsequent analysis. This gives us a consistent way to measure the usage of the HCP environment as well as track key performance indicators (KPIs) such as installation times, cluster utilization, and more.
In conjunction with HCP-Burner we make heavy use of Kube-burner. Kube-burner is a Kubernetes performance and test orchestration toolset that provides an easy way to create a large number of intertwined objects, measure KPIs specific to the test, and alert on important metrics. For HCP testing, we actively used Kube-burner to generate and churn varying types and degrees of load on our HCPs. To this end, a targeted managed OpenShift platform test was crafted with actual customer usage in mind.
Testing
To ensure a stable and performant environment, the team established a list of KPIs, as earlier noted. Some of these key items and their results are discussed below.
Hosted control plane ready time
One of the key tenets of HCPs is their faster installation times compared to classic or traditional OpenShift clusters. We wanted to devise a test to measure our performance on that promise. Before getting into the nuts and bolts of ready time, lets take a moment to understand the potential states of an HCP when installing and what ready means for the purposes of these tests.
HCP lifecycle states:
- Waiting: Normally seen immediately following an installation request and generally lasting only a few moments while the cluster service makes some checks and placement decisions.
- Validating: Following the waiting state, validating occurs when access to resources is being confirmed in the customer’s AWS environment.
- Installing: Installing is where most of the time is spent leading up to an HCP being ready.
- Ready: Ready state ensures that the Kubernetes API server is up and running, and access has been established but provisioning HCP worker nodes may still be in progress.
- Error: When an HCP encounters an issue during any of the regular states it can end up in an error state
Knowing these potential states allows us to accurately track the time spent from when a user requests a cluster up through it being declared as ready. With this knowledge we can determine if any particular state exceeds its expected runtime as well as identify targets for potential improvement.
One such test that shows this is the 320 hosted cluster test. During this test, 320 hosted clusters were requested in 4 batches of 80. Each HCP install request had a 1 minute delay before requesting the next. Once the HCPs were up, they would begin running a cluster density style workload via Kube-burner based on the HCP specific installation parameters. After this, the clusters would be cleaned up in the same fashion as they were installed.
