Welcome to part 3 of this series on edge computing. In the previous blog, we defined edge and looked at use cases and constraints. Now let’s take a closer look at the multiple topologies of Red Hat OpenShift and where each one fits in.
Read the previous parts in the series:
- Part 1: What is edge computing and what makes it so different?
- Part 2: Red Hat Edge platforms: More options for more use cases
Overview
OpenShift brings full Kubernetes functionality to edge locations using server-class hardware. When used in conjunction with a central or public cloud environment, OpenShift can seamlessly extend your footprint (meaning your applications) out to the edge, right alongside end users or data sources. It acts as a general purpose base layer, so that developers can focus on developing, not managing infrastructure. We consider it a micro cloud at your edge locations.
Red Hat OpenShift
OpenShift is one of the most mature Kubernetes distributions. It started as a Platform as a Service (PaaS) solution for private data centers, then extended its reach to a fully-fledged application development platform across the hybrid cloud. In recent years, mainly driven by telecommunications service provider (telco) edge computing use cases around Open Radio Access Networks (ORAN), OpenShift can also be used as a Container as a Service (CaaS) solution at thousands of edge deployments.
A key strength of OpenShift is the vast and vibrant ecosystem of additional components and solutions provided by Red Hat and its partners. These can be easily added as needed using the Operator Lifecycle Manager, e.g., to add software-defined storage, database workloads, messaging middleware, etc.
A brief history of OpenShift cluster topologies
To support edge use cases, the minimum system requirements of OpenShift have been shrunk over the past few years from nine nodes to six, and then three node compact clusters. Now it can be run on a single node, dubbed single node OpenShift.-
Figure 1 shows cluster types that have been able to run OpenShift through the years to present.
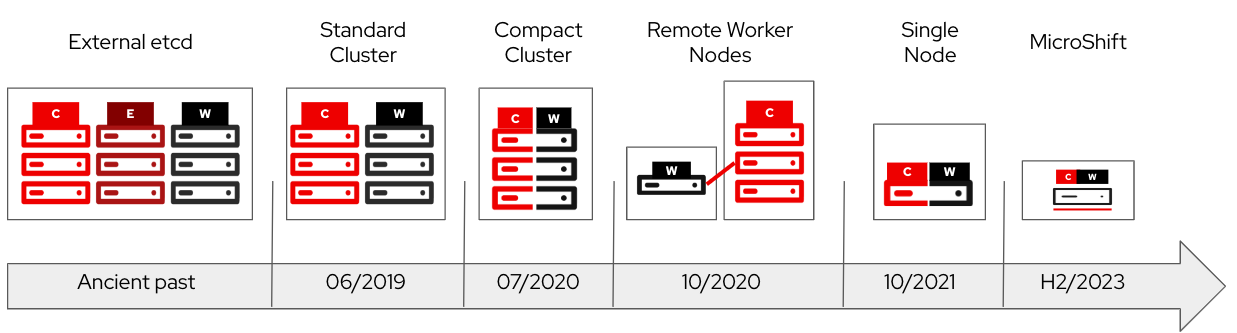
Being able to run OpenShift on single or few nodes opens up a world of possibilities for several types of use cases.
Single-node OpenShift
Single-node OpenShift is the full OpenShift experience but on a single node. Instead of Red Hat build of MicroShift, where the design approach is to start with nothing and add only what is needed for workload portability, single-node OpenShift is more like “OpenShift on a diet.” This is done by scaling down control plane components to reduce resources and make cluster capabilities optional. For example, you don’t need a web console at the edge location, if you centrally manage via Red Hat Advanced Cluster Management for Kubernetes (RHACM).
Single-node OpenShift is best used when you want the full OpenShift experience but don’t need the high availability found with multi-node. Some examples of this might be if you need to perform telco ORAN deployments, aggregate the Internet of Things (IoT) between devices, sensors, and cameras, low-orbit satellites, or being in a remote location that requires small hardware.
All of this can still be managed by the same tools used in larger-node architectures. RHACM can be used for the platform, application or policy lifecycle, while Red Hat Advanced Cluster Security for Kubernetes (RHACS) should be used to enhance your security postures for the node. Red Hat Ansible Automation Platform is another option that may be used for management, especially for surrounding components such as switches, routers, and more.
Remote worker nodes
A remote worker node is similar to a normal worker node, but is able to function with limited or interrupted network connectivity. If the connection to the control plane is lost, the workload happily continues to run and process/collect data. The trade off here is that reboots must be handled carefully during loss of control plane connectivity. This can be addressed by using Kubernetes DaemonSets to get the workload running again. To get traffic to the node and avoid complex routing, ServiceIPs or NodePorts can be used, while worker latency profiles can be employed to adjust to your environment.
Remote worker nodes are great options for environments with less than great connectivity. For example, consider a manufacturing site where there is an OpenShift cluster at the factory datacenter and the remote worker nodes are industrial PCs located at the shopfloor. Should any of the ongoing work or machinery interfere with the network connectivity, the remote worker node will still function as needed. Remote worker nodes take up very small overhead (.5 cores for the kubelet) and can still have the same management options as that of single-node OpenShift.
Multi-node OpenShift and three-node compact clusters
A three-node compact cluster is the bread and butter OpenShift for deployment. It provides resilient, high availability, cloud-like compute services at your edge locations. In combination with a software defined storage solution such as Red Hat OpenShift Data Foundation, you will be able to compute, network, and retain storage all in three standard servers (2U rack space).
Three-node clusters are solid options for anyone that needs high availability at an edge location that has a small amount of power, cooling, and rack space. One example would be retailers using a multipurpose configuration for store back rooms to operate a variety of their store function workloads. Same with single or remote worker nodes, RHACM, RHACS, and Ansible Automation Platform may all be employed on a three-node compact cluster to manage your workload needs.
Conclusion
Whether your edge locations need a small form factor, high availability, or a centralized control plane, OpenShift has a topology that can accommodate it. Best of all, no matter which option you choose, it’s all consistently managed with the same tools and processes as any other cloud or centralized OpenShift deployment. It’s just a natural extension of an open hybrid cloud environment.