Let's analyze the durations of the HCP preflight checks, which cover the time spent in the waiting and validating states during the pre-provisioning phase. The hosted cluster will be in a waiting state while the cluster service picks the best suitable management cluster to host them. Subsequently, it transitions to the validating state to ensure that the underlay network on the customer's AWS environment is appropriately configured to handle HCP functionality. This involves deploying test instances and conducting checks to validate connectivity back to the management cluster.
Looking at the waiting time for all these clusters, we can quickly see a stair-step style pattern (Figure 1). This is concerning as it implies that with increased cluster count comes increased wait times. While these times are still relatively short (28 seconds at worst) they grew by approximately 2.5 times on average from the first batch to the last. This growth trend is particularly concerning as it can lead to large delays as cluster count increases.
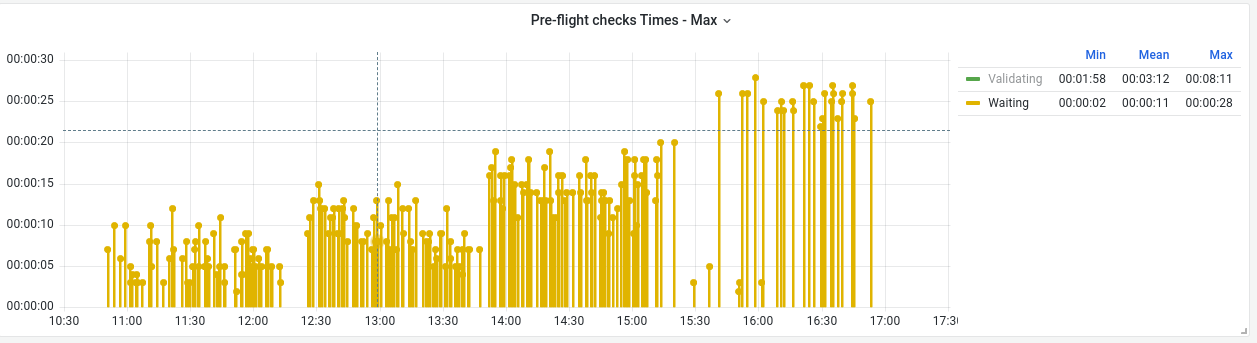
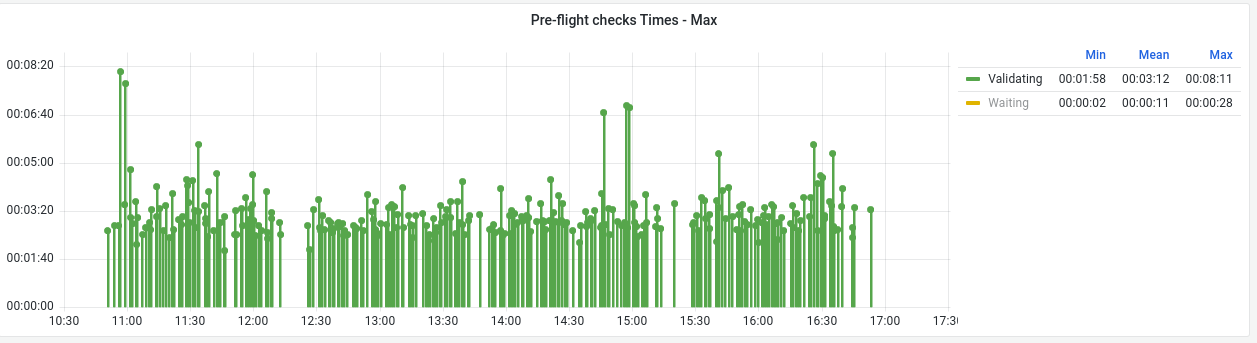
Turning our attention to the validating time, there is a much more consistent average across the 320 installations (Figure 2). That said, we can see obvious outliers in the data where the time spent would be 2 to 3 times the average. In more extreme cases in other tests this state was seen to peak at over 20 minutes! That is longer than the entire installation should normally take. This was investigated further and after adjusting the retry interval and timeout of network verifier script, which validates the underlay AWS networking we were able to get to a much more consistent and less exaggerated worst case timings.
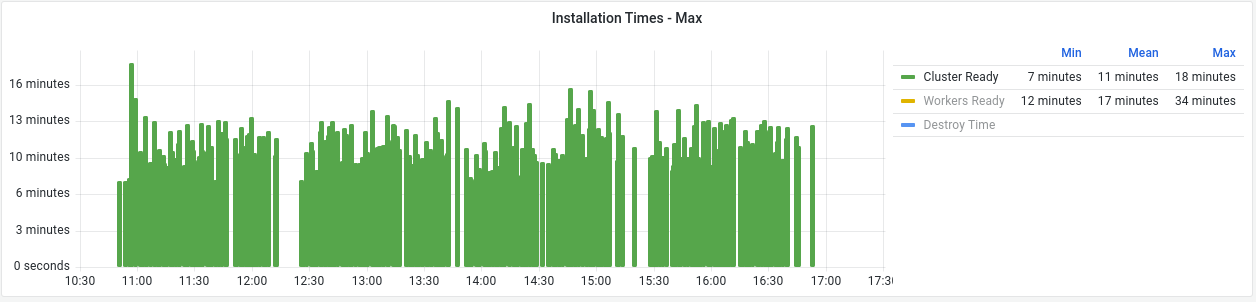
Lastly, looking at these times from a cluster ready perspective (i.e., the cumulative time up to reaching the ready state,) the installation timings are fairly consistent as shown in Figure 3. However, we can see the impact of the spikes from the validating state early on in the test. In these cases it increases total cluster ready time by multiple minutes above the average.
Ensuring an optimal management cluster size
As stated earlier, HyperShift utilizes the concept of management clusters where the hosted control planes reside on its worker nodes. Ensuring that these worker nodes are sufficiently utilized but not overburdened can mean walking a tightrope. Breaking down the problem into two parts, we have to ensure that there is capacity for current and upcoming HCPs while simultaneously being prudent not to waste resources.
If there is not enough capacity, then we can potentially have 2 problems. First and most obvious, existing HCPs will suffer from reduced performance or potentially fail. Utilizing the managed OCP Kube-burner tests we mapped out the expected usage of the HCP pods by measuring the resource usage of control plane pods under load. With that knowledge it is fairly simple to determine an ideal average size of worker instances based on expected cpu and memory consumption.
This would be perfect if it were not for the "noisy neighbor" problem. Not all clusters are used or sized similarly. Some are CI systems, some are build systems, some host elaborate websites, and so on. These application differences result in different usage patterns. The good news is that given the mixed environment most of the usage spikes occur at different times and on different workers. However there are always some clusters which push the limits no matter what. It’s here where we need to rely on 2 things. First, by appropriately setting the pods requests and limits we can curb how aggressive these clusters can be and ensure the space for their workloads. Secondly, having an appropriate mechanism to either isolate and/or migrate the noisy HCP to a larger instance size to allow for its needed usage and growth.
After solving for existing clusters we can take a look at the second problem: new installations. If there is not sufficient capacity to place an HCP when the installation request comes in, then it will take longer than normal as the management cluster will need to provision additional worker instances for the required capacity. Knowing the required resources to run an HCP’s pods, we can utilize the Cluster Proportional Autoscaler (CPA) to ensure a buffer of space for number N HCPs.
The CPA spins up lower PriorityClass pods as temporary placeholders to reserve compute resources. These pod replicas can be controlled by CPA config patterns, functioning as basic pause pods that are evicted when higher PriorityClass pods require resources, similar to an operating system cache. HCP pods promptly utilize available compute resources without delay to host control plane services, while the placeholder pods either migrate to different workers or prompt CPA to engage new workers. This approach ensures that the MC maintains sufficient reserved resources for HCP pods in anticipation of demand.
For example, if we wanted to size the management cluster in way such that there is space for up to 2 new HCPs, we could do something like the example below. We pre-calculate the total CPU core and memory requirements for an HCP per AvailabilityZone and adjust the size of the placeholder pods accordingly. In the example below, each placeholder pod is configured to request 2 CPUs and 7 GiB of memory resources per AZ, allowing three replicas to reserve resources for one HC. These pod replicas scale up or down based on the CPA configuration, which supports two patterns: linear and ladder. The advantage of the ladder configuration lies in its ability to scale up the placeholder pod replicas at different rates in response to the management cluster size. Moreover, it can be configured to scale down when the MC doesn't anticipate new HCP requests, which is not available with linear configuration.
Note that in this example we are focusing on the number of cores to reserve capacity for new HCPs and stating that 48 cores MC will reserve a buffer for 1 HCP. Additionally, we assume that each MC worker has 16 cores. The ladder configuration ensures a buffer space for 1 HCP when the MC is new and has 3 workers. It reserves resources for 2 HCP when the cluster is operating near ~50% capacity and reduces its allocation when the MC is fully utilized.
ladder: |-
{
"coresToReplicas":
[
[ 48, 3 ], # MC size >= 3 workers, reserves 1 HCP resource
[ 192, 6 ], # MC size >= 12 workers, reserves 2 HCP resource
[ 432, 0 ] # MC size >= 27 workers, 0 buffer
]
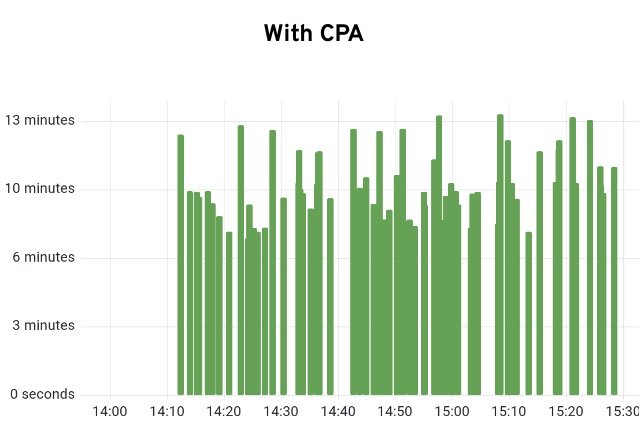
}Using the CPA gives us a good amount of flexibility and greatly smoothes out the installation times. Figure 4 shows the 80th percentile (P80) installation times with and without using the CPA. Using the P80 reduces the outliers in the other stages while still giving a fairly accurate picture of what is going on. As is clearly seen, the P80 installing time goes from 14m:34s down to 8m:49s. That's a huge improvement of about 5m:45s.
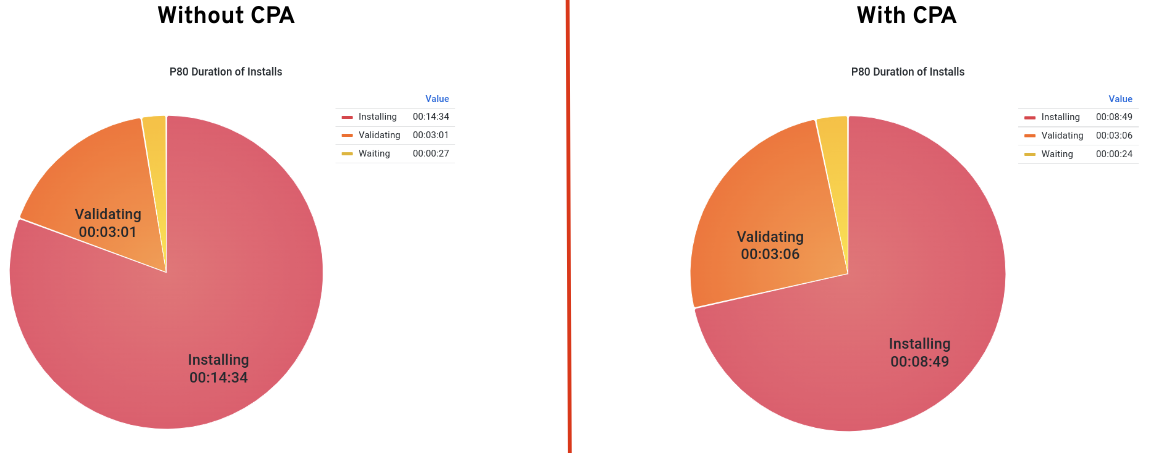
Looking at the individual cluster ready times, we can see a similar picture (Figure 5).
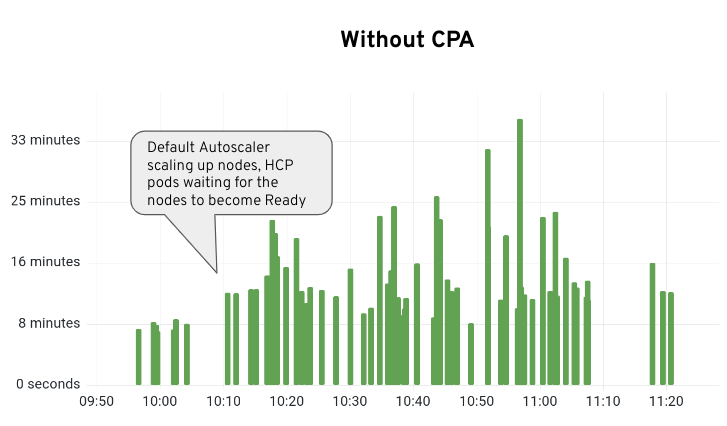
Without the CPA we can clearly see the gaps and rising install times that occur as the normal OpenShift Autoscaler attempts to catch up. But with a roughly 5 minute installation time per new worker, the delay builds and builds. Looking at it with the CPA it is much smoother (Figure 6). There will always be some variance but we eliminate the large spikes seen previously.
Individual HCP performance
Based on the above test cases, and the optimizations arising out of those findings, the management clusters can now sustain the load required. None of that matters, however, if the individual HCP with which the customer interfaces and runs their workloads on doesn’t perform or scale on par with a classic ROSA cluster. For this, we used our existing toolset and compared the results to ROSA Classic. These tests consisted of control and data plane workloads.
The data path was exercised using ingress-perf and k8s-netperf tools. ingress-perf has a wealth of options which we utilize to target ingress/router testing. Configuration options include the type of benchmark termination, number of connections, number of samples, duration, concurrency, and etc. We benchmarked edge, http, passthrough, and re-encrypt terminations to ensure their throughput and latency is acceptable.
Similarly, k8s-netperf is used to ensure coverage of TCP and UDP throughput and latency. These tests are run with message sizes ranging from 64 to 8192 in 1 or 2 pairs. They are then executed in scenarios that test node-to-node, pod-to-pod, and pod-to-pod via a service. These networking tests help to ensure appropriate performance of the data plane.
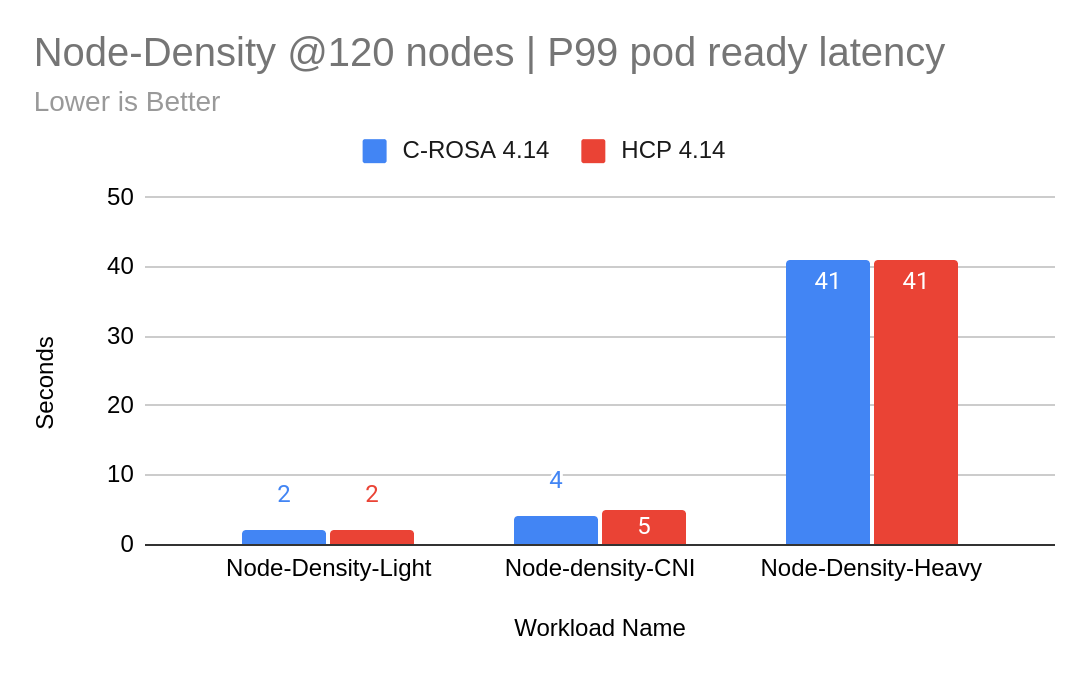
The control plane was tested in multiple scenarios utilizing Kube-burner's different testing options. First up was a trio of node density tests that measure the 99th percentile of pod ready latency, which is a KPI to represent the time taken for a pod to go from scheduling to all container running. Node Density Light creates a maximum number of sleep pods on each of the HCPs’ worker nodes. Node Density CNI spawns replicas of a webserver and a curl pod has a startup probe that reflects network flow programming latency by curling the webserver via a ServiceIP. Lastly, Node Density Heavy creates replicas of a database and client application. We can see that at 120 HCP workers the latency is nearly identical to that of classic ROSA (Figure 7).
Similarly, Cluster Density (v2) is a density focused test that creates pods, builds, secrets, routes, and more across the entire cluster. A percentage of these resources are then churned (deleted and recreated) at set intervals to more accurately represent a live environment where changes actively occur. These resources put an appreciable strain on the control plane. We track and measure this control plane component resource usage as well as API and ETCD latencies to ensure components a) are not regressing in resource utilization and b) responding to queries in an appropriate amount of time. Lastly, there is an upgrade test that is executed while running the cluster density test. This is to ensure that the system can upgrade at load, as it is imperative to upgrade OpenShift to consume critical fixes and the latest and greatest features that come with each successive release..
Unearthing some unseen challenges
There will be challenges with any project. While ROSA with hosted control planes did well overall, there were still a few challenges that are worth discussing. Luckily through a close collaboration with quality engineering, development, and project management teams these were able to be resolved.
While by and large things have gone well for ROSA with hosted control planes, it has not all been roses. There have been issues along the way. Many have been minor but some have had a major impact.
HCP upgrade failures
The previously mentioned, upgrade test is where we can see one of these major issues. While running cluster density (v2) by itself passes at an expected hosted cluster size when an upgrade is executed while these objects exist we hit a critical failure. As can be seen in Figure 8 in the hosted cluster CPU and memory utilization charts, there is a massive spike of resource consumption after the control plane is upgraded due to the Kubernetes API server. The repeated gaps and new pods show that we are running out of resources (in this case memory was the main constraint) and causing the worker to run out of memory.
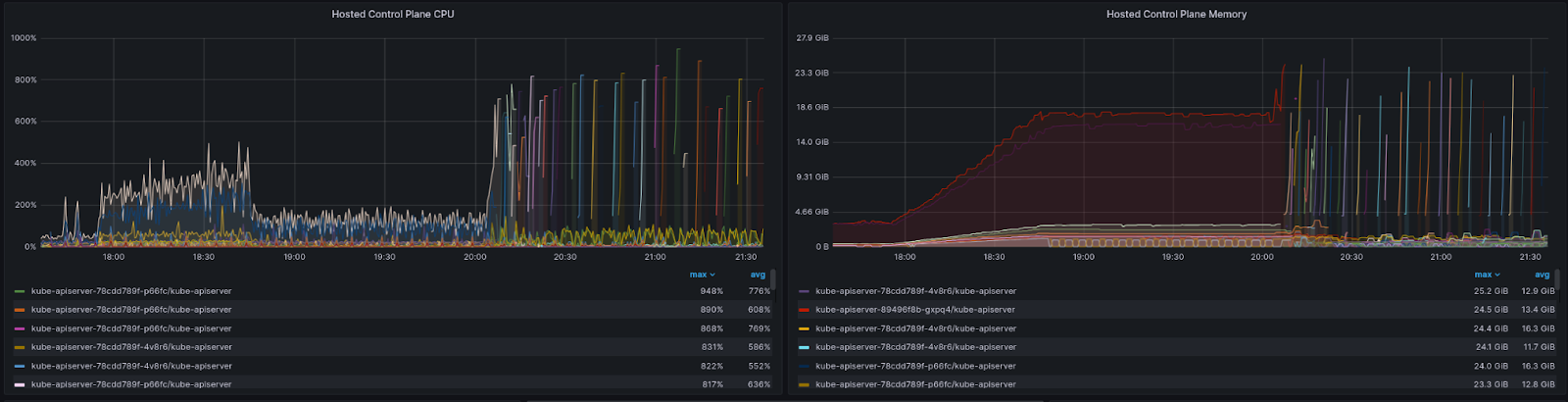
This is obviously a critical failure as upgrades need to function properly for an appropriate HCP lifecycle. The good news is that a fix is on the way. In this fix, the team implemented GOMEMLIMIT to stop the excessive heap growth of the Kubernetes API server that was a main cause of the increased consumption.
Management cluster upgrades
Another upgrade related issue was found on the management cluster, which is critical back office infrastructure that is essential for seamless operation of the HCP solution. The test consists of loading up a management cluster to its maximum number of HCPs and then upgrading the MC. HCPs are watched for timeouts and errors that may indicate more than expected outages. During this test we found that nearly half of the HCPs experienced a longer than expected kube-apiserver outage. Digging deeper we found that while the kube-apiservers were happy as a clam on the management cluster the HCP router pods were no longer “finding” their corresponding kube-apiservers. Through some great engineering work this was quickly resolved via RHSA-2023:7599
A stable and performant environment
Due to the testing done throughout the project, we were able to ensure a stable and performant environment for ROSA with HCP to customers at GA. There were bumps and bruises along the way, but today it can stand tall in its capabilities and scale. There will be ongoing continuous performance testing through automation to alleviate the risk of regressions and ensure that HCPs can meet the most demanding customer requirements.
If you are interested in trying OpenShift Service on AWS with hosted control planes, check out our quick start guide.
Last updated: June 24, 2024